Section 02-01のノートを元に、各ブロックを関数化して検証に利用しやすい形にします。
その後、各関数を呼び出して、特徴量の有効性を検証します。
検証する特徴量は
- 最小構成(Section02-01と同じくトライアル情報のみ)
- 前走情報を使う(前走のラップタイムとギア倍率)
- オッズ情報を使う
- 前走情報とオッズ情報を使う
です。
使いそうなライブラリをインポートします。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np関数定義
前回のノートの各ブロックを関数化していきます。前回と同じなので解説は省略します。
前処理
from sklearn.preprocessing import StandardScaler
def make_learning_data(df, not_use_columns, not_use_columns_keywards):
df['race_date'] = pd.to_datetime(df['race_date'])
for i in range(6):
for col_keyward in not_use_columns_keywards:
not_use_columns.append(f'{i}_{col_keyward}')
not_use_df = df[not_use_columns]
input_df = df.drop(columns=not_use_columns)
input_df = input_df.apply(pd.to_numeric, args=('coerce',))
for i in range(6):
if f'{i}_odds' in input_df.columns:
zero_mask = input_df[f'{i}_odds'] < 1.0
input_df[f'{i}_odds'] = np.log(input_df[f'{i}_odds'])
input_df.loc[zero_mask, f'{i}_odds'] = np.nan
if 'ticket_odds' in input_df.columns:
zero_mask = input_df['ticket_odds'] < 1.0
input_df['ticket_odds'] = np.log(input_df['ticket_odds'])
input_df.loc[zero_mask, 'ticket_odds'] = np.nan
train_mask = not_use_df['race_date'] < '2023-01-01'
test_mask = not_use_df['race_date'] >= '2023-01-01'
train_input_df = input_df.loc[train_mask, :].reset_index(drop=True)
test_input_df = input_df.loc[test_mask, :].reset_index(drop=True)
categorical_columns = ['round', 'year', 'month', 'day', 'player_num', 'ticket']
scaler = StandardScaler()
train_X = pd.DataFrame(data=scaler.fit_transform(train_input_df), columns=train_input_df.columns)
test_X = pd.DataFrame(data=scaler.transform(test_input_df), columns=test_input_df.columns)
for col in categorical_columns:
train_X.loc[:, col] = train_input_df.loc[:, col].astype('int64')
test_X.loc[:, col] = test_input_df.loc[:, col].astype('int64')
train_y = not_use_df.loc[train_mask, 'ticket_hit'].reset_index(drop=True).astype('int64')
test_y = not_use_df.loc[test_mask, 'ticket_hit'].reset_index(drop=True).astype('int64')
return train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask学習
import optuna.integration.lightgbm as lgb
def learning(train_X, train_y):
#import lightgbm as lgb
params = {
'objective': 'binary',
'metric': 'binary_logloss',
'learning_rate': 0.01,
}
num_round = 10000
from sklearn.model_selection import train_test_split
lgb_train_X, lgb_valid_X, lgb_train_y, lgb_valid_y = train_test_split(train_X, train_y, test_size=0.3)
lgb_train_X = lgb_train_X.reset_index(drop=True)
lgb_valid_X = lgb_valid_X.reset_index(drop=True)
lgb_train_y = lgb_train_y.reset_index(drop=True)
lgb_valid_y = lgb_valid_y.reset_index(drop=True)
lgb_train = lgb.Dataset(lgb_train_X, lgb_train_y)
lgb_eval = lgb.Dataset(lgb_valid_X, lgb_valid_y)
# training
model = lgb.train(params, lgb_train,
num_boost_round=num_round,
valid_sets=[lgb_train, lgb_eval],
valid_names=['train', 'valid'],
callbacks=[lgb.early_stopping(stopping_rounds=10, verbose=0)]
)
return model, (lgb_train_X, lgb_train_y, lgb_valid_X, lgb_valid_y)正答率の表示
def accuracy_print(model, X, y):
accuracy = lambda a, b : np.sum(a==b)/len(a)
pred = (model.predict(X) > 0.5).astype(int)
print(f' base acc : {accuracy(np.zeros_like(y), y)}')
print(f' acc : {accuracy(pred, y)}')モデルの出力分布の表示
def print_model_p(model, train_X, train_y, test_X, test_y):
train_pred_p = model.predict(train_X)
test_pred_p = model.predict(test_X)
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(121)
plt.hist(train_pred_p[train_y==0], bins=10, label='not hit', alpha=0.5)
plt.hist(train_pred_p[train_y==1], bins=10, label='hit', alpha=0.5)
plt.legend()
plt.title('train')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(122)
plt.hist(test_pred_p[test_y==0], bins=10, label='not hit', alpha=0.5)
plt.hist(test_pred_p[test_y==1], bins=10, label='hit', alpha=0.5)
plt.legend()
plt.title('test')
plt.xlabel('pred')
plt.ylabel('y')
plt.show()使用した特徴量の表示
def print_feature_importance(model, X):
importance = pd.DataFrame(model.feature_importance(), index=X.columns, columns=['importance'])
importance = importance.sort_values(['importance'])
plt.figure(tight_layout=True, figsize=(12, 6))
plt.barh(importance.index, importance['importance'], align="center")
plt.show()利益の表示
def print_win_money(model, train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask):
train_payout = not_use_df.loc[train_mask, 'ticket_payout'].reset_index(drop=True)
test_payout = not_use_df.loc[test_mask, 'ticket_payout'].reset_index(drop=True)
train_pred = model.predict(train_X)
test_pred = model.predict(test_X)
def calc_win_money(pred, hit, payout, th=0.5):
bet = (pred > th).astype(int)
hit = hit.to_numpy()
payout = payout.to_numpy()
return_money = np.sum(bet * hit * payout)
bet_money = np.sum(bet)
win_money = return_money - bet_money
return win_money, return_money, bet_money
print(f'train win money :{calc_win_money(train_pred, train_y, train_payout, 0.5)[0]}')
print(f'test win money :{calc_win_money(test_pred, test_y, test_payout, 0.5)[0]}')
train_win_list = []
test_win_list = []
th_list = np.linspace(0.0, 1.0, 1000)
for th in th_list:
train_win_list.append(calc_win_money(train_pred, train_y, train_payout, th)[0])
test_win_list.append(calc_win_money(test_pred, test_y, test_payout, th)[0])
plt.plot(th_list, train_win_list, label='train')
plt.plot(th_list, test_win_list, label='test')
plt.legend()
plt.xlabel('th')
plt.ylabel('win money')
plt.show()学習の流れ
def analysis_columns_effect(df, not_use_columns, not_use_columns_keywards):
train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask = make_learning_data(df, not_use_columns, not_use_columns_keywards)
model, (lgb_train_X, lgb_train_y, lgb_valid_X, lgb_valid_y) = learning(train_X, train_y)
print('train')
accuracy_print(model, lgb_train_X, lgb_train_y)
print('valid')
accuracy_print(model, lgb_valid_X, lgb_valid_y)
print('test')
accuracy_print(model, test_X, test_y)
print_model_p(model, train_X, train_y, test_X, test_y)
print_feature_importance(model, train_X)
print_win_money(model, train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask)分析
最小構成(トライアル情報のみ)
最小構成は前回のノートと同じです。乱数の影響で全く同じ結果ではないことに注意してください
not_use_columns = ['race_id', 'race_date', 'ticket_odds', 'ticket_hit', 'ticket_payout']
not_use_columns_keywards = ['rank', 'time', 'odds', 'pre_rap_time', 'pre_gear_rate']
df = pd.read_pickle('/work/learning_data/learning_01_tansyo.pkl')
analysis_columns_effect(df, not_use_columns, not_use_columns_keywards)正答率
正答率は前回も述べましたが、予測しない場合のテストaccuracyが0.8314、予測器のテストaccuracyが0.8730なので、学習はできているようです。
train
base acc : 0.8243720930232558
acc : 0.8824186046511628
valid
base acc : 0.8259548611111112
acc : 0.8671875
test
base acc : 0.8314552284017933
acc : 0.873015873015873モデルの出力分布
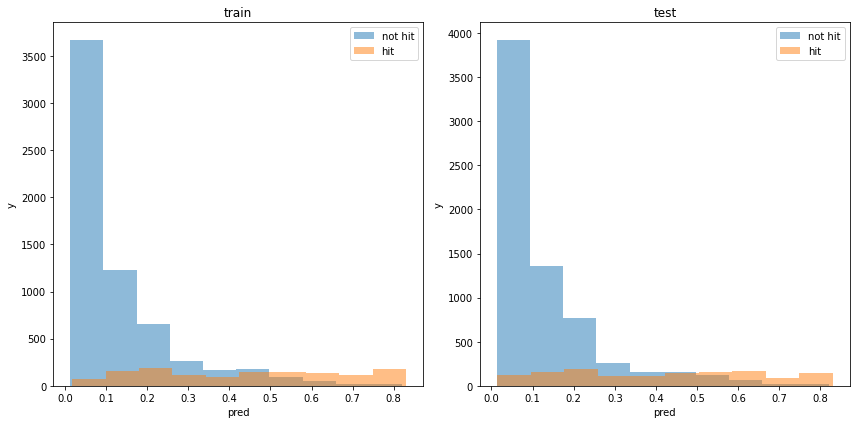
割と分類できている様に見えます。
使用した特徴量
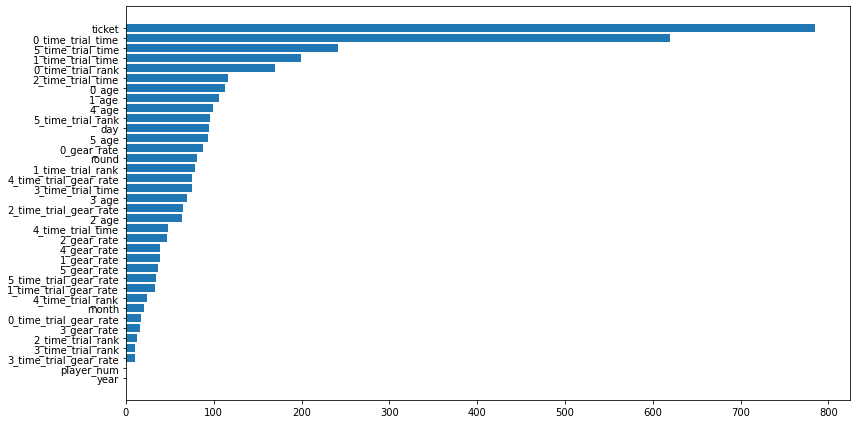
タイムトライアルデータを利用していることがわかります。というか、それ以外にチケットの判定を行う材料がないので妥当な結果です。
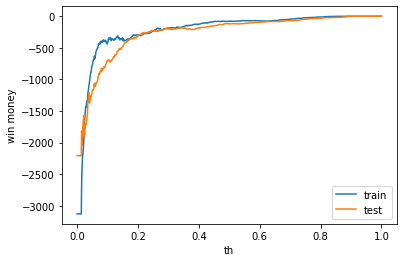
利益
学習データでも利益はでませんでした。前回学習データで利益がでたのは偶然でした。何度か試行しましたが、学習データで利益がでることは偶然のようです。また、テストデータでの利益は常にマイナスでした。
train win money :(-35.200000000000045, 719.8, 755)
test win money :(-90.30000000000007, 684.6999999999999, 775)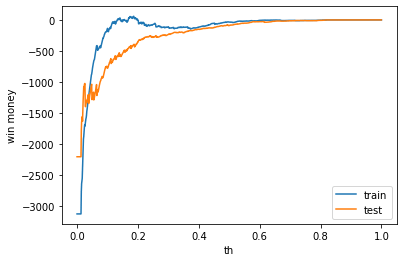
前走情報を使う
not_use_columns = ['race_id', 'race_date', 'ticket_odds', 'ticket_hit', 'ticket_payout']
not_use_columns_keywards = ['rank', 'time', 'odds']
df = pd.read_pickle('/work/learning_data/learning_01_tansyo.pkl')
analysis_columns_effect(df, not_use_columns, not_use_columns_keywards)正答率
正答率は前回も述べましたが、予測しない場合のテストaccuracyが0.8314、予測器のテストaccuracyが0.8725なので、学習はできているようです。前走情報を入れてもあまり、正答率は向上しないみたいです。
train
base acc : 0.8249302325581396
acc : 0.8930232558139535
valid
base acc : 0.8246527777777778
acc : 0.8723958333333334
test
base acc : 0.8314552284017933
acc : 0.8725312007754756モデルの出力分布
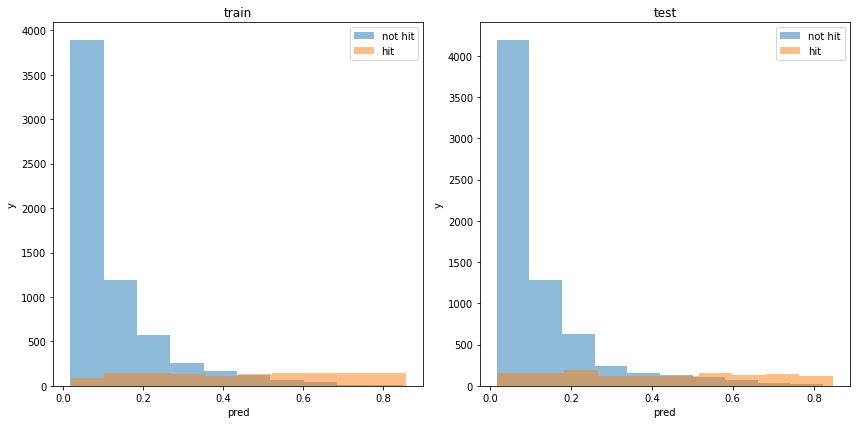
割と分類できている様に見えます。
使用した特徴量
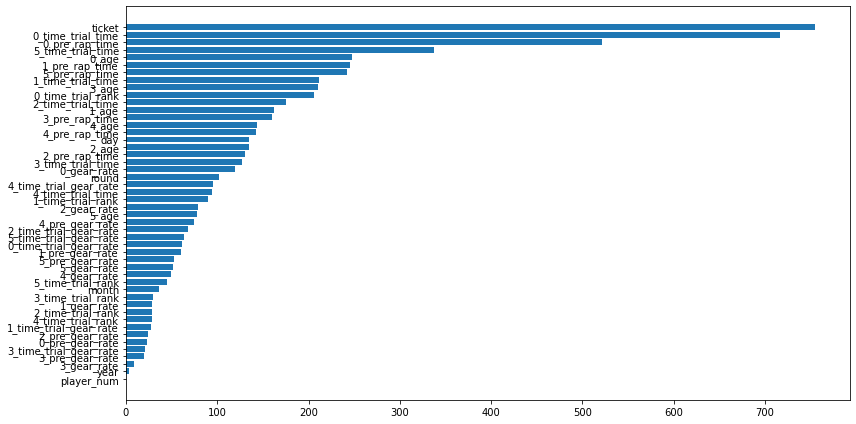
タイムトライアルデータと前走のラップタイムを利用していることがわかります。
利益
テストデータでの利益はマイナスでした。
train win money :(47.799999999999955, 829.8, 782)
test win money :(-106.39999999999998, 684.6, 791)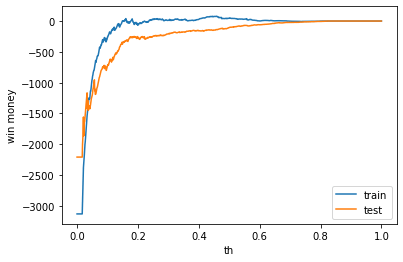
オッズ情報を使う
not_use_columns = ['race_id', 'race_date', 'ticket_odds', 'ticket_hit', 'ticket_payout']
not_use_columns_keywards = ['rank', 'time', 'pre_rap_time', 'pre_gear_rate']
df = pd.read_pickle('/work/learning_data/learning_01_tansyo.pkl')
analysis_columns_effect(df, not_use_columns, not_use_columns_keywards)正答率
正答率は前回も述べましたが、予測しない場合のテストaccuracyが0.8314、予測器のテストaccuracyが0.8834なので、学習はできているようです。
オッズを利用すると1%程度の精度向上になります。
train
base acc : 0.8254883720930233
acc : 0.8932093023255814
valid
base acc : 0.8233506944444444
acc : 0.8771701388888888
test
base acc : 0.8314552284017933
acc : 0.8834363261844178モデルの出力分布
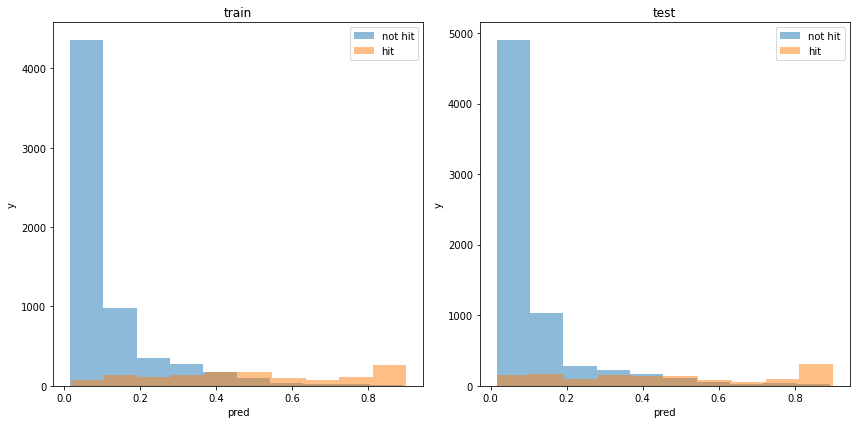
割と分類できている様に見えます。
使用した特徴量
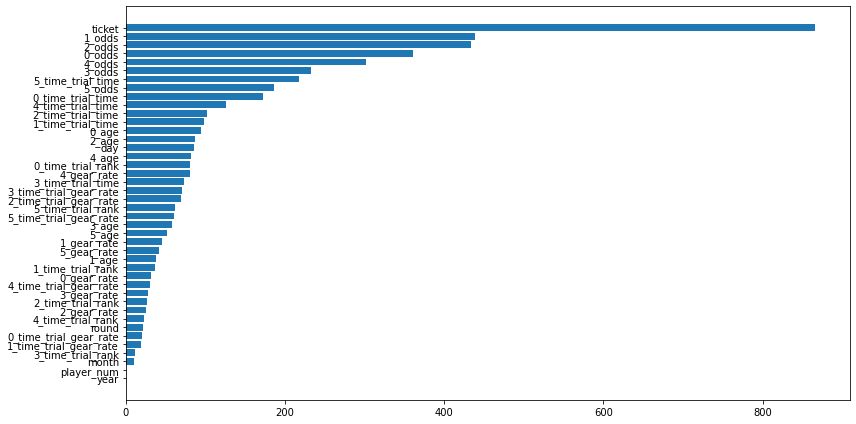
上位にオッズ情報が来ました。やはりオッズは有効な特徴量なようです。しかし、オッズは変動するため、実際のレースで使う場合には気をつけないといけません。
利益
テストデータでの利益はマイナスでした。
train win money :(-63.899999999999864, 696.1000000000001, 760)
test win money :(-127.29999999999995, 649.7, 777)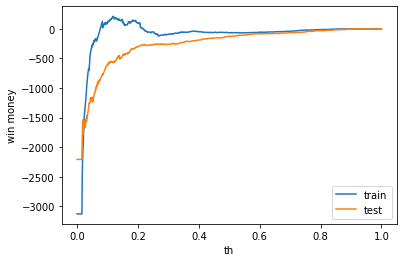
前走情報とオッズ情報を使う
not_use_columns = ['race_id', 'race_date', 'ticket_odds', 'ticket_hit', 'ticket_payout']
not_use_columns_keywards = ['rank', 'time']
df = pd.read_pickle('/work/learning_data/learning_01_tansyo.pkl')
analysis_columns_effect(df, not_use_columns, not_use_columns_keywards)正答率
正答率は前回も述べましたが、予測しない場合のテストaccuracyが0.8314、予測器のテストaccuracyが0.8842なので、学習はできているようです。今までで一番いいですが、試行によって精度にブレがあるので、注意してください。
train
base acc : 0.8282790697674418
acc : 0.8885581395348837
valid
base acc : 0.8168402777777778
acc : 0.8723958333333334
test
base acc : 0.8314552284017933
acc : 0.8842845026051133モデルの出力分布
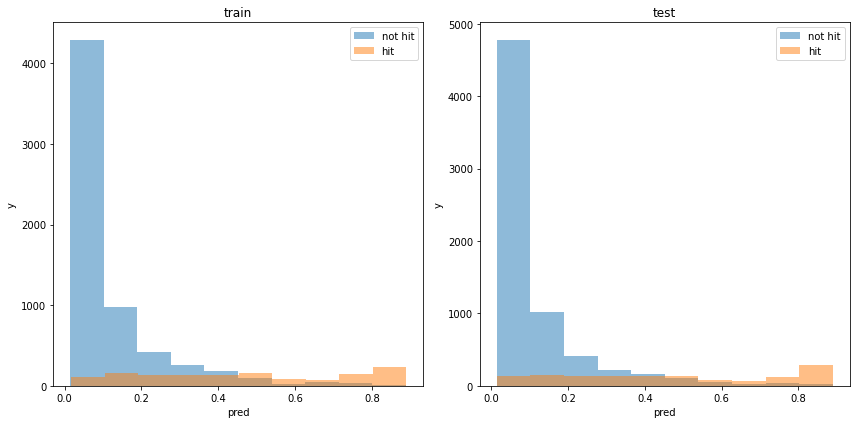
割と分類できている様に見えます。
使用した特徴量
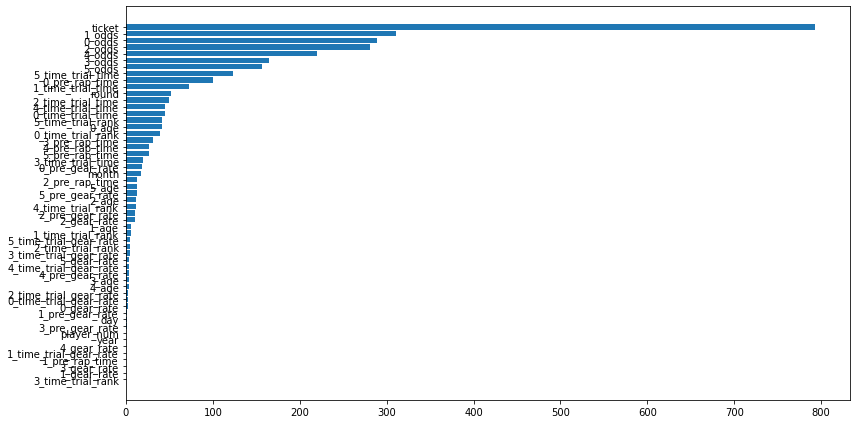
タイムトライアルデータ、前走データ、オッズデータを利用していることがわかります。
利益
テストデータでの利益はマイナスでした。
train win money :(-77.30000000000007, 646.6999999999999, 724)
test win money :(-121.10000000000002, 670.9, 792)