
はじめに
今回は、phi-3-medium-128k-instructをllamafileで動かしてみたいと思います。
phi-3シリーズはローカルでも最も性能の良いLLMだと思いますが、現在リリースされている中で、最も性能が良いのがphi-3-mediumです。

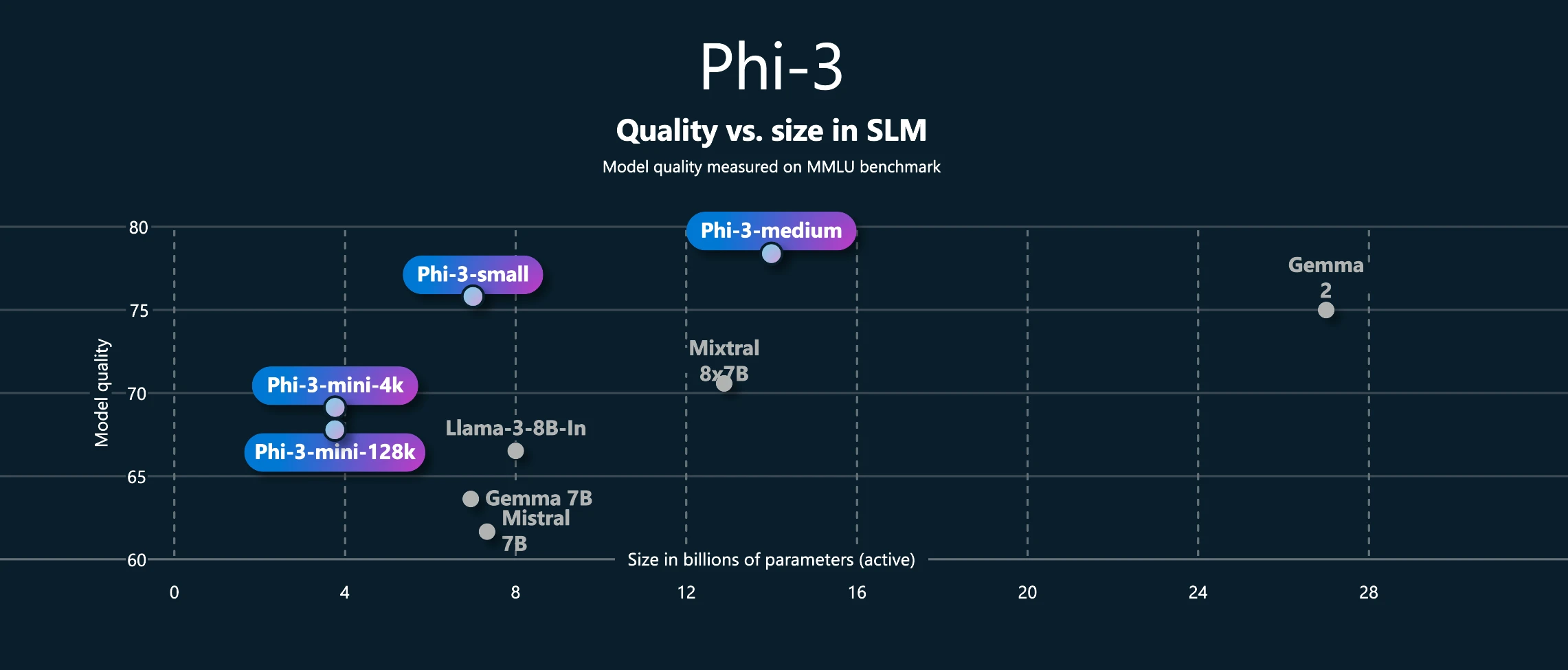
phi-3-mediumは14BパラメータのLLMですので、おそらく一般のPCで動かせる上限ギリギリのLLMだと思います。
そして、phi-3-miniの時点でChatGPT 3.5相当と言われていたので、mediumだったら実用面では問題ない性能が出せると思います。
ホントはphi-3-smallを検証したいのですが、ネットワークの形式がmini、mediumとsmallでは違うらしく、まだsmallだけllama.cpp(llamafile、ollama)ではまだ対応できていないらしいです。
インストール
やることは、llamafileの最新版と、phi-3-mediumをダウンロードするだけです。
llamafileの(モデルを含めいない最新版)はgitのリリースページから確認できます。

筆者のダウンロードしたのは0.8.6でした。windows環境では拡張子を.exeに変更してください。
また、phi-3-mediumはこちらの方がguff版を配布しています。

今回は、Phi-3-medium-128k-instruct-Q4_K_M.ggufをダンロードしました。
Q4_K_Mでファイルサイズは8.3GBでした。
実行
実行は簡単で、コマンドライン上で引数を渡して実行するだけです。
プロンプトは次の形式で渡すと良いらしいです。
<|user|>\nQuestion <|end|>\n<|assistant|>実行してみます
.\llamafile-0.8.6.exe -m .\Phi-3-medium-128k-instruct-Q4_K_M.gguf -p "<|user|>what is best movies?<|end|><|assistant|>"モデルロードのログが流れた後に、回答が返ってきました
\n what is best movies? \n Determining the "best" movies can be quite subjective as it depends on personal taste, genre preferences, and cultural background. However, there are several lists that can give you an idea of what are considered to be the best movies by critics and audiences alike.
1. **The IMDb Top 250**: IMDb's list of the top-rated movies is based on votes from over 3 million members. The list is updated weekly.
2. **The American Film Institute's 100 Years... 100 Movies**: This is a list of the top 100 films in American cinema as chosen by a jury of over 1,500 people from the film industry.
3. **The Sight & Sound Top 100**: This list is voted on by an international group of film critics and is updated every ten years.
4. **The Criterion Collection**: Although not a list of the "best" movies per se, the Criterion Collection is a series of DVDs and Blu-rays that aims to be the definitive edition of important classic and contemporary films, with an emphasis on artistic merit.
5. **Rotten Tomatoes**: While Rotten Tomatoes doesn't have a "best" list per se, it does have a "Top 250" list that includes movies with the best critics' scores.
6. **Metacritic**: Similar to Rotten Tomatoes, Metacritic provides a comprehensive list of movies rated by critics, with scores and reviews.
7. **The National Society of Film Critics Awards**: This organization gives out awards for the best films of the year, and they have a list of past winners.
Remember, the "best" movies for you might not be on any of these lists. The beauty of film is that there's something out there for everyone, no matter what your tastes might be. [end of text]いい感じで返答してくれました。
検証1 実行速度
実行速度を測ってみます
実行したマシンのスペックは次のとおりです。
- CPU : i7- i7-5960X (8core), Memory 48GB
- GPU : RTX 3070, Memory 8GB
CPU実行
CPUのみで実行した場合の実行ログは次のとおりでした。
llama_print_timings: load time = 5718.29 ms
llama_print_timings: sample time = 16.69 ms / 441 runs ( 0.04 ms per token, 26423.01 tokens per second)
llama_print_timings: prompt eval time = 1485.92 ms / 13 tokens ( 114.30 ms per token, 8.75 tokens per second)
llama_print_timings: eval time = 116930.40 ms / 440 runs ( 265.75 ms per token, 3.76 tokens per second)
llama_print_timings: total time = 118582.46 ms / 453 tokens453tokenで118582.46 msなので、1tokenあたり261.77 msですね。つまり、1トークン出力するのに0.26秒です。
GPU 実行
llamafileは–ngl オプションを使うと、GPUを利用してくれます。最大限使う場合は–ngl 9999です。
実行コマンドはこちら。
.\llamafile-0.8.6.exe -m .\Phi-3-medium-128k-instruct-Q4_K_M.gguf -p "<|user|>\n what is best movies?<|end|>\n<|assistant|>" -ngl 9999実行ログは次のとおりでした。
llama_print_timings: load time = 9281.69 ms
llama_print_timings: sample time = 37.85 ms / 820 runs ( 0.05 ms per token, 21662.18 tokens per second)
llama_print_timings: prompt eval time = 986.36 ms / 13 tokens ( 75.87 ms per token, 13.18 tokens per second)
llama_print_timings: eval time = 730383.23 ms / 819 runs ( 891.80 ms per token, 1.12 tokens per second)
llama_print_timings: total time = 731852.95 ms / 832 tokens832tokenで731852.95 msなので、1tokenあたり879.63msですね。つまり、1トークン出力するのに0.88秒かかるということです。
遅くなってます!!!
今回の実行マシンのGPUメモリは8GBなので、モデルが乗り切らなかったためか、実行速度はCPUよりも劣りました。phi-3-miniでは7~8倍速度が向上していたため、それを期待していたのですが…
検証2 日本語対応
日本語の対応を見てみます。powershellで実行すると、文字化けしました。–severオプションを使って、サーバーモードで起動します。そうすると、web uiが立ち上がるので、そこで実行しました。
.\llamafile-0.8.6.exe -m .\Phi-3-medium-128k-instruct-Q4_K_M.gguf --server実行結果は次のようになりました。
<|user|>
日本で一番有名な人は誰ですか?<|end|>
<|assistant|>「最も有名」という言葉によって、さまざまな分野での知名度や影響力を基準にした判断が必要となります。一般的には多くの場合次の人物が候補となることがあります:
- 政治家:安倍晋三(元首相)
- 文学者・作家:村上春樹
- アニメーションクリエイター:宮崎駿
これらの人物は日本国内だけでなく、世界的にも高い知名度を持っております。<|end|>知識的にも間違ってない回答が返ってきました!日本語でも十分に使えそうです。
まとめ
今回は、phi-3-mediumをllamafileで実行してみました。
結論としては、個人PCで動かすには少し重すぎるような気がします。
ただ、社用の共有PCとか専用のサーバー等を利用して使うのであれば、十分にChatGPTなどの代替になりえると思います。
追記
ローカルLLMでもjsonフォーマットを指定できる話を書きました。


