
huggingfaceのtrendを眺めていたら、MiniCPM-Llama3-V-2_5というモデルが目に止まりました。

なんと、ローカルで動く(しかもスマホ向け)モデルなのに、GTP-4VやGemini Pro、Claude 3と同程度以上のパフォーマンスだと書いてあります。
https://huggingface.co/openbmb/MiniCPM-Llama3-V-2_5
- 🔥 Leading Performance. MiniCPM-Llama3-V 2.5 has achieved an average score of 65.1 on OpenCompass, a comprehensive evaluation over 11 popular benchmarks. With only 8B parameters, it surpasses widely used proprietary models like GPT-4V-1106, Gemini Pro, Claude 3 and Qwen-VL-Max and greatly outperforms other Llama 3-based MLLMs.
- 💪 Strong OCR Capabilities. MiniCPM-Llama3-V 2.5 can process images with any aspect ratio and up to 1.8 million pixels (e.g., 1344×1344), achieving an 700+ score on OCRBench, surpassing proprietary models such as GPT-4o, GPT-4V-0409, Qwen-VL-Max and Gemini Pro. Based on recent user feedback, MiniCPM-Llama3-V 2.5 has now enhanced full-text OCR extraction, table-to-markdown conversion, and other high-utility capabilities, and has further strengthened its instruction-following and complex reasoning abilities, enhancing multimodal interaction experiences.
そして、llama.cppやollamaで動くとも書いてあります。実際に使って試してみましょう
ちなみに、MiniCPM-VのGithubはこちら

どうやら同時期に発表されたLlama-3-Vでは無いみたいです。Llama3-8B-Instructに画像認識モデルをくっつけた独自のモデルみたいですね。
追記
どうやらLlama-3-Vを盗用として訴えている様ですね。MiniCPM-Vの重みにノイズを付与した場合と、Llama-3-Vの性能が非常に高い割合で一致するなどの問題点が指摘されているようです(他にも、ソースコードの構造一致など、疑わしい事実が複数あります)。
未公開のテストデータ(古代中国語)に対する出力がほとんど同じ、などの問題点も指摘されています。
詳しくは、こちらのissuesに乗ってます。
ちなみにLlama-3-Vはhugging faceでの公開をやめたみたいですね。だから、探しても無かったのか…
実行環境
llama.cppのオリジナルでは、まだMiniCPM-V-2.5をサポートしていないようです。llama.cppでの動かし方はこちらに書いてあります。
Docker(dev-container)でllama.cppのビルド環境を作りました。自分でビルドできる方はdocker使わなくてもいいです。gitとC++のコンパイル環境を入れればいいと思います。
FROM python:3.10-slim-bullseye
ARG USERNAME=vscode
ARG USER_UID=1000
ARG USER_GID=$USER_UID
ENV LANG ja_JP.UTF-8
ENV LANGUAGE ja_JP:ja
ENV LC_ALL ja_JP.UTF-8
ENV TZ JST-9
ENV TERM xterm
RUN apt-get update \
&& groupadd --gid $USER_GID $USERNAME \
&& useradd -s /bin/bash --uid $USER_UID --gid $USER_GID -m $USERNAME \
&& apt-get install -y sudo \
&& echo $USERNAME ALL=\(root\) NOPASSWD:ALL > /etc/sudoers.d/$USERNAME \
&& chmod 0440 /etc/sudoers.d/$USERNAME \
&& apt-get -y install locales \
&& localedef -f UTF-8 -i ja_JP ja_JP.UTF-8
RUN apt install -y build-essential libssl-dev
RUN apt install -y gcc g++
RUN apt -y install cmake
RUN apt-get -y install git
RUN pip install --upgrade pip
RUN pip install --upgrade setuptools
コンテナを立てたら、中に入り、レポジトリをクローンします。
git clone -b minicpm-v2.5 https://github.com/OpenBMB/llama.cpp.git llama_cpp_minicpm
cd llama_cpp_minicpm/その後は、ReadMeに従ってコンパイルするだけです。
make
make minicpmv-cliエラーなくコンパイルが成功すれば、minicpmv-cliという実行ファイルが生成されています。
次に、モデルをダンロードします。モデルは次のリンクから好きな量子化モデルを選んでください。

ここではggml-model-Q4_K_M.ggufにしました。
また、マルチモーダル用の追加モデルも上記のリンクからダウンロードします。モデルのファイル名はmmproj-model-f16.ggufです。
ダウンロードしたモデルファイルたちを、llama_cpp_minicpm/modelsへ入れます(相対パスが合っていればいいので、実際はコンテナ内のどこに置いてもらっても構いません)。
あとは、マルチモーダルLLMに与える画像を用意して、適当なディレクトリに入れます。
ここれは、llama_cpp_minicpm/imagesというディレクトリを作り、入れました。
実験
実際に動かしてみて、どんな感じか見てみましょう。当然CPU環境で実行します。実行したCPUはi7-5960Xという型落ちのCPUです。
画像を説明させる
フリー画像を適当にもらってきて、miniCPM-Vに読み込ませてみます。

実行コマンドは次のとおりです。
./minicpmv-cli -m models/ggml-model-Q4_K_M.gguf --mmproj models/mmproj-model-f16.gguf -c -4098 --temp 0.7 --top-p 0.8 --top-k 100 --repeat-penalty 1.05 --image images/image0.jpg -p "what is in the image?"少し待つと、次のようなテキストが返ってきました。
In the image, there is a table set with various types of food and utensils. There is a bowl with cereal and milk, a glass of water, a cup of coffee, and some fruit such as bananas and apples. There are also some utensils present on the table like a spoon and a fork. The setting appears to be in a kitchen or dining area.
google翻訳します。
画像には、さまざまな種類の食べ物や食器が置かれたテーブルがあります。シリアルとミルクの入ったボウル、コップ一杯の水、コーヒーカップ、バナナやリンゴなどの果物があります。テーブルにはスプーンやフォークなどの食器もいくつかあります。この設定はキッチンまたはダイニングエリアのようです。
いいのではないでしょうか?アボカドの説明はないですが、画像の説明としては正しいと思います。
実行時間のログは次のとおりでした
llama_print_timings: load time = 56803.85 ms
llama_print_timings: sample time = 156.38 ms / 76 runs ( 2.06 ms per token, 486.00 tokens per second)
llama_print_timings: prompt eval time = 56523.32 ms / 1002 tokens ( 56.41 ms per token, 17.73 tokens per second)
llama_print_timings: eval time = 8497.34 ms / 75 runs ( 113.30 ms per token, 8.83 tokens per second)
llama_print_timings: total time = 65654.81 ms / 1077 tokens実感としては画像を読み込むまでに数秒かかりました。
画像からテキスト抽出する(OCR)
次に、OCR性能も試してみます。せっかくなので、MiniCPMのgithubページをスクショして、読み込ませてみます。
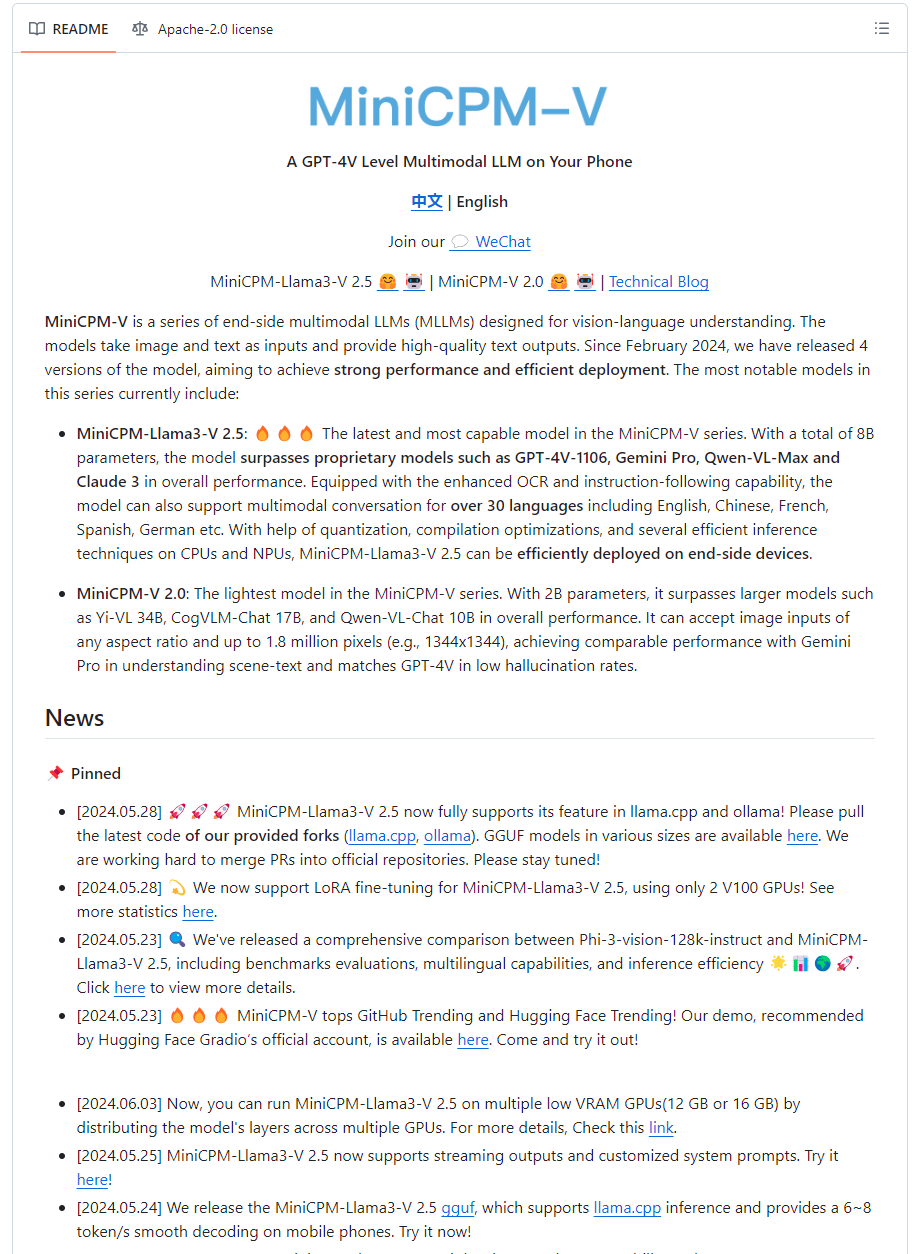
実行コマンドは次のとおりです。
./minicpmv-cli -m models/ggml-model-Q4_K_M.gguf --mmproj models/mmproj-model-f16.gguf -c -4098 --temp 0.7 --top-p 0.8 --top-k 100 --repeat-penalty 1.05 --image images/image1.jpg -p "Please identify the text in the image"少し待つと、次のようなテキストが返ってきました。
Title: MiniCPM-LV-2.5
Subtitle: MiniCPM-LV-2.5
Body Text: This is an end-to-end side-modal multimodal LLMs (Language Learning Models) that serve as vision-language understanding. The models take image and text as inputs and provide high-quality human text outputs. Since February 2024, we have released 4 versions of the model to achieve strong performance and efficient deployment. The most notable models in this series currently include:
List:
- MiniCPM-Lla-2.5 by OpenAI
- MiniCPM-Lv-2.5 by Google
- MiniCPM-LV-2.5 by Microsoft
- MiniCPM-LV-2.5 by IBM
Body Text: The MiniCPM models take advantage of the latest developments in image and text processing to provide accurate and efficient language understanding. They are designed to support a wide range of applications, from customer service chatbots to visual question answering systems.
Subtitle: News
List:
- [Link to a news article about MiniCPM-LV-2.5 being used in a specific project or application]
Subtitle: Reviews
Body Text: "MiniCPM-LV-2.5 is a
最初の方はいい感じですが、途中から適当なことを言っていますね。
日本語でやらせる
30の言語で動くと書いてあります。その中には日本語もありました。
さっそく日本語で質問してみます。

実行コマンドは次のとおりです。
./minicpmv-cli -m models/ggml-model-Q4_K_M.gguf --mmproj models/mmproj-model-f16.gguf -c -4098 --temp 0.7 --top-p 0.8 --top-k 100 --repeat-penalty 1.05 --image images/image2.jpg -p "この写真はなんですか?"少し待つと、次のようなテキストが返ってきました。
この写真は、ビーチの海岸線に位置している海辺の休憩所を描いている。この場所はあらゆるシーンの中で活気に満ちた雰囲気を醸し出しています。白いビーチは青い海と対照的で、緑の景色が背景にはっきりと見えます。
合ってる・・・のか?少なくとも、写真の中には活気が満ち溢れてはないし、緑の背景はありあません。青い海を緑と表現しているのでしょうか?
ただ、ビーチと海辺の休憩所であることは間違いないので、概ねあっていると言えます。
まとめ
今回はhugging faceでトレンドにあった、MiniCPM-Llama3-V-2_5をllama.cppで試してみました。
簡単に利用できましたし、画像の認識精度も悪くはないように思えます。
また、スマホ等の利用もできることを謳っているので、面白そうですね。

