
前回、水増ししてオッズを利用した場合の利益を調べました。
今回は、水増しをしてオッズを利用しない場合の利益を調べます。
オッズを利用しない理由としては、次のものがあります。
- オッズ情報が不確定であるため、利用しづらい
- ため、オッズと正答率との相関が正しく取れるか不明である。
- オッズ情報をいれると、オッズ情報に頼りすぎた学習になり、オッズが適正ではないレース(PIST6のレースは単勝オッズ1.0が多々ある)に対して予測が不安定になる
検証するチケットの種類は前回と同様に
- 単勝
- 二連複
- 二連単
- 三連複
- 三連単
の5種類です。
不均衡データを均衡がとれるように水増しするので、データ数は二倍弱増えます。その分計算時間がかかります。
またこの記事では、利益の出る気がする結果が示されますが、必ず儲かることを示す結果ではないことに注意してください。
使いそうなライブラリをインポートします。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np関数定義
分析するための関数を定義していきます。
前処理
from sklearn.preprocessing import StandardScaler
def make_learning_data(df, not_use_columns, not_use_columns_keywards, ticket_type):
df['race_date'] = pd.to_datetime(df['race_date'])
if ticket_type == 'wide':
ticket_odds_df = df['ticket_odds'].str.split('\n~', expand=True).rename(columns={0:'ticket_odds_min',1:'ticket_odds_max'})
df['ticket_odds_min'] = ticket_odds_df['ticket_odds_min']
df['ticket_odds_max'] = ticket_odds_df['ticket_odds_max']
if 'ticket_odds' in not_use_columns:
not_use_columns.remove('ticket_odds')
not_use_columns.append('ticket_odds_min')
not_use_columns.append('ticket_odds_max')
#not_use_columns = ['race_id', 'race_date', 'ticket_odds', 'ticket_hit', 'ticket_payout']
#not_use_columns_keywards = ['rank', 'time']
for i in range(6):
for col_keyward in not_use_columns_keywards:
not_use_columns.append(f'{i}_{col_keyward}')
not_use_df = df[not_use_columns]
input_df = df.drop(columns=not_use_columns)
input_df = input_df.apply(pd.to_numeric, args=('coerce',))
for i in range(6):
if f'{i}_odds' in input_df.columns:
zero_mask = input_df[f'{i}_odds'] < 1.0
input_df[f'{i}_odds'] = np.log(input_df[f'{i}_odds'])
input_df.loc[zero_mask, f'{i}_odds'] = np.nan
if 'ticket_odds' in input_df.columns:
not_use_df['ticket_odds'] = input_df['ticket_odds']
zero_mask = input_df['ticket_odds'] < 1.0
input_df['ticket_odds'] = np.log(input_df['ticket_odds'])
input_df.loc[zero_mask, 'ticket_odds'] = np.nan
train_mask = not_use_df['race_date'] < '2023-01-01'
test_mask = not_use_df['race_date'] >= '2023-01-01'
train_input_df = input_df.loc[train_mask, :].reset_index(drop=True)
test_input_df = input_df.loc[test_mask, :].reset_index(drop=True)
categorical_columns = ['round', 'year', 'month', 'day', 'player_num', 'ticket']
if ticket_type != 'tansyo':
categorical_columns.remove('ticket')
for n in range(3):
col = f'ticket_{n}'
if col in input_df.columns:
categorical_columns.append(col)
scaler = StandardScaler()
train_X = pd.DataFrame(data=scaler.fit_transform(train_input_df), columns=train_input_df.columns)
test_X = pd.DataFrame(data=scaler.transform(test_input_df), columns=test_input_df.columns)水増し(Up-Sampling)
from imblearn.over_sampling import SMOTENC
from collections import Counter
def up_sampling(train_X, train_y, ticket_type):
print(f'Original dataset samples per class {Counter(train_y)}')
categorical_columns = ['round', 'year', 'month', 'day', 'player_num', 'ticket']
if ticket_type != 'tansyo':
categorical_columns.remove('ticket')
for n in range(3):
col = f'ticket_{n}'
if col in train_X.columns:
categorical_columns.append(col)
sm = SMOTENC(categorical_features=categorical_columns)
upsampling_X, upsampling_y = sm.fit_resample(train_X.fillna(0), train_y)
print(f'Resampled dataset samples per class {Counter(upsampling_y)}')
return upsampling_X, upsampling_y学習
import optuna.integration.lightgbm as lgb
def learning(train_X, train_y):
#import lightgbm as lgb
params = {
'objective': 'binary',
'metric': 'binary_logloss',
'learning_rate': 0.01, # default = 0.1
'verbose': -1
}
num_round = 10000
from sklearn.model_selection import train_test_split
lgb_train_X, lgb_valid_X, lgb_train_y, lgb_valid_y = train_test_split(train_X, train_y, test_size=0.3)
lgb_train_X = lgb_train_X.reset_index(drop=True)
lgb_valid_X = lgb_valid_X.reset_index(drop=True)
lgb_train_y = lgb_train_y.reset_index(drop=True)
lgb_valid_y = lgb_valid_y.reset_index(drop=True)
lgb_train = lgb.Dataset(lgb_train_X, lgb_train_y)
lgb_eval = lgb.Dataset(lgb_valid_X, lgb_valid_y)
# training
model = lgb.train(params, lgb_train,
num_boost_round=num_round,
valid_sets=[lgb_train, lgb_eval],
valid_names=['train', 'valid'],
callbacks=[lgb.early_stopping(stopping_rounds=10, verbose=False)],
)
return model, (lgb_train_X, lgb_train_y, lgb_valid_X, lgb_valid_y)正答率の表示
def accuracy_print(model, X, y):
accuracy = lambda a, b : np.sum(a==b)/len(a)
pred = (model.predict(X) > 0.5).astype(int)
print(f' base acc : {accuracy(np.zeros_like(y), y)}')
print(f' acc : {accuracy(pred, y)}')モデルの出力分布の表示
def print_model_p(model, train_X, train_y, test_X, test_y):
train_pred_p = model.predict(train_X)
test_pred_p = model.predict(test_X)
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(121)
plt.hist(train_pred_p[train_y==0], bins=10, label='not hit', alpha=0.5)
plt.hist(train_pred_p[train_y==1], bins=10, label='hit', alpha=0.5)
plt.legend()
plt.title('train')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(122)
plt.hist(test_pred_p[test_y==0], bins=10, label='not hit', alpha=0.5)
plt.hist(test_pred_p[test_y==1], bins=10, label='hit', alpha=0.5)
plt.legend()
plt.title('test')
plt.xlabel('pred')
plt.ylabel('y')
plt.show()使用した特徴量の表示
def print_feature_importance(model, X):
importance = pd.DataFrame(model.feature_importance(), index=X.columns, columns=['importance'])
importance = importance.sort_values(['importance'])
plt.figure(tight_layout=True, figsize=(12, 6))
plt.barh(importance.index, importance['importance'], align="center")
plt.show()利益の表示
def print_win_money(model, train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask):
train_payout = not_use_df.loc[train_mask, 'ticket_payout'].reset_index(drop=True)
test_payout = not_use_df.loc[test_mask, 'ticket_payout'].reset_index(drop=True)
train_pred = model.predict(train_X)
test_pred = model.predict(test_X)
def calc_win_money(pred, hit, payout, th=0.5):
bet = (pred > th).astype(int)
hit = hit.to_numpy()
payout = payout.to_numpy()
return_money = np.sum(bet * hit * payout)
bet_money = np.sum(bet)
win_money = return_money - bet_money
return win_money, return_money, bet_money
print(f'train win money :{calc_win_money(train_pred, train_y, train_payout, 0.5)[0]}')
print(f'test win money :{calc_win_money(test_pred, test_y, test_payout, 0.5)[0]}')
train_win_list = []
test_win_list = []
th_list = np.linspace(0.0, 1.0, 1000)
for th in th_list:
train_win_list.append(calc_win_money(train_pred, train_y, train_payout, th)[0])
test_win_list.append(calc_win_money(test_pred, test_y, test_payout, th)[0])
plt.plot(th_list, train_win_list, label='train')
plt.plot(th_list, test_win_list, label='test')
plt.legend()
plt.xlabel('th')
plt.ylabel('win money')
plt.show()学習の流れ
def analysis_columns_effect(df, not_use_columns, not_use_columns_keywards):
train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask = make_learning_data(df, not_use_columns, not_use_columns_keywards)
upsampint_X, upsampling_y = up_sampling(train_X, train_y, ticket_type)
model, (lgb_train_X, lgb_train_y, lgb_valid_X, lgb_valid_y) = learning(upsampint_X, upsampling_y)
print('train')
accuracy_print(model, lgb_train_X, lgb_train_y)
print('valid')
accuracy_print(model, lgb_valid_X, lgb_valid_y)
print('test')
accuracy_print(model, test_X, test_y)
print_model_p(model, train_X, train_y, test_X, test_y)
print_feature_importance(model, train_X)
print_win_money(model, train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask)チケットの影響を調べる関数
def analysis_ticket_effect(ticket_type):
df = pd.read_pickle(f'/work/learning_data/learning_01_{ticket_type}.pkl')
not_use_columns = ['race_id', 'race_date', 'ticket_odds', 'ticket_hit', 'ticket_payout']
not_use_columns_keywards = ['rank', 'time', 'odds']
analysis_columns_effect(df, not_use_columns, not_use_columns_keywards, ticket_type)optunaのログを簡略化
optunaのログですぎるので、表示を簡略化します。
import optuna
optuna.logging.set_verbosity(optuna.logging.WARNING)チケットの種類別の分析(オッズ情報を使わない)
単勝
analysis_ticket_effect('tansyo')正答率
特に言うことはありません。想定通りの結果でした。
lgbm train
base acc : 0.4978008345550919
acc : 0.9337994812225104
lgbm valid
base acc : 0.505130228887135
acc : 0.907392791370692
train
base acc : 0.8248469852845423
acc : 0.8788904805313191
test
base acc : 0.8314552284017933
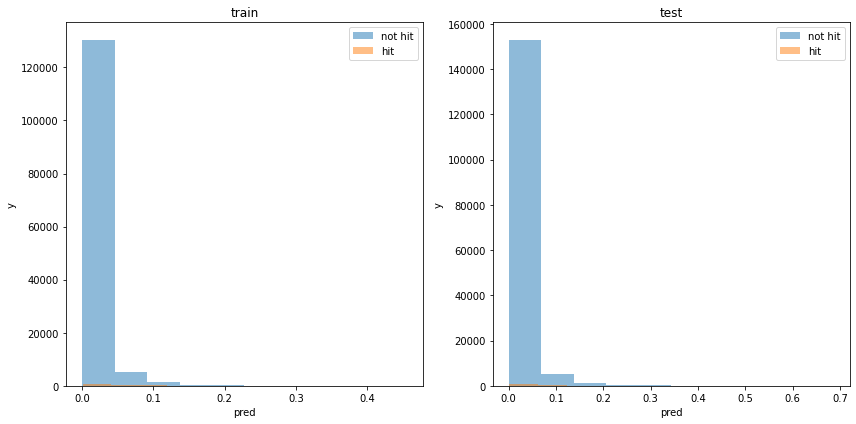
acc : 0.8658669574700109モデルの出力分布
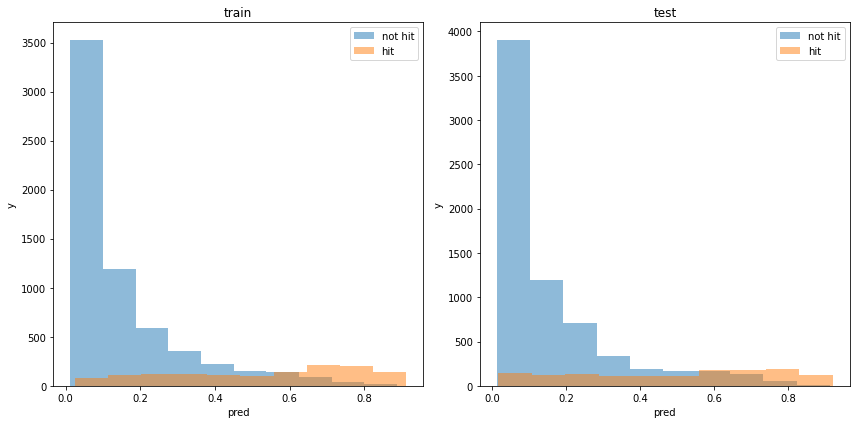
使用した特徴量
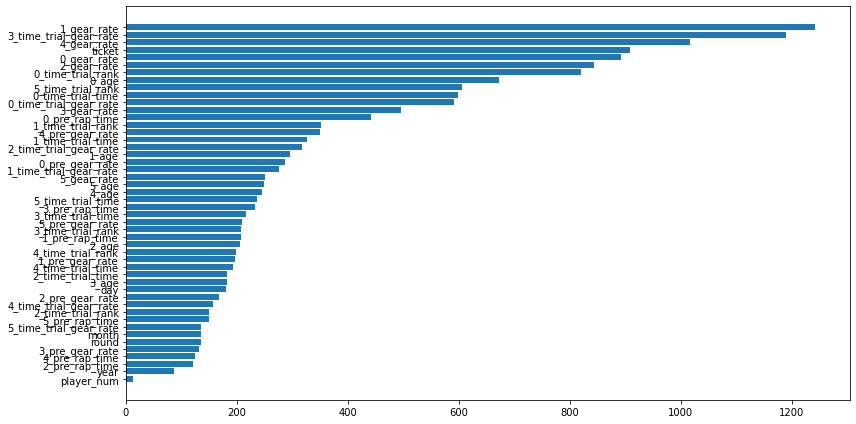
利益
利益はマイナスでした。
train win money :(-15.0, 1098.0, 1113)
test win money :(-176.29999999999995, 1039.7, 1216)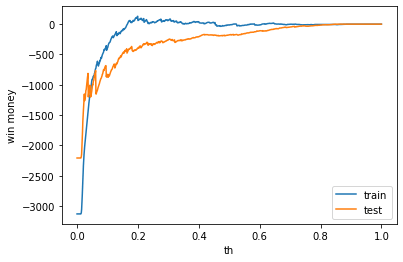
二連複
analysis_ticket_effect('nirenhuku')正答率
水増しをして学習した結果、テストデータの正答率がベースラインよりも下がってしまいました。
しかし、これは外れる可能性があってもベットするようになったとも言えます。
lgbm train
base acc : 0.49962006079027355
acc : 0.9615417088821344
lgbm valid
base acc : 0.500886524822695
acc : 0.9567572892040977
train
base acc : 0.9263618943334245
acc : 0.9264713933753079
test
base acc : 0.9317869752844252
acc : 0.927961945861122モデルの出力分布
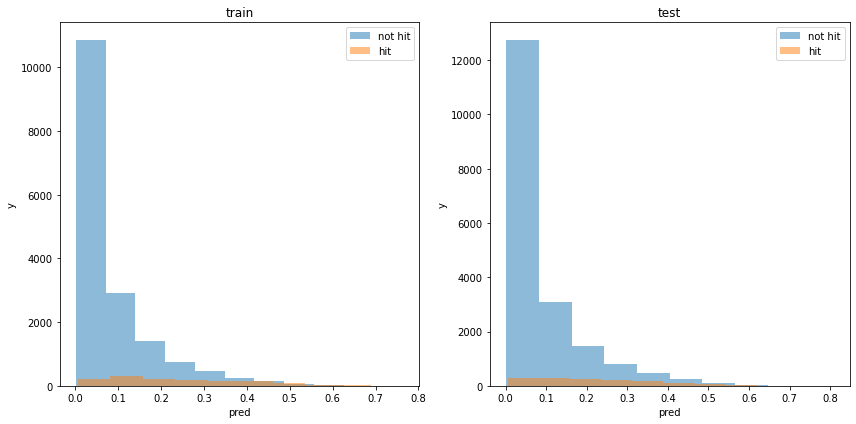
使用した特徴量
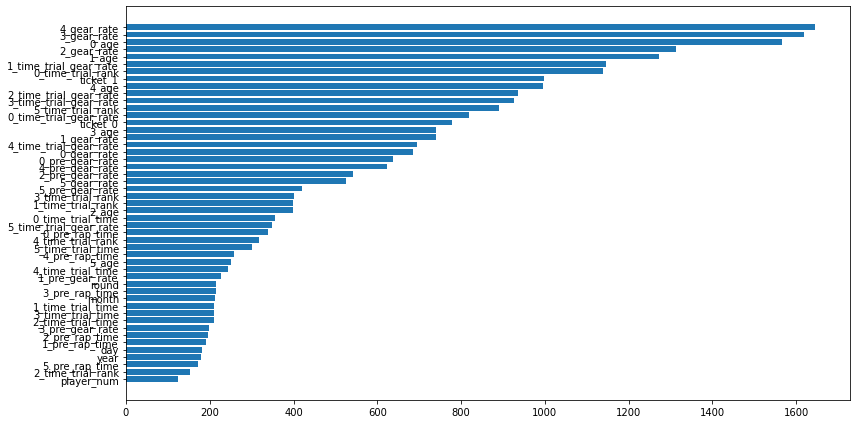
利益
利益はマイナスでしたが、もう少しでプラスになりそうであり、希望が持てます。
train win money :(13.800000000000011, 167.8, 154)
test win money :(-0.09999999999999432, 211.9, 212)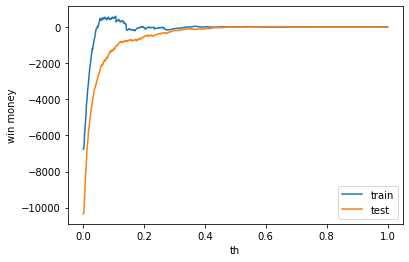
二連単
analysis_ticket_effect('nirentan')正答率
二連複と同様にテストデータのベースラインよりも下がってしまいました。
lgbm train
base acc : 0.5004770701800686
acc : 0.980957794514708
lgbm valid
base acc : 0.49888683624650654
acc : 0.9803420018000095
train
base acc : 0.9631809471667123
acc : 0.963044073364358
test
base acc : 0.9658934876422126
acc : 0.9650353079639075モデルの出力分布
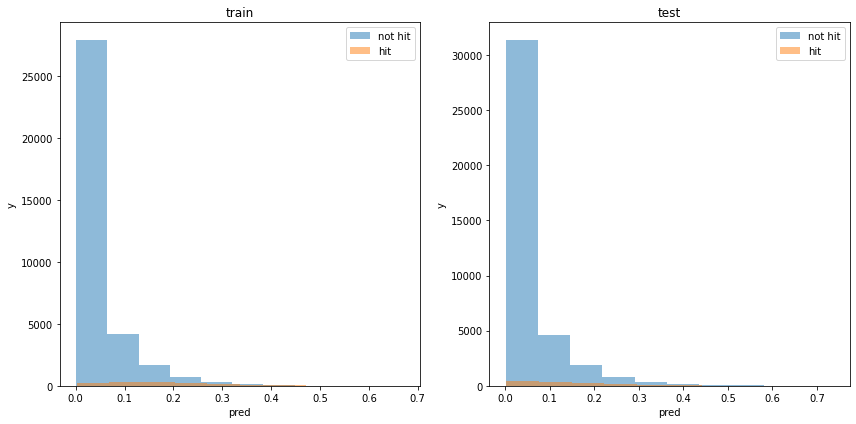
使用した特徴量
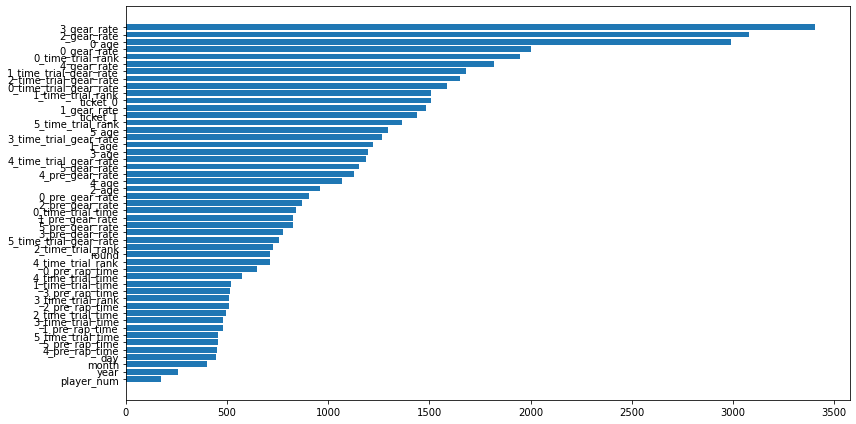
利益
テストデータの利益がでました。しかし、学習データはマイナスなので、要検証が必要です。
train win money :(-4.300000000000001, 22.7, 27)
test win money :(33.900000000000006, 122.9, 89)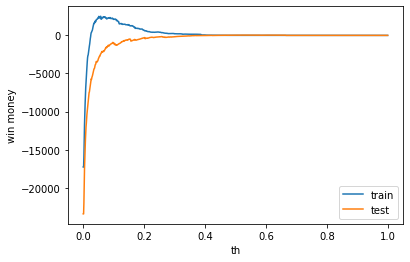
三連複
analysis_ticket_effect('sanrenhuku')正答率
二連複と同様にテストデータのベースラインよりも下がってしまいました。
lgbm train
base acc : 0.5010958814485262
acc : 0.9701985671758971
lgbm valid
base acc : 0.497442943286772
acc : 0.9680940386230059
train
base acc : 0.9419758412424504
acc : 0.9428817946505609
test
base acc : 0.9482668848556977
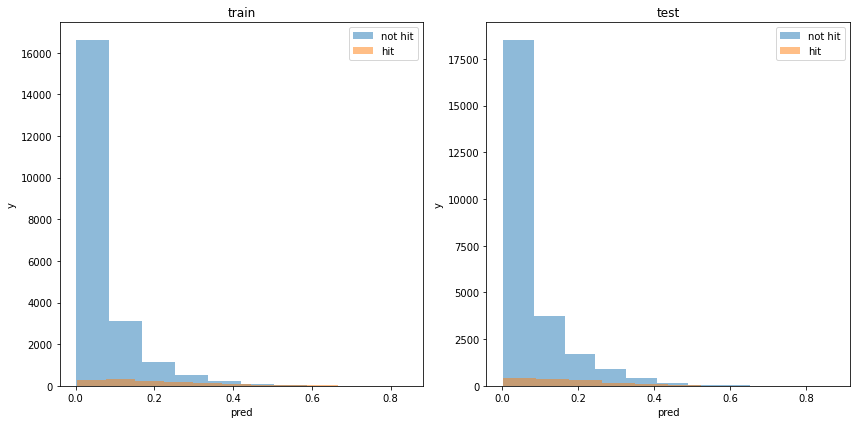
acc : 0.9461097887533472モデルの出力分布
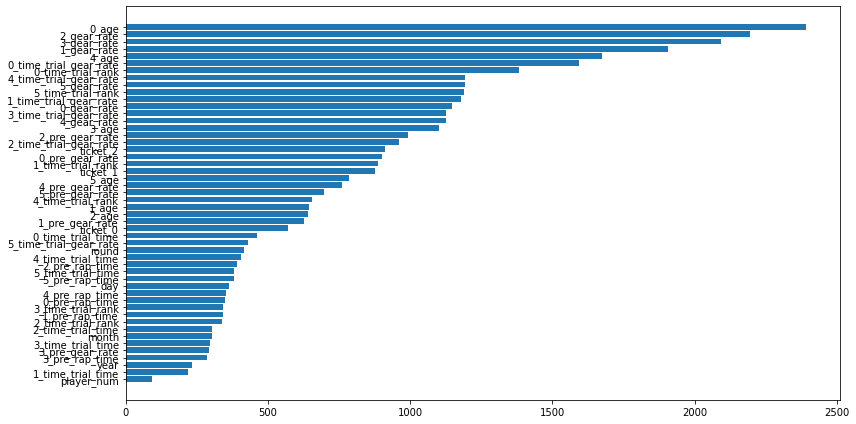
使用した特徴量
利益
利益はマイナスでしたが、もう少しでプラスになりそうであり、希望が持てます。
train win money :(6.200000000000003, 123.2, 117)
test win money :(-0.6999999999999886, 111.30000000000001, 112)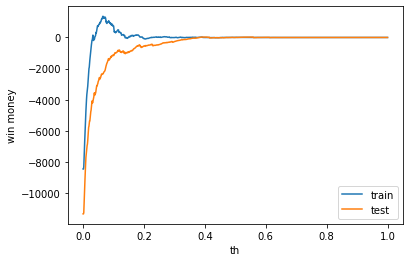
三連単
analysis_ticket_effect('sanrentan')正答率
二連複と同様にテストデータのベースラインよりも下がってしまいました。
lgbm train
base acc : 0.4996136473248318
acc : 0.9950629832649653
lgbm valid
base acc : 0.5009014895753924
acc : 0.9952323907019518
train
base acc : 0.9903293068737418
acc : 0.9903293068737418
test
base acc : 0.9913778141426163
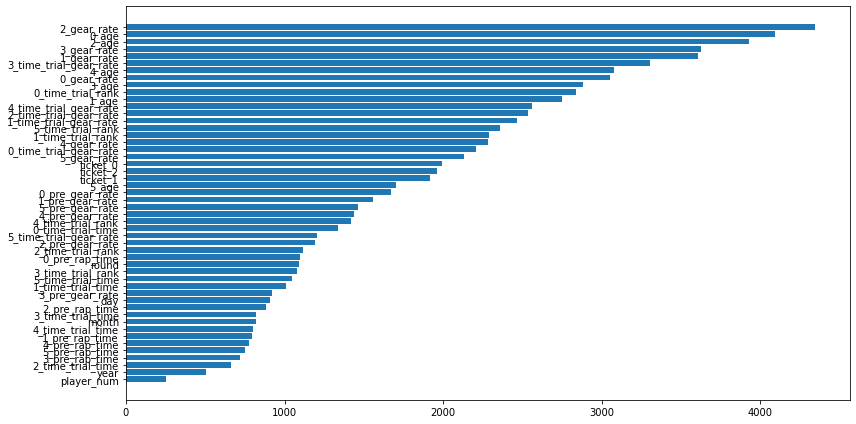
acc : 0.9912662402062878モデルの出力分布
使用した特徴量
利益
テストデータの利益がでました。しかし、学習データの利益は0なので、要検証が必要です。
train win money :(0.0, 0.0, 0)
test win money :(59.80000000000001, 85.80000000000001, 26)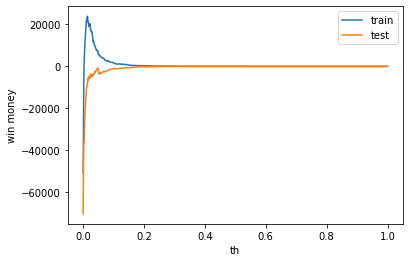
まとめ
単勝以外にて、いままでと違う結果がでました。
正答率は、水増しをしたことでベースラインよりも下がってしまいました。
しかし、これはこれはハズレる可能性があってもベットするようになったとも言えます。
二連複、三連複では、利益がマイナスでしたが、0に近く、プラスに転じる可能性があります。
また、二連単、三連単では利益がプラスになりました。学習データでは利益がでていないので、次のセクションでこれが偶然なのかを検証していきたいと思います。
