
Section 02-01のノートを元に、各ブロックを関数化して検証に利用しやすい形にします。
その後、各関数を呼び出して、チケットの種類別の利益を検証します。
検証するチケットの種類は
- 単勝
- 二連複
- 二連単
- 三連複
- 三連単
の5種類です。
使いそうなライブラリをインポートします。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np関数定義
前回のノートの各ブロックを関数化していきます。前回と同じなので解説は省略します。
前処理
from sklearn.preprocessing import StandardScaler
def make_learning_data(df, not_use_columns, not_use_columns_keywards, ticket_type):
df['race_date'] = pd.to_datetime(df['race_date'])
if ticket_type == 'wide':
ticket_odds_df = df['ticket_odds'].str.split('\n~', expand=True).rename(columns={0:'ticket_odds_min',1:'ticket_odds_max'})
df['ticket_odds_min'] = ticket_odds_df['ticket_odds_min']
df['ticket_odds_max'] = ticket_odds_df['ticket_odds_max']
if 'ticket_odds' in not_use_columns:
not_use_columns.remove('ticket_odds')
not_use_columns.append('ticket_odds_min')
not_use_columns.append('ticket_odds_max')
#not_use_columns = ['race_id', 'race_date', 'ticket_odds', 'ticket_hit', 'ticket_payout']
#not_use_columns_keywards = ['rank', 'time']
for i in range(6):
for col_keyward in not_use_columns_keywards:
not_use_columns.append(f'{i}_{col_keyward}')
not_use_df = df[not_use_columns]
input_df = df.drop(columns=not_use_columns)
input_df = input_df.apply(pd.to_numeric, args=('coerce',))
for i in range(6):
if f'{i}_odds' in input_df.columns:
zero_mask = input_df[f'{i}_odds'] < 1.0
input_df[f'{i}_odds'] = np.log(input_df[f'{i}_odds'])
input_df.loc[zero_mask, f'{i}_odds'] = np.nan
if 'ticket_odds' in input_df.columns:
zero_mask = input_df['ticket_odds'] < 1.0
input_df['ticket_odds'] = np.log(input_df['ticket_odds'])
input_df.loc[zero_mask, 'ticket_odds'] = np.nan
train_mask = not_use_df['race_date'] < '2023-01-01'
test_mask = not_use_df['race_date'] >= '2023-01-01'
train_input_df = input_df.loc[train_mask, :].reset_index(drop=True)
test_input_df = input_df.loc[test_mask, :].reset_index(drop=True)
categorical_columns = ['round', 'year', 'month', 'day', 'player_num', 'ticket']
if ticket_type != 'tansyo':
categorical_columns.remove('ticket')
for n in range(3):
col = f'ticket_{n}'
if col in input_df.columns:
categorical_columns.append(col)
scaler = StandardScaler()
train_X = pd.DataFrame(data=scaler.fit_transform(train_input_df), columns=train_input_df.columns)
test_X = pd.DataFrame(data=scaler.transform(test_input_df), columns=test_input_df.columns)
for col in categorical_columns:
train_X.loc[:, col] = train_input_df.loc[:, col].astype('int64')
test_X.loc[:, col] = test_input_df.loc[:, col].astype('int64')
train_y = not_use_df.loc[train_mask, 'ticket_hit'].reset_index(drop=True).astype('int64')
test_y = not_use_df.loc[test_mask, 'ticket_hit'].reset_index(drop=True).astype('int64')
return train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask学習
import optuna.integration.lightgbm as lgb
def learning(train_X, train_y):
#import lightgbm as lgb
params = {
'objective': 'binary',
'metric': 'binary_logloss',
'learning_rate': 0.01,
}
num_round = 10000
from sklearn.model_selection import train_test_split
lgb_train_X, lgb_valid_X, lgb_train_y, lgb_valid_y = train_test_split(train_X, train_y, test_size=0.3)
lgb_train_X = lgb_train_X.reset_index(drop=True)
lgb_valid_X = lgb_valid_X.reset_index(drop=True)
lgb_train_y = lgb_train_y.reset_index(drop=True)
lgb_valid_y = lgb_valid_y.reset_index(drop=True)
lgb_train = lgb.Dataset(lgb_train_X, lgb_train_y)
lgb_eval = lgb.Dataset(lgb_valid_X, lgb_valid_y)
# training
model = lgb.train(params, lgb_train,
num_boost_round=num_round,
valid_sets=[lgb_train, lgb_eval],
valid_names=['train', 'valid'],
callbacks=[lgb.early_stopping(stopping_rounds=10, verbose=0)]
)
return model, (lgb_train_X, lgb_train_y, lgb_valid_X, lgb_valid_y)正答率の表示
def accuracy_print(model, X, y):
accuracy = lambda a, b : np.sum(a==b)/len(a)
pred = (model.predict(X) > 0.5).astype(int)
print(f' base acc : {accuracy(np.zeros_like(y), y)}')
print(f' acc : {accuracy(pred, y)}')モデルの出力分布の表示
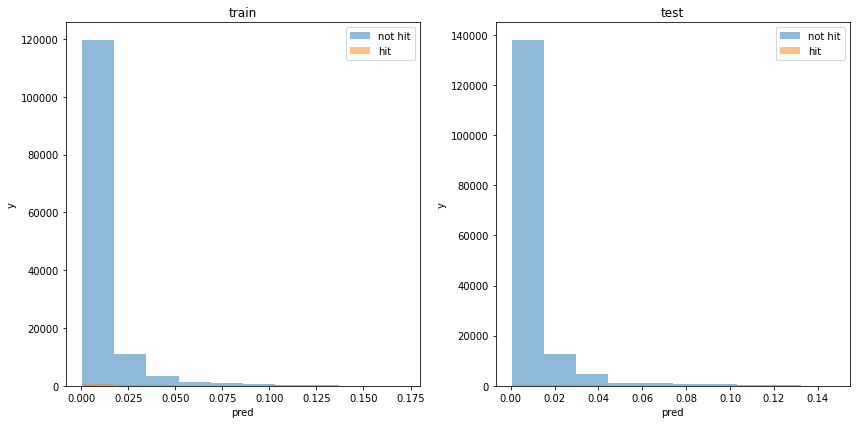
def print_model_p(model, train_X, train_y, test_X, test_y):
train_pred_p = model.predict(train_X)
test_pred_p = model.predict(test_X)
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(121)
plt.hist(train_pred_p[train_y==0], bins=10, label='not hit', alpha=0.5)
plt.hist(train_pred_p[train_y==1], bins=10, label='hit', alpha=0.5)
plt.legend()
plt.title('train')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(122)
plt.hist(test_pred_p[test_y==0], bins=10, label='not hit', alpha=0.5)
plt.hist(test_pred_p[test_y==1], bins=10, label='hit', alpha=0.5)
plt.legend()
plt.title('test')
plt.xlabel('pred')
plt.ylabel('y')
plt.show()使用した特徴量の表示
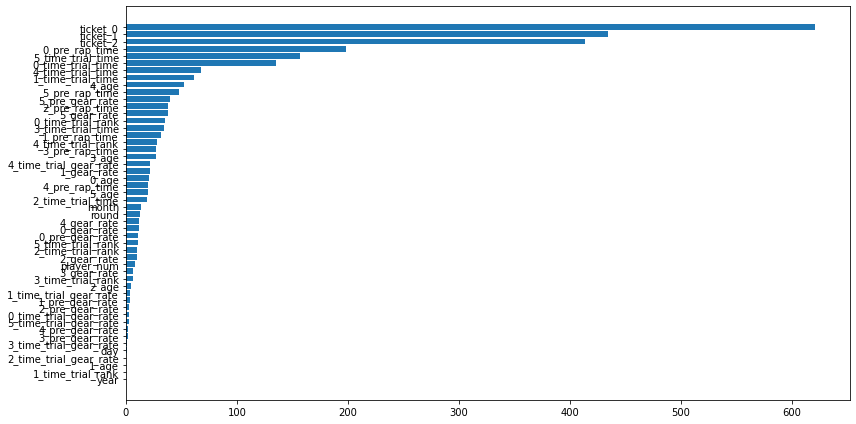
def print_feature_importance(model, X):
importance = pd.DataFrame(model.feature_importance(), index=X.columns, columns=['importance'])
importance = importance.sort_values(['importance'])
plt.figure(tight_layout=True, figsize=(12, 6))
plt.barh(importance.index, importance['importance'], align="center")
plt.show()利益の表示
def print_win_money(model, train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask):
train_payout = not_use_df.loc[train_mask, 'ticket_payout'].reset_index(drop=True)
test_payout = not_use_df.loc[test_mask, 'ticket_payout'].reset_index(drop=True)
train_pred = model.predict(train_X)
test_pred = model.predict(test_X)
def calc_win_money(pred, hit, payout, th=0.5):
bet = (pred > th).astype(int)
hit = hit.to_numpy()
payout = payout.to_numpy()
return_money = np.sum(bet * hit * payout)
bet_money = np.sum(bet)
win_money = return_money - bet_money
return win_money, return_money, bet_money
print(f'train win money :{calc_win_money(train_pred, train_y, train_payout, 0.5)[0]}')
print(f'test win money :{calc_win_money(test_pred, test_y, test_payout, 0.5)[0]}')
train_win_list = []
test_win_list = []
th_list = np.linspace(0.0, 1.0, 1000)
for th in th_list:
train_win_list.append(calc_win_money(train_pred, train_y, train_payout, th)[0])
test_win_list.append(calc_win_money(test_pred, test_y, test_payout, th)[0])
plt.plot(th_list, train_win_list, label='train')
plt.plot(th_list, test_win_list, label='test')
plt.legend()
plt.xlabel('th')
plt.ylabel('win money')
plt.show()学習の流れ
def analysis_columns_effect(df, not_use_columns, not_use_columns_keywards):
train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask = make_learning_data(df, not_use_columns, not_use_columns_keywards)
model, (lgb_train_X, lgb_train_y, lgb_valid_X, lgb_valid_y) = learning(train_X, train_y)
print('train')
accuracy_print(model, lgb_train_X, lgb_train_y)
print('valid')
accuracy_print(model, lgb_valid_X, lgb_valid_y)
print('test')
accuracy_print(model, test_X, test_y)
print_model_p(model, train_X, train_y, test_X, test_y)
print_feature_importance(model, train_X)
print_win_money(model, train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask)チケットの影響を調べる関数
def analysis_ticket_effect(ticket_type):
df = pd.read_pickle(f'/work/learning_data/learning_01_{ticket_type}.pkl')
not_use_columns = ['race_id', 'race_date', 'ticket_hit', 'ticket_payout']
not_use_columns_keywards = ['rank', 'time']
analysis_columns_effect(df, not_use_columns, not_use_columns_keywards, ticket_type)チケットの種類別の分析(すべての特徴量を使う)
単勝
これは前回のsection02-02で示したとおりです。
analysis_ticket_effect('tansyo')正答率
すべての特徴量を使うとテストデータでも0.887の精度がでました。
train
base acc : 0.8221395348837209
acc : 0.8786976744186047
valid
base acc : 0.8311631944444444
acc : 0.8806423611111112
test
base acc : 0.8314552284017933
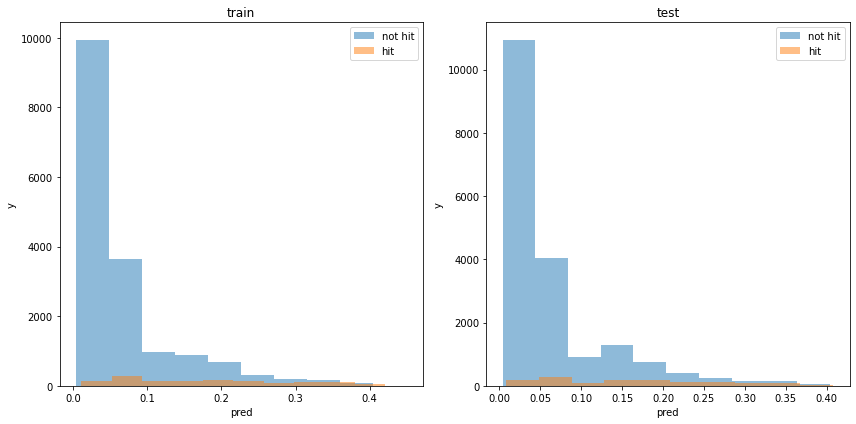
acc : 0.8871925360474979モデルの出力分布
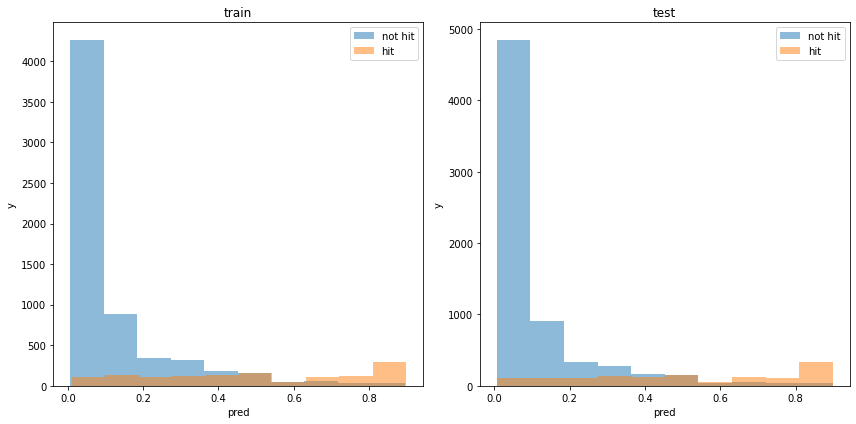
割と分類できている様に見えます。
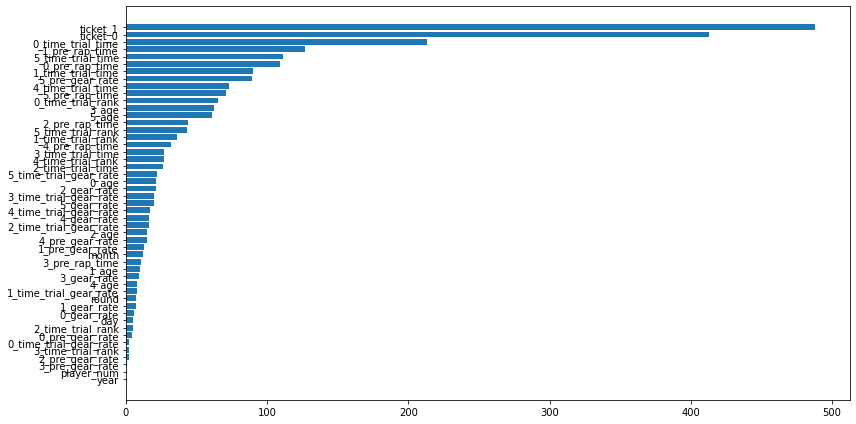
使用した特徴量

オッズ情報とタイムトライアル情報を殆どの場合使っています。逆に他の特徴量は利用しない傾向にあります。
利益
利益はマイナスでした。表示は左から、利益、買った金額、負けた金額(ベット数)です。
train win money :(-164.5, 695.5, 860)
test win money :(-165.0, 739.0, 904)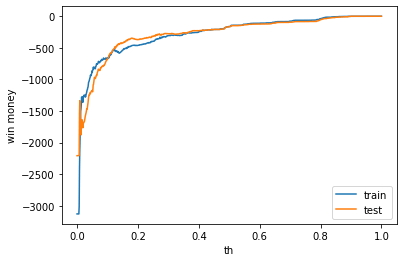
二連複
analysis_ticket_effect('nirenhuku')正答率
0.3%程度、ベースラインよりも精度がいいです。
train
base acc : 0.9244427062964411
acc : 0.9266327727806023
valid
base acc : 0.9308394160583942
acc : 0.9339416058394161
test
base acc : 0.9317869752844252
acc : 0.9345821890937622モデルの出力分布
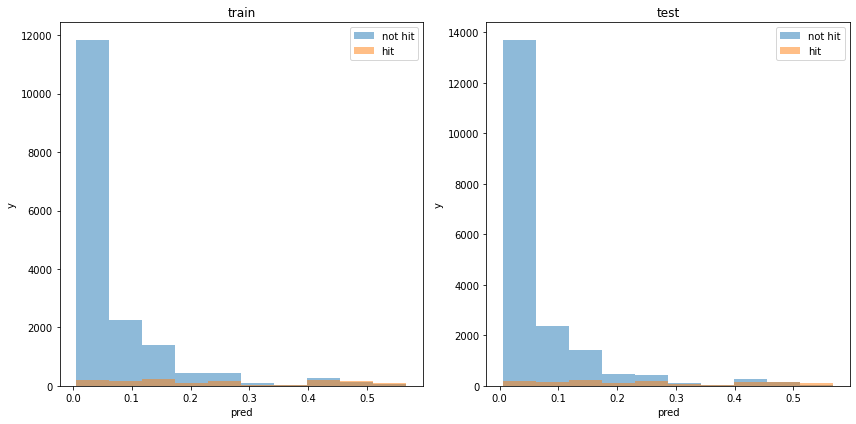
使用した特徴量
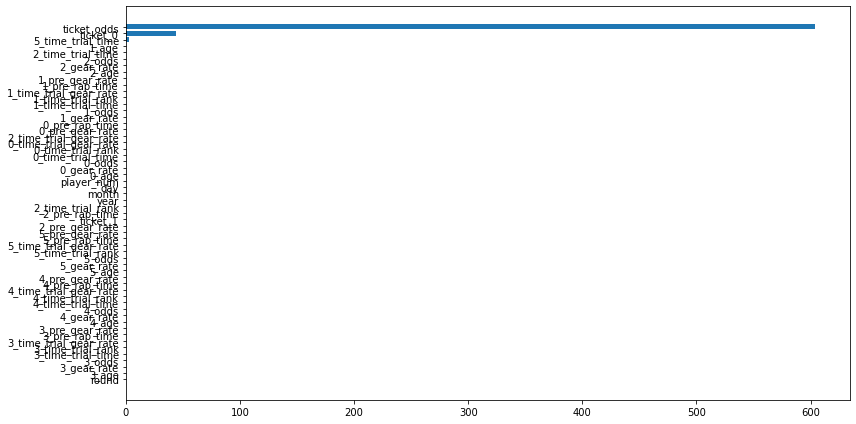
オッズとチケット情報しか見ていません。
利益
利益はマイナスでした。利益はマイナスでした。表示は左から、利益、買った金額、負けた金額(ベット数)です。
train win money :(-40.400000000000006, 100.6, 141)
test win money :(-37.500000000000014, 113.49999999999999, 151)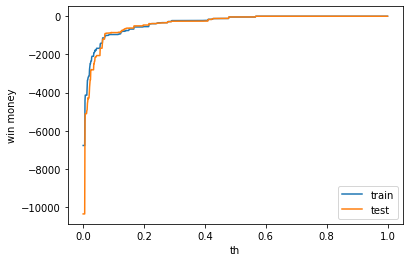
二連単
analysis_ticket_effect('nirentan')正答率
若干何も予測しないよりは精度が良いですが、ほとんど変わりません。
train
base acc : 0.9642172773845372
acc : 0.9647256657932815
valid
base acc : 0.9607628433251209
acc : 0.9613103385345378
test
base acc : 0.9658934876422126
acc : 0.9663838760298156モデルの出力分布
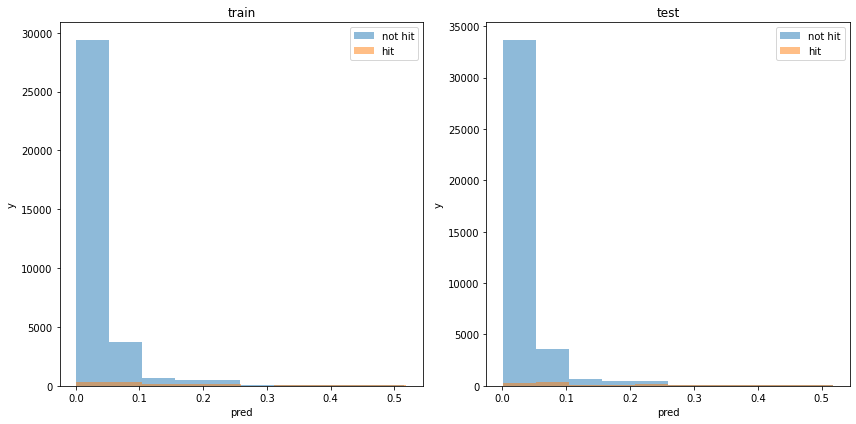
使用した特徴量
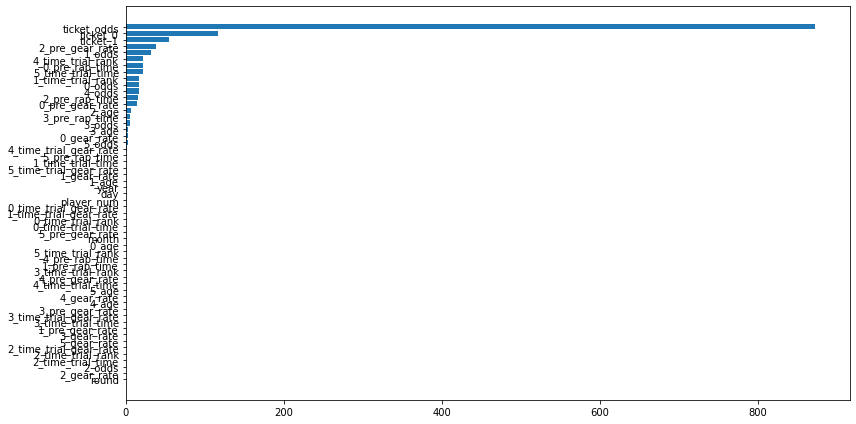
利益
テストデータの利益はマイナスでした。利益はマイナスでした。表示は左から、利益、買った金額、負けた金額(ベット数)です。
train win money :(0.6000000000000014, 35.6, 35)
test win money :(-5.0, 41.0, 46)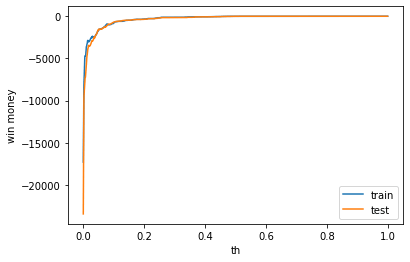
三連複
analysis_ticket_effect('sanrenhuku')正答率
全く学習できていません。すべて外れると予想した場合(base acc)と同じ正答率です。
train
base acc : 0.9421915444348576
acc : 0.9421915444348576
valid
base acc : 0.9414725337935002
acc : 0.9416163359217716
test
base acc : 0.9482668848556977
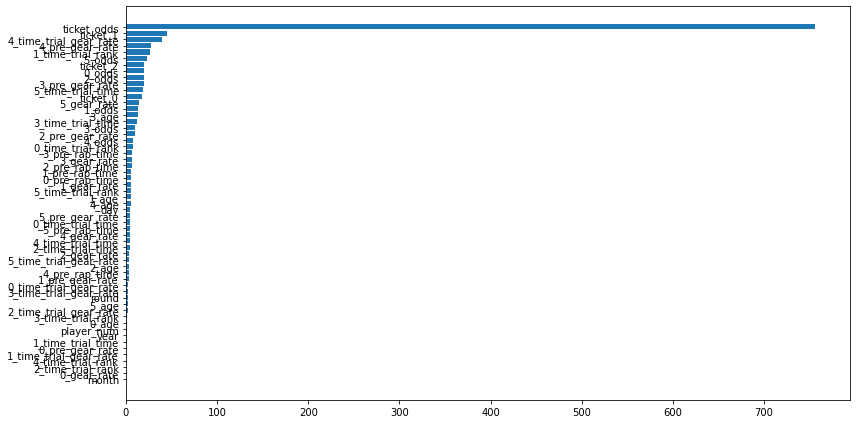
acc : 0.9482668848556977モデルの出力分布
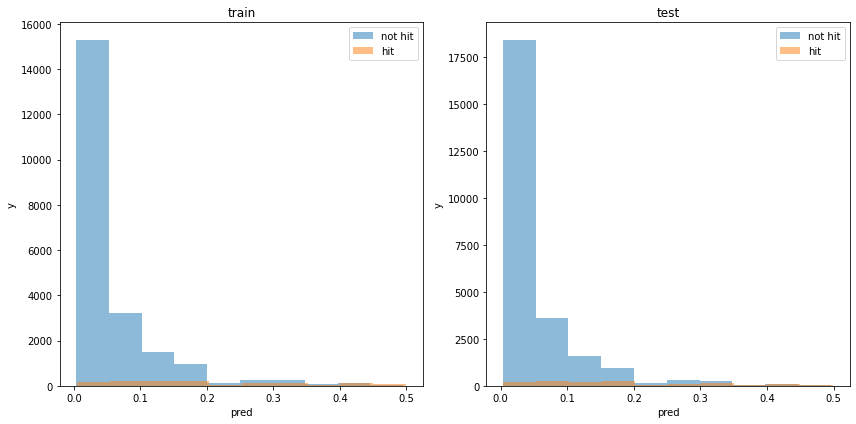
使用した特徴量
利益
テストデータの利益はゼロでした。表示は左から、利益、買った金額、負けた金額(ベット数)です。
train win money :(0.30000000000000004, 1.3, 1)
test win money :(0.0, 0.0, 0)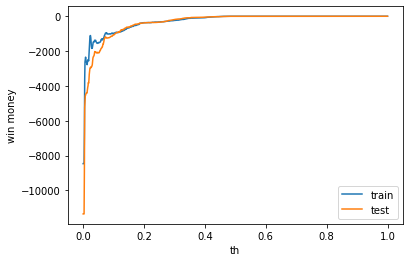
三連単
analysis_ticket_effect('sanrentan')正答率
全く学習できていません。すべて外れると予想した場合(base acc)と同じ正答率です。
train
base acc : 0.9902522700193106
acc : 0.9902522700193106
valid
base acc : 0.9905090595340811
acc : 0.9905090595340811
test
base acc : 0.9913778141426163
acc : 0.9913778141426163モデルの出力分布
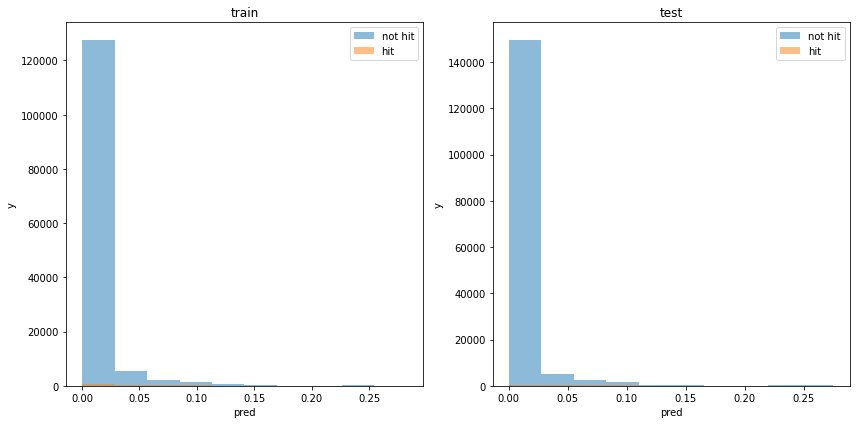
使用した特徴量
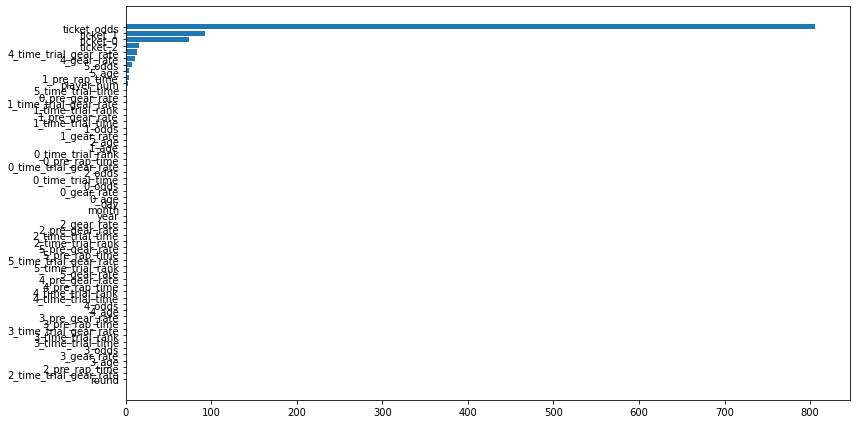
利益
利益はマイナスではありませんでしたが、ベットしないので0でした。
train win money :(0.0, 0.0, 0)
test win money :(0.0, 0.0, 0)
チケットの種類別の分析(オッズ情報を使わない場合)
オッズ情報を利用しない場合の検証もします。
def analysis_ticket_effect(ticket_type):
df = pd.read_pickle(f'/work/learning_data/learning_01_{ticket_type}.pkl')
not_use_columns = ['race_id', 'race_date', 'ticket_odds', 'ticket_hit', 'ticket_payout']
not_use_columns_keywards = ['rank', 'time', 'odds']
analysis_columns_effect(df, not_use_columns, not_use_columns_keywards, ticket_type)単勝
analysis_ticket_effect('tansyo')正答率
train
base acc : 0.8241860465116279
acc : 0.8932093023255814
valid
base acc : 0.8263888888888888
acc : 0.8671875
test
base acc : 0.8314552284017933
acc : 0.8719253604749788モデルの出力分布
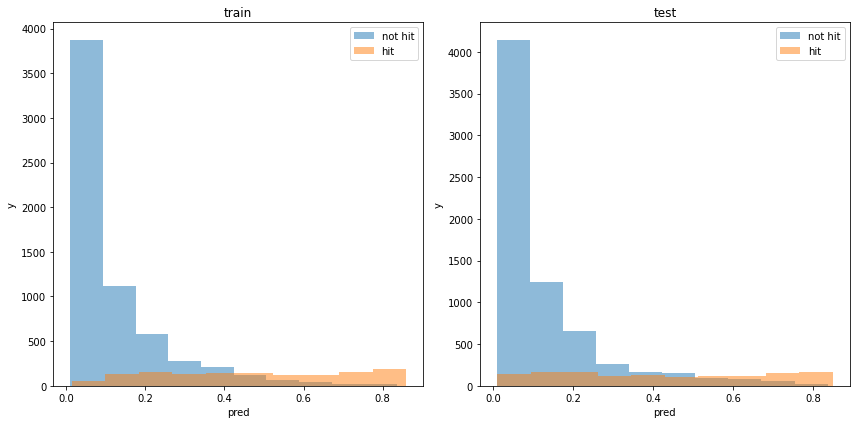
使用した特徴量
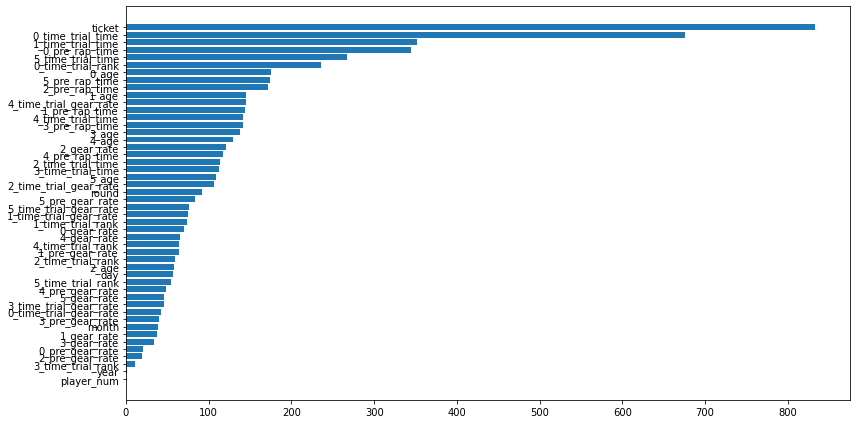
利益
利益はマイナスでした。表示は左から、利益、買った金額、負けた金額(ベット数)です。
train win money :(91.29999999999995, 866.3, 775)
test win money :(-87.39999999999998, 744.6, 832)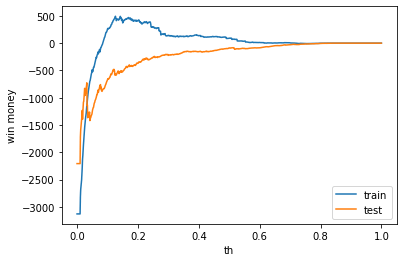
二連複
analysis_ticket_effect('nirenhuku')正答率
train
base acc : 0.9254595228783731
acc : 0.9254595228783731
valid
base acc : 0.9284671532846716
acc : 0.9284671532846716
test
base acc : 0.9317869752844252
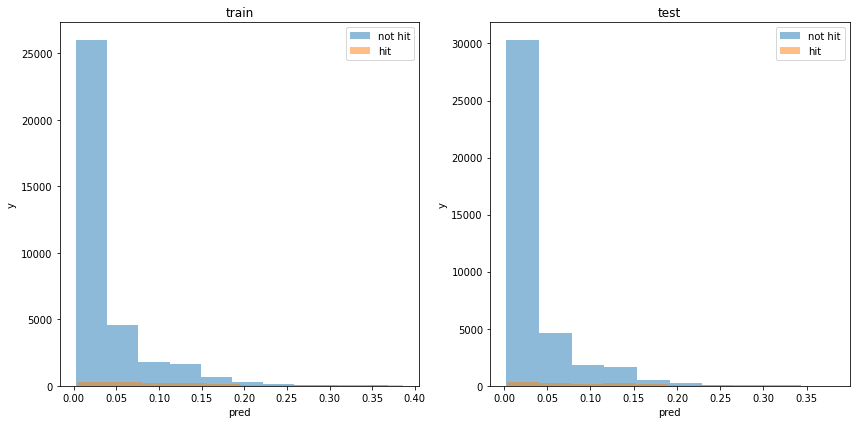
acc : 0.9317869752844252モデルの出力分布
使用した特徴量
利益
利益はゼロでした。表示は左から、利益、買った金額、負けた金額(ベット数)です。
train win money :(0.0, 0.0, 0)
test win money :(0.0, 0.0, 0)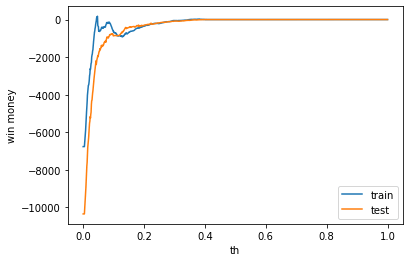
二連単
analysis_ticket_effect('nirentan')正答率
train
base acc : 0.9622619373509054
acc : 0.9622619373509054
valid
base acc : 0.9653253034035952
acc : 0.9653253034035952
test
base acc : 0.9658934876422126
acc : 0.9658934876422126モデルの出力分布
使用した特徴量
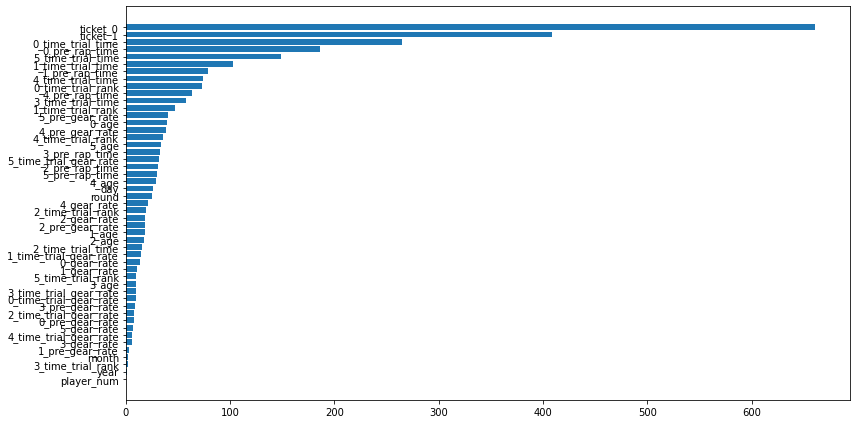
利益
利益はゼロでした。表示は左から、利益、買った金額、負けた金額(ベット数)です。
train win money :(0.0, 0.0, 0)
test win money :(0.0, 0.0, 0)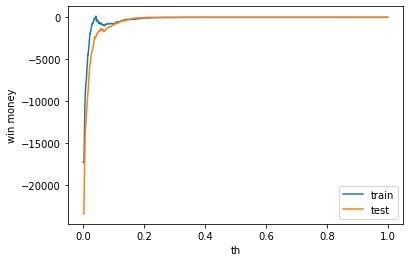
三連複
analysis_ticket_effect('sanrenhuku')正答率
train
base acc : 0.9412054726981388
acc : 0.9412054726981388
valid
base acc : 0.9437733678458441
acc : 0.9437733678458441
test
base acc : 0.9482668848556977
acc : 0.9482668848556977モデルの出力分布
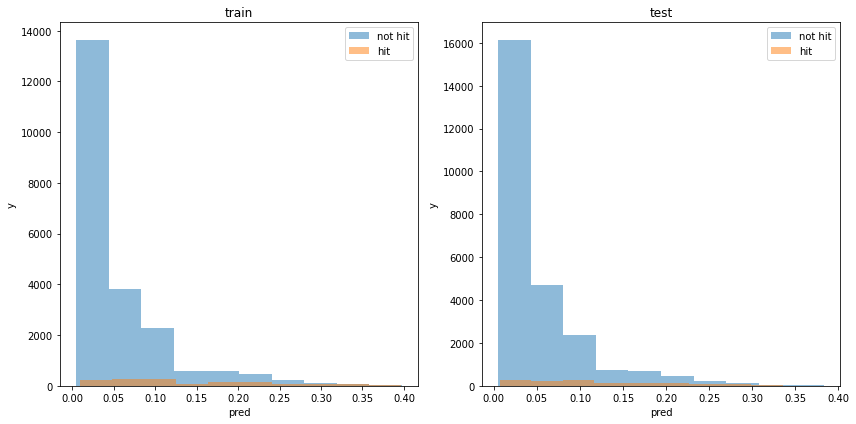
使用した特徴量
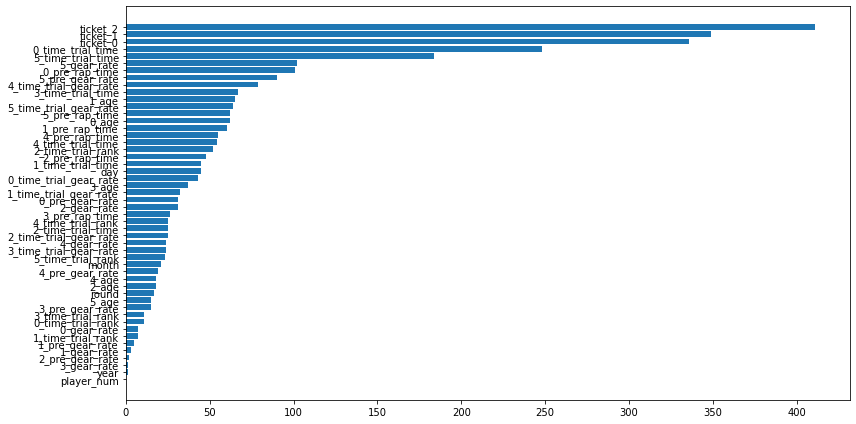
利益
利益はゼロでした。表示は左から、利益、買った金額、負けた金額(ベット数)です。
train win money :(0.0, 0.0, 0)
test win money :(0.0, 0.0, 0)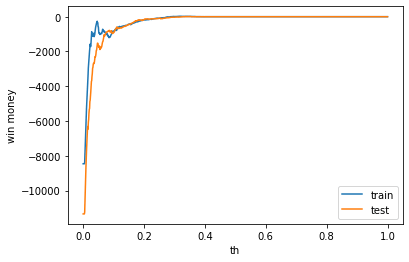
三連単
analysis_ticket_effect('sanrentan')正答率
train
base acc : 0.9903549858252187
acc : 0.9903549858252187
valid
base acc : 0.9902693893202953
acc : 0.9902693893202953
test
base acc : 0.9913778141426163
acc : 0.9913778141426163モデルの出力分布
使用した特徴量
利益
利益はゼロでした。表示は左から、利益、買った金額、負けた金額(ベット数)です。
train win money :(0.0, 0.0, 0)
test win money :(0.0, 0.0, 0)
まとめ
以下に学習ができるか否かについて、まとめます。また、すべての場合で利益はでませんでした。
| オッズ情報を使う | オッズ情報を使わない | |
|---|---|---|
| 単勝 | 学習できる | 学習できる |
| 二連複 | 若干できる | 学習できない |
| 二連単 | 学習できない | 学習できない |
| 三連複 | 学習できない | 学習できない |
| 三連単 | 学習できない | 学習できない |
学習ができなかった理由は、データの不均衡性によるものだと考えられるので、次章では不均衡データの扱いについてまとめます。
