
LightGBMと同様にタイムを予測するRegressionを行います
学習過程はipynbファイルで行いました。以下はその記録です。
前処理
基本的にChapter03の前処理はほぼ同じです。教師データとなる列名によって、すこしコードをいじる程度の使いまわしです。
まず、使いそうなライブラリをインポートします。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from IPython.display import display, Math学習データの読み込み
df = pd.read_pickle('/work/formatted_source_data/analysis_data03.pkl')タイムデータ(文字列)を秒数タイム(float)へと変換します。
def time_str_to_sec_float(time_str):
sp_df = time_str.str.split(':', expand=True)
sp_df.columns = ['min', 'sec']
sp_df = sp_df.astype('float64')
return sp_df['min']*60 + sp_df['sec']
for n in range(1, 19):
df[f'horse_{n}_time_sec'] = time_str_to_sec_float(df[f'horse_{n}_time'])次に学習データとテストデータ、バリデーションデータの切り分け、および入力データと教師データの切り分けをします。データの正規化もします。
処理の説明はLightGBMと大差ないので割愛します。
pytorchの学習はデフォルトがfloat32型なので、numpyのfloat32型へ変えておきます。
df = df.sort_values(['race_date']).reset_index(drop=True)
not_use_columns = [
'race_date', 'race_id', 'race_grade'
]
for n in range(1, 19):
for col_keyword in ['name', 'jocky_name', 'odds', 'popular', 'rank', 'time', 'prize', 'tansyo_hit', 'tansyo_payout', 'hukusyo_hit', 'hukusyo_payout', 'time_sec']:
not_use_columns.append(f'horse_{n}_{col_keyword}')
not_use_columns += [col for col in df.columns if 'ped' in col]
not_use_df = df[not_use_columns]
target_df = df.drop(columns=not_use_columns)
train_df = target_df.loc[not_use_df['race_date'] < '2018-01-01', :].reset_index(drop=True)
valid_df = target_df.loc[('2018-01-01' <= not_use_df['race_date']) & (not_use_df['race_date'] < '2022-01-01'), :].reset_index(drop=True)
test_df = target_df.loc['2022-01-01' <= not_use_df['race_date'], :].reset_index(drop=True)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
train_X = scaler.fit_transform(train_df).astype(np.float32)
valid_X = scaler.transform(valid_df).astype(np.float32)
test_X = scaler.transform(test_df).astype(np.float32)
target_col_keyward = 'time_sec'
Y_columns = [f'horse_{n}_{target_col_keyward}' for n in range(1, 19)]
train_Y = not_use_df.loc[not_use_df['race_date'] < '2018-01-01', Y_columns].reset_index(drop=True)
valid_Y = not_use_df.loc[('2018-01-01' <= not_use_df['race_date']) & (not_use_df['race_date'] < '2022-01-01'), Y_columns].reset_index(drop=True)
test_Y = not_use_df.loc['2022-01-01' <= not_use_df['race_date'], Y_columns].reset_index(drop=True)
scaler_Y = StandardScaler()
train_Y = scaler_Y.fit_transform(train_Y).astype(np.float32)
valid_Y = scaler_Y.transform(valid_Y).astype(np.float32)
test_Y = scaler_Y.transform(test_Y).astype(np.float32)学習
pytorchのライブラリ群をインポートします
import torch
from torch import nn
from torch.autograd import Variable学習パラーメターを設定します。30epochだと収束しなそうだったので、100epoch学習しました。
batch_size = 1024
learning_rate = 0.001
max_epoch = 100numpyデータからtorchのTensor型、およびそれらをミニバッチで切り出すDataLoaderへと変換します。valid_loaderはこの程度のバッチ数とモデルサイズだったら、一度で処理できるので必要ありませんが、モデルサイズが大きくなると切り出さないと処理できなくなるため、一応書きました。
Y_maskデータは、出力データが存在しない場合をマスキングして取り除くために使います。
train_X = np.nan_to_num(train_X)
valid_X = np.nan_to_num(valid_X)
test_X = np.nan_to_num(test_X)
train_Y_mask = np.isfinite(train_Y)
valid_Y_mask = np.isfinite(valid_Y)
test_Y_mask = np.isfinite(test_Y)
train_Y = np.nan_to_num(train_Y)
valid_Y = np.nan_to_num(valid_Y)
test_Y = np.nan_to_num(test_Y)
train_dataset = torch.utils.data.TensorDataset(torch.from_numpy(train_X), torch.from_numpy(train_Y), torch.from_numpy(train_Y_mask))
valid_dataset = torch.utils.data.TensorDataset(torch.from_numpy(valid_X), torch.from_numpy(valid_Y), torch.from_numpy(valid_Y_mask))
#test_dataset = torch.utils.data.TensorDataset(torch.from_numpy(test_X), torch.from_numpy(test_Y))
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
valid_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=batch_size, shuffle=True)ネットワークとオプティマイザーを作ります。損失関数はMSELossを使いました。オプティマイザーは汎用的に使えるAdamWを使いました。
最終層はRegressionなのでSigmoidは外します。
また、Y_maskをモデルに入れて、処理することにしました。Section03-01,02と処理結果は変わらないので、好きな方を実装してください。
class NeuralNetwork(nn.Module):
def __init__(self, input_dim, output_dim):
super(NeuralNetwork, self).__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 512),
nn.ReLU(),
nn.BatchNorm1d(512),
nn.Dropout(0.2),
nn.Linear(512, 1024),
nn.ReLU(),
nn.BatchNorm1d(1024),
nn.Dropout(0.2),
nn.Linear(1024, 128),
nn.ReLU(),
nn.BatchNorm1d(128),
nn.Dropout(0.2),
nn.Linear(128, output_dim)
)
def forward(self, x, mask):
return self.net(x) * mask
device = torch.device('cuda')
loss_func = nn.MSELoss()
model = NeuralNetwork(train_X.shape[1], train_Y.shape[1])
model.to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)では、学習させていきます。バリデーションデータが最も良い地点でモデルを保存して、最後にそれを読み込んでいます。
best_valid = {
'score':None,
'epoch':0,
'model_path':None
}
logging = []
for epoch in range(max_epoch):
model.train()
train_loss = 0
model.train()
for X, Y, Y_mask in train_loader:
X = Variable(X.to(device), requires_grad=True)
Y = Variable(Y.to(device))
Y_mask = Variable(Y_mask.to(device), requires_grad=True)
optimizer.zero_grad()
out = model(X, Y_mask)
loss = loss_func(out, Y)
train_loss += loss.item() * X.shape[0]
loss.backward()
optimizer.step()
train_loss = train_loss / len(train_X)
model.eval()
with torch.no_grad():
valid_loss = 0
for X, Y, Y_mask in valid_loader:
X = Variable(X.to(device))
Y = Variable(Y.to(device))
Y_mask = Variable(Y_mask.to(device))
out = model(X, Y_mask)
loss = loss_func(out, Y)
valid_loss += loss.item() * X.shape[0]
valid_loss = valid_loss / len(valid_X)
print(f'-------epoch : {epoch} ----------')
print(f'loss')
print(f' train loss : {train_loss}')
print(f' valid loss : {valid_loss}')
logging.append({
'train_loss': train_loss,
'valid_loss': valid_loss,
})
save_path = f'/work/models/chapter3_section4.model'
if best_valid['score'] == None or best_valid['score'] > valid_loss:
best_valid['score'] = valid_loss
best_valid['epoch'] = epoch
best_valid['model_path'] = save_path
torch.save(model.state_dict(), save_path)
model.load_state_dict(torch.load(best_valid['model_path']))実行すると、ログが流れます。バリデーションのほうが学習データよりも小さいですが、これ以上lossは下がりませんでした。
...
-------epoch : 96 ----------
loss
train loss : 0.01632469103619268
valid loss : 0.01025331701397197
-------epoch : 97 ----------
loss
train loss : 0.017544591594054786
valid loss : 0.008096648873985446
-------epoch : 98 ----------
loss
train loss : 0.016452931638128318
valid loss : 0.008647380136571289
-------epoch : 99 ----------
loss
train loss : 0.016775670449995884
valid loss : 0.011031472534828574学習結果の解析
学習曲線を見てみます
logging_df = pd.DataFrame(logging)
plt.plot(logging_df['train_loss'], label='train loss')
plt.plot(logging_df['valid_loss'], label='valid loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()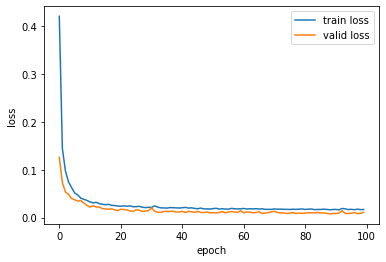
もう少し、過学習傾向を強めても良い気もしますが、妥当な感じがします。
次に、出力の分布を見てみます。一度、モデルの出力値を吐き出し、numpy型へと変換します。
X = torch.from_numpy(train_X).to(device)
Y_mask = torch.from_numpy(train_Y_mask).to(device)
train_pred = model(X, Y_mask).cpu().detach().numpy()
X = torch.from_numpy(valid_X).to(device)
Y_mask = torch.from_numpy(valid_Y_mask).to(device)
valid_pred = model(X, Y_mask).cpu().detach().numpy()
X = torch.from_numpy(test_X).to(device)
Y_mask = torch.from_numpy(test_Y_mask).to(device)
test_pred = model(X, Y_mask).cpu().detach().numpy()その後、各データをマスクして、分布を見てみます。
train_pred_flat =train_pred[train_Y_mask==1]
valid_pred_flat = valid_pred[valid_Y_mask==1]
test_pred_flat = test_pred[test_Y_mask==1]
train_Y_flat = train_Y[train_Y_mask==1]
valid_Y_flat = valid_Y[valid_Y_mask==1]
test_Y_flat = test_Y[test_Y_mask==1]
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(131)
plt.scatter(train_pred_flat, train_Y_flat)
plt.title('train')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(132)
plt.scatter(valid_pred_flat, valid_Y_flat)
plt.title('valid')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(133)
plt.scatter(test_pred_flat, test_Y_flat)
plt.title('test')
plt.xlabel('pred')
plt.ylabel('y')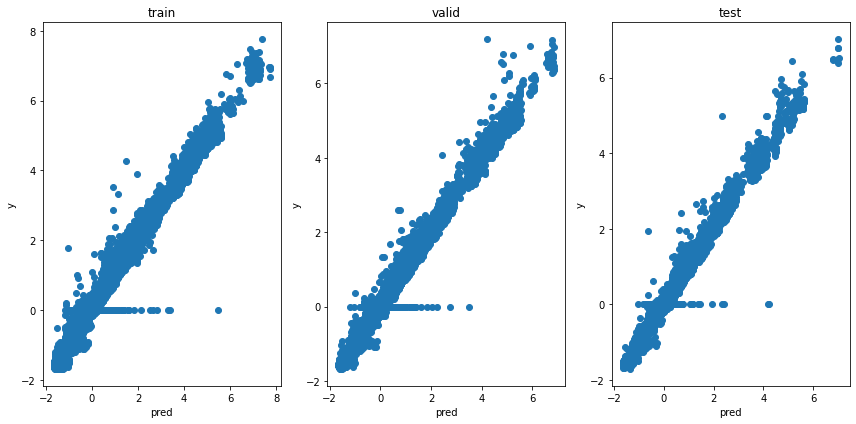
LightGBMのときほどではないですが、キレイな直線がでていて、予測できていると言えます。
利益の解析
利益を計算してみます。
target_col_keyward = 'tansyo_hit'
Y_columns = [f'horse_{n}_{target_col_keyward}' for n in range(1, 19)]
train_hit_Y = not_use_df.loc[not_use_df['race_date'] < '2018-01-01', Y_columns].reset_index(drop=True)
valid_hit_Y = not_use_df.loc[('2018-01-01' <= not_use_df['race_date']) & (not_use_df['race_date'] < '2022-01-01'), Y_columns].reset_index(drop=True)
test_hit_Y = not_use_df.loc['2022-01-01' <= not_use_df['race_date'], Y_columns].reset_index(drop=True)
train_hit_Y = np.nan_to_num(train_hit_Y.values)
valid_hit_Y = np.nan_to_num(valid_hit_Y.values)
test_hit_Y = np.nan_to_num(test_hit_Y.values)
target_col_keyward = 'tansyo_payout'
Y_columns = [f'horse_{n}_{target_col_keyward}' for n in range(1, 19)]
train_payout_Y = not_use_df.loc[not_use_df['race_date'] < '2018-01-01', Y_columns].reset_index(drop=True)
valid_payout_Y = not_use_df.loc[('2018-01-01' <= not_use_df['race_date']) & (not_use_df['race_date'] < '2022-01-01'), Y_columns].reset_index(drop=True)
test_payout_Y = not_use_df.loc['2022-01-01' <= not_use_df['race_date'], Y_columns].reset_index(drop=True)
train_payout_Y = np.nan_to_num(train_payout_Y.values)
valid_payout_Y = np.nan_to_num(valid_payout_Y.values)
test_payout_Y = np.nan_to_num(test_payout_Y.values)
def calc_win_money(pred_Y, hit, payout, Y_mask):
Y_mask = Y_mask == 1
win_money = 0
for i in range(pred_Y.shape[0]):
mask = Y_mask[i, :]
race_pred_Y = pred_Y[i, mask]
race_hit = hit[i, mask]
race_payout = payout[i, mask]
n = np.argmin(race_pred_Y)
win_money += race_hit[n] * race_payout[n] - 1.0
return win_money
print(f'train win money :{calc_win_money(train_pred, train_hit_Y, train_payout_Y, train_Y_mask)}')
print(f'valid win money :{calc_win_money(valid_pred, valid_hit_Y, valid_payout_Y, valid_Y_mask)}')
print(f'test win money :{calc_win_money(test_pred, test_hit_Y, test_payout_Y, test_Y_mask)}')学習、バリデーション、テスト、すべてのデータでマイナスの利益でした。
train win money :-23508.60000000001
valid win money :-5387.900000000004
test win money :-3422.3000000000006やはり、LightGBMのほうがマシなような気がします。
