
前回のSection 03-02にて、利益が出る可能性が示唆されました。
そこで、今回は何回か実行してみて、利益が出たのは偶然だったのかを調査します。
また、複数回の試行で得られたモデルをアンサンブルすることで、利益が安定するのかも検証します。
分析するのは
- 単勝
- 二連複
- 二連単
- 三連複
- 三連単
です。
関数
利益の推移を見る関数
利益の推移を確認するための関数を書きました。これで利益の推移が安定的かどうかを確かめました。
def print_win_money_line(models, train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask):
train_payout = not_use_df.loc[train_mask, 'ticket_payout'].reset_index(drop=True)
test_payout = not_use_df.loc[test_mask, 'ticket_payout'].reset_index(drop=True)
train_preds = [model.predict(train_X) for model in models]
test_preds = [model.predict(test_X) for model in models]
train_payout = train_payout.fillna(0)
test_payout = test_payout.fillna(0)
def calc_win_money_line(preds, hit, payout, th=0.5):
bets = np.array([(pred > th).astype(int) for pred in preds])
mode_bet, _ = stats.mode(bets, axis=0)
mode_bet = mode_bet[0]
hit = hit.to_numpy()
payout = payout.to_numpy()
return_money = mode_bet * hit * payout
bet_money = mode_bet
win_money_line = return_money - bet_money
return np.cumsum(win_money_line)
train_win_money_line = calc_win_money_line(train_preds, train_y, train_payout, 0.5)
test_win_money_line = calc_win_money_line(test_preds, test_y, test_payout, 0.5)
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(121)
plt.plot(train_win_money_line, label='train')
plt.legend()
plt.xlabel('tickets(day)')
plt.ylabel('win_money')
plt.subplot(122)
plt.plot(test_win_money_line, label='test')
plt.legend()
plt.xlabel('tickets(day)')
plt.ylabel('win_money')
plt.show()n回試行とアンサンブル、モデルの保存
5回施行して、モデルを保存する関数です。これを前回のanalysis_columns_effectの変わりに使いました。
trial_num = 5
import pickle
def analysis_columns_effect(df, not_use_columns, not_use_columns_keywards, ticket_type):
train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask = make_learning_data(df, not_use_columns, not_use_columns_keywards, ticket_type)
models = []
for n in range(trial_num):
upsampint_X, upsampling_y = up_sampling(train_X, train_y, ticket_type)
model, (lgb_train_X, lgb_train_y, lgb_valid_X, lgb_valid_y) = learning(upsampint_X, upsampling_y)
print_win_money([model], train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask)
print_win_money_line([model], train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask)
models.append(model)
print('---------ensemble result-------')
print_win_money(models, train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask)
print_win_money_line(models, train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask)
with open(f'work/models/lgbm_{ticket_type}.pkl', 'wb') as f:
pickle.dump(models, f)分析
単勝
総利益
各試行の総利益をまとめます。また、最終行に各試行のアンサンブル結果を示しました。
単勝では、何度試行してもテストデータの利益はマイナスでした。
| 学習データ | テストデータ | |
|---|---|---|
| trial 1 | 53.09 | -175.59 |
| trial 2 | 32.39 | -159.0 |
| trial 3 | -5.90 | -170.59 |
| trial 4 | 43.0 | -138.59 |
| trial 5 | 40.29 | -167.0 |
| trials ensemble | 31.0 | -171.39 |
利益の推移
各試行の利益の推移を示します。また、最終行に各試行のアンサンブル結果を示しました。
図の横軸は日付でソートされたチケットであり、時間経過を表すものとして考えてください。縦軸はそれまでの総利益です。
単勝では利益はでなさそうなことがわかります。
| 利益の推移(学習:テスト) | |
|---|---|
| trial 1 | 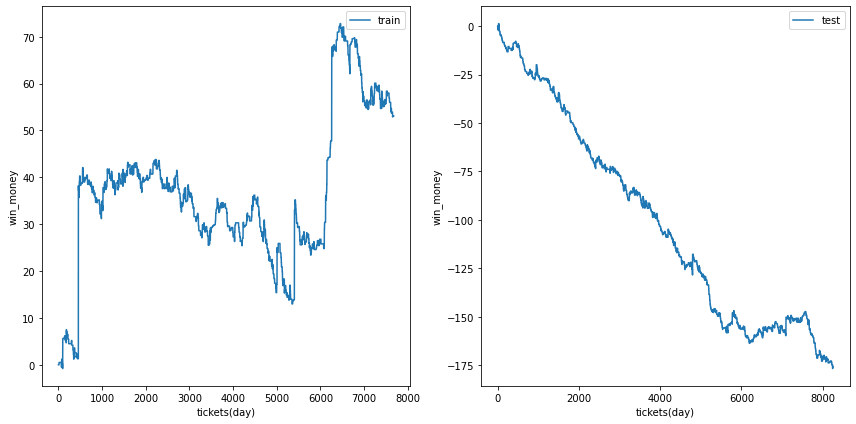 |
| trial 2 | 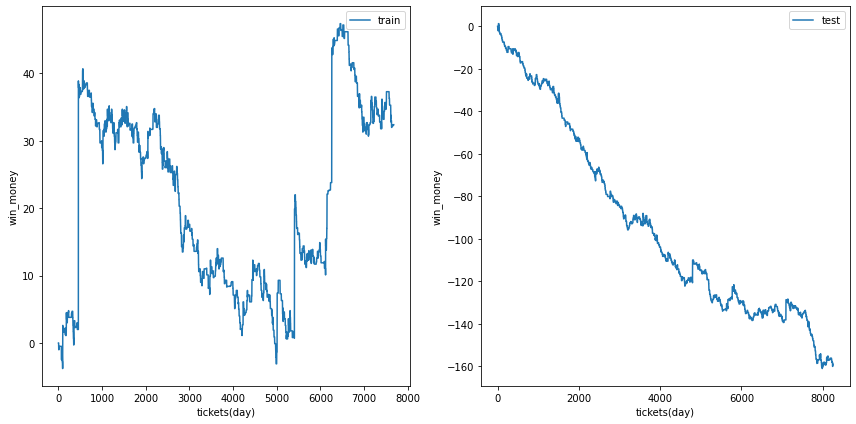 |
| trial 3 | 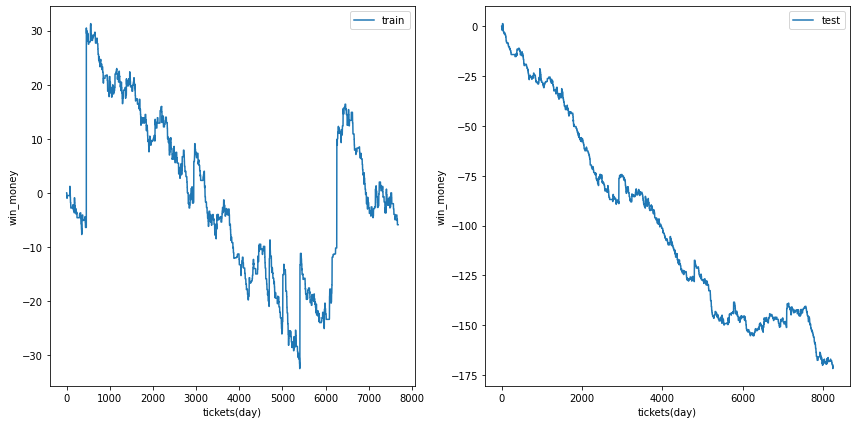 |
| trial 4 | 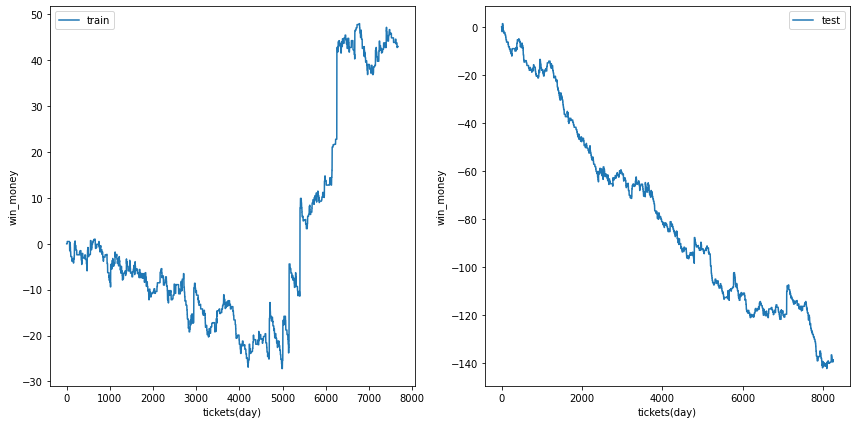 |
| trial 5 | 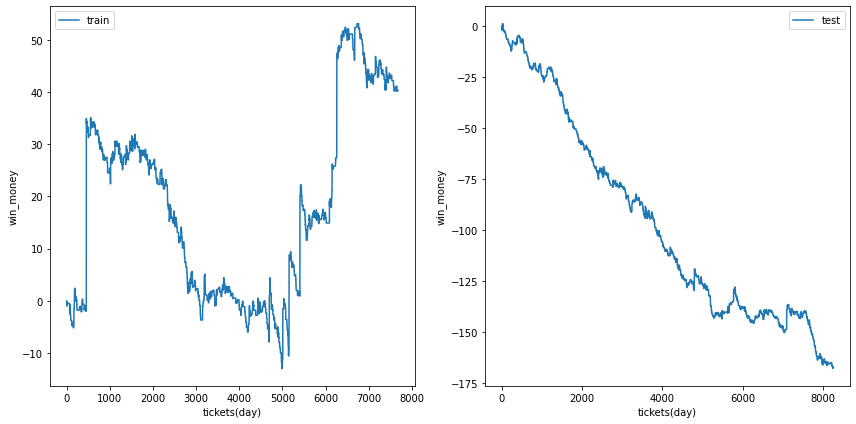 |
| trial ensemble | 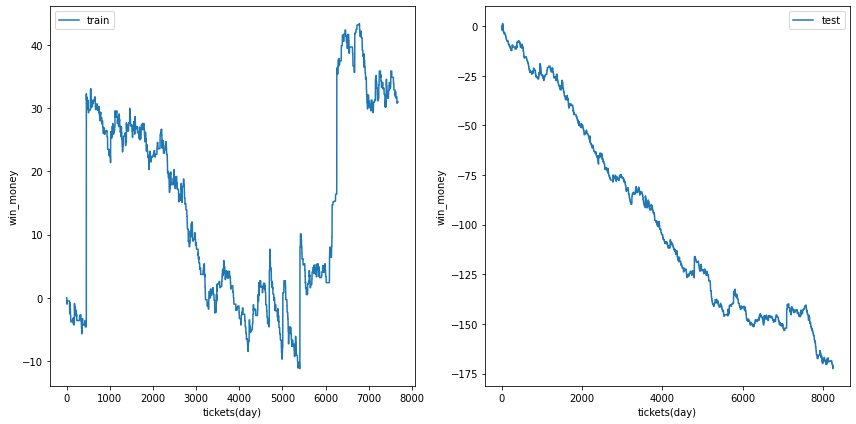 |
二連複
総利益
各試行の総利益をまとめます。また、最終行に各試行のアンサンブル結果を示しました。
二連複では何度かの試行でテストデータの利益がプラスに成ることがありました。
また、アンサンブル結果は学習データ、テストデータの両方で利益がプラスでした。
| 学習データ | テストデータ | |
|---|---|---|
| trial 1 | -3.19 | 0.0 |
| trial 2 | 3.39 | -7.09 |
| trial 3 | -2.40 | 0.59 |
| trial 4 | 6.60 | -8.69 |
| trial 5 | 17.19 | 4.09 |
| trials ensemble | 8.60 | 3.09 |
利益の推移
各試行の利益の推移を示します。また、最終行に各試行のアンサンブル結果を示しました。
図の横軸は日付でソートされたチケットであり、時間経過を表すものとして考えてください。縦軸はそれまでの総利益です。
利益の推移を見ると、確かに利益がプラスの試行でも、かなりブレが大ききく止め時、始め時によっては利益がマイナスになる可能性があることがわかります。
| 利益の推移(学習:テスト) | |
|---|---|
| trial 1 | 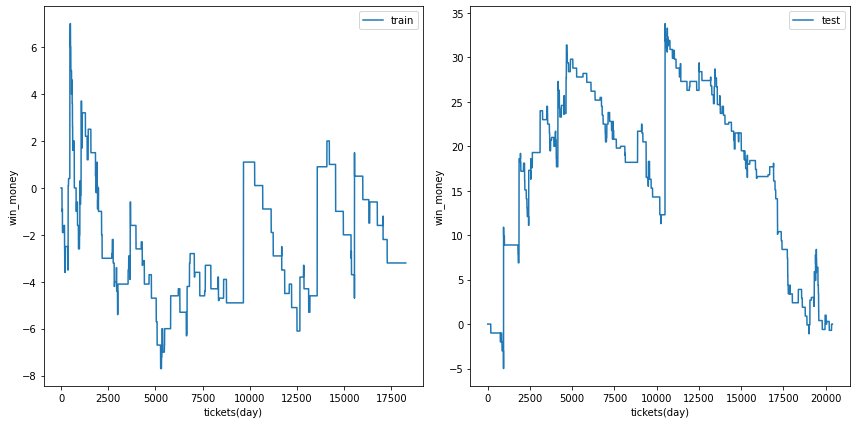 |
| trial 2 | 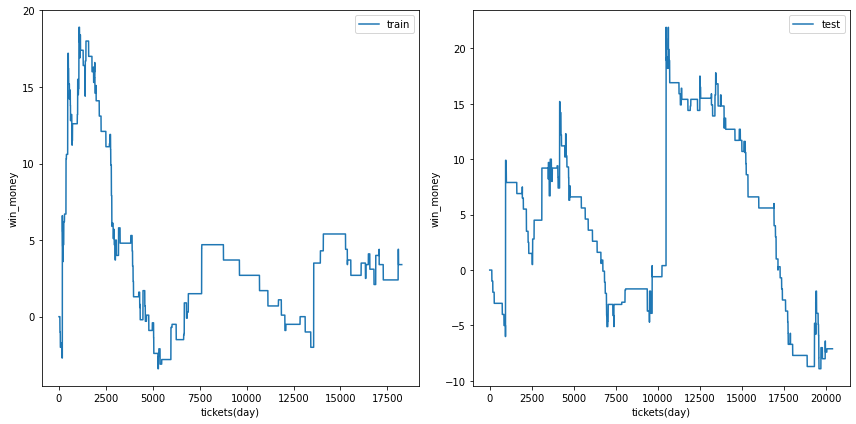 |
| trial 3 | 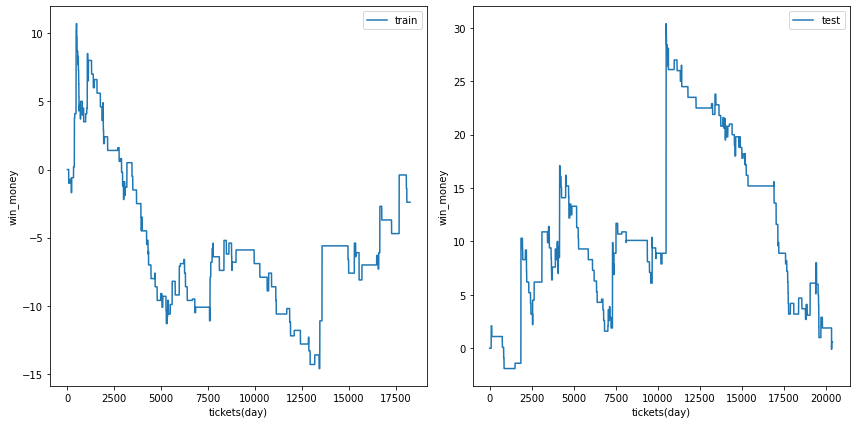 |
| trial 4 | 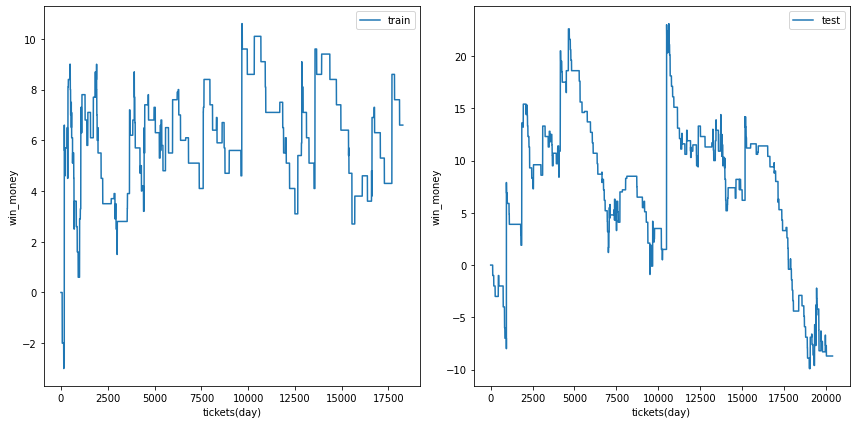 |
| trial 5 | 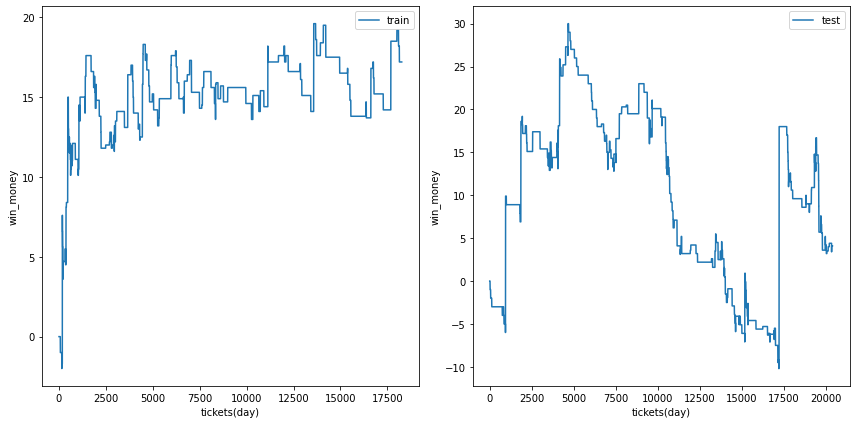 |
| trial ensemble | 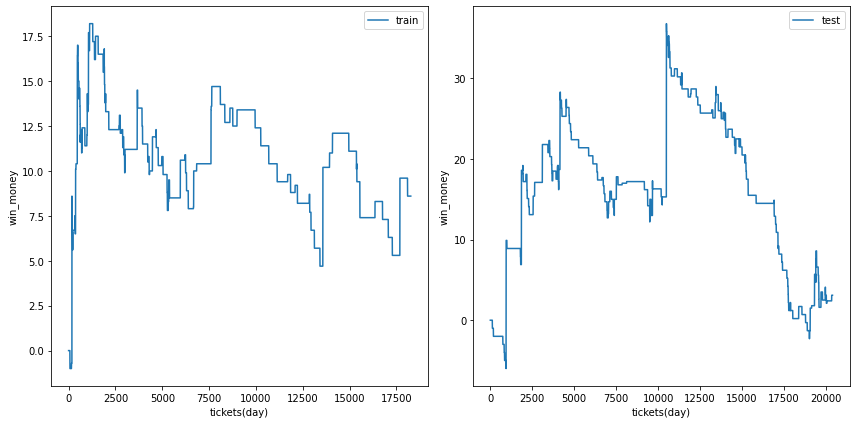 |
二連単
総利益
各試行の総利益をまとめます。また、最終行に各試行のアンサンブル結果を示しました。
二連単では何度かの試行でテストデータの利益がプラスに成ることがありました。
また、アンサンブル結果はテストデータでの利益がプラスでした。
| 学習データ | テストデータ | |
|---|---|---|
| trial 1 | 6.39 | 14.0 |
| trial 2 | -4.9 | 11.0 |
| trial 3 | 2.80 | 33.40 |
| trial 4 | 2.80 | 21.40 |
| trial 5 | 1.5 | 5.79 |
| trials ensemble | -3.09 | 30.79 |
利益の推移
各試行の利益の推移を示します。また、最終行に各試行のアンサンブル結果を示しました。
図の横軸は日付でソートされたチケットであり、時間経過を表すものとして考えてください。縦軸はそれまでの総利益です。
利益の推移を見ると、確かにプラスですが、前半に大きく利益を稼いだだけであり、後半は利益が出ていないことがあります。
| 利益の推移(学習:テスト) | |
|---|---|
| trial 1 | 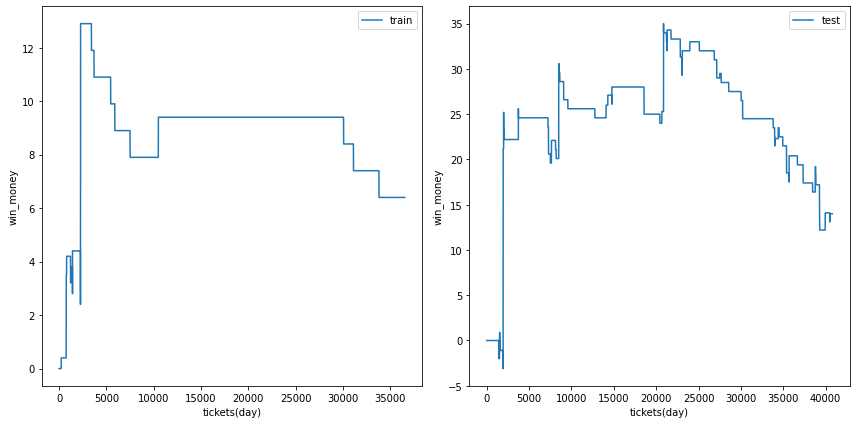 |
| trial 2 |  |
| trial 3 | 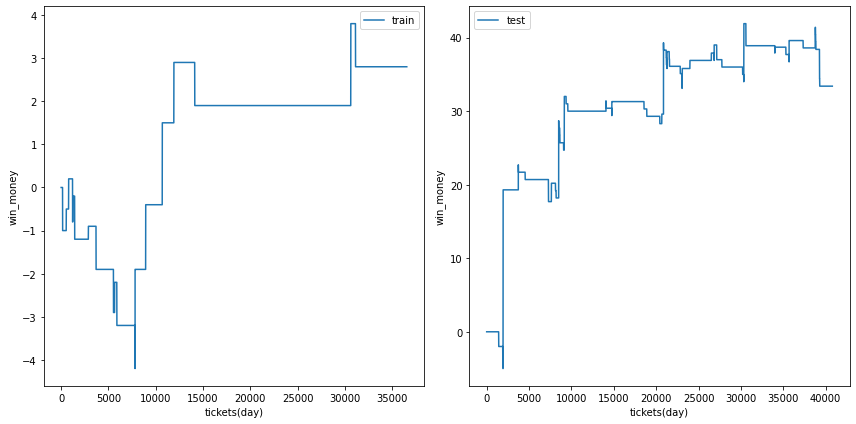 |
| trial 4 | 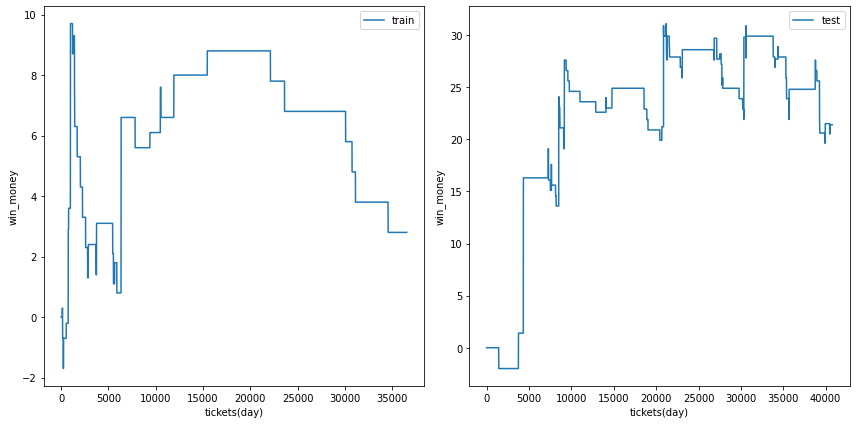 |
| trial 5 | |
| trial ensemble | 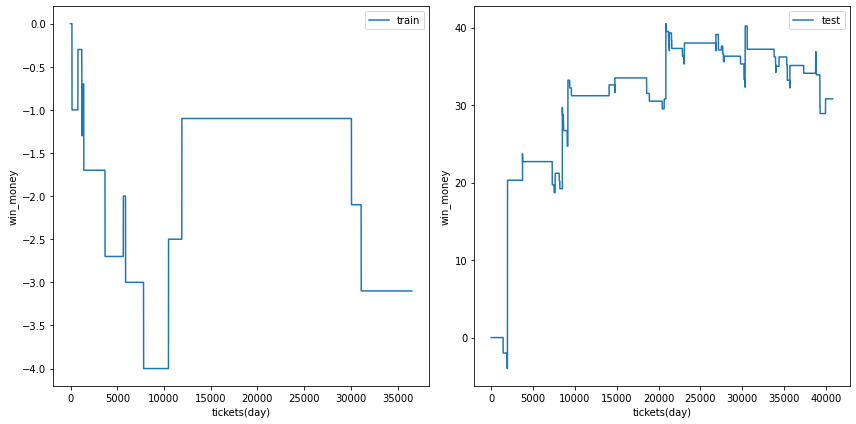 |
三連複
総利益
各試行の総利益をまとめます。また、最終行に各試行のアンサンブル結果を示しました。
三連複では何度かの試行でテストデータの利益がプラスに成ることがありました。
また、アンサンブル結果は学習データ、テストデータの両方で利益がプラスでした。
| 学習データ | テストデータ | |
|---|---|---|
| trial 1 | -4.40 | 16.69 |
| trial 2 | -22.0 | -11.5 |
| trial 3 | 6.59 | -35.7 |
| trial 4 | -12.09 | -4.40 |
| trial 5 | 14.30 | 7.70 |
| trials ensemble | 10.10 | 7.60 |
利益の推移
各試行の利益の推移を示します。また、最終行に各試行のアンサンブル結果を示しました。
図の横軸は日付でソートされたチケットであり、時間経過を表すものとして考えてください。縦軸はそれまでの総利益です。
利益の推移を見ると、確かにプラスですが、勝った時の上昇幅が大きいだけであり、基本的に負け続けていることがわかります。
| 利益の推移(学習:テスト) | |
|---|---|
| trial 1 | 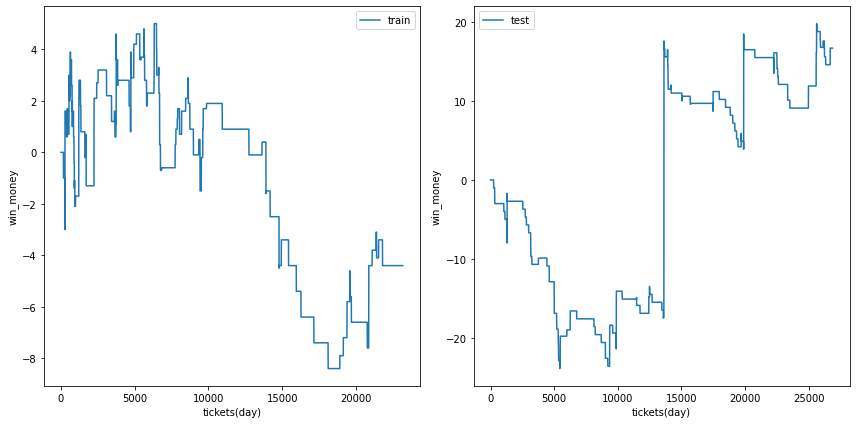 |
| trial 2 | 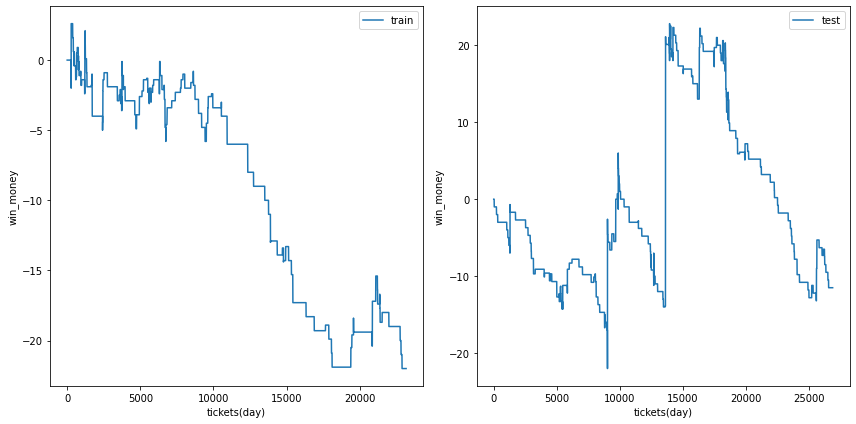 |
| trial 3 | 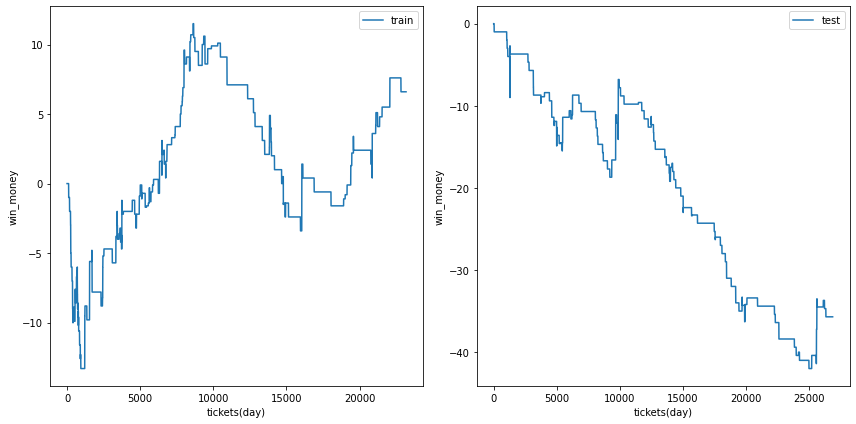 |
| trial 4 | 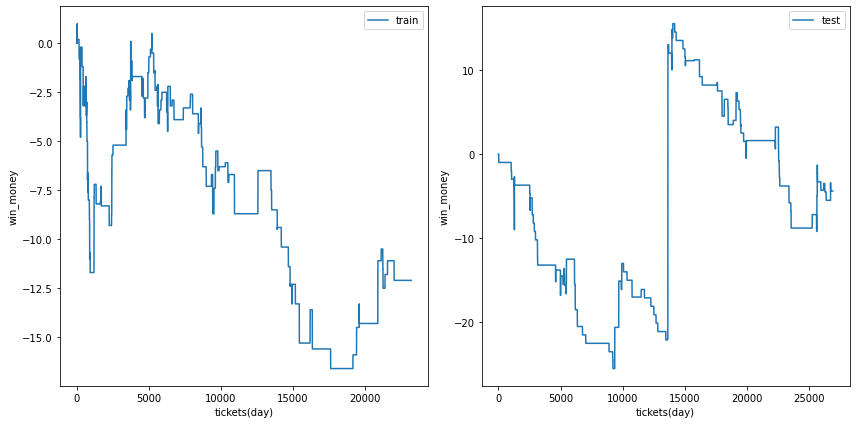 |
| trial 5 | 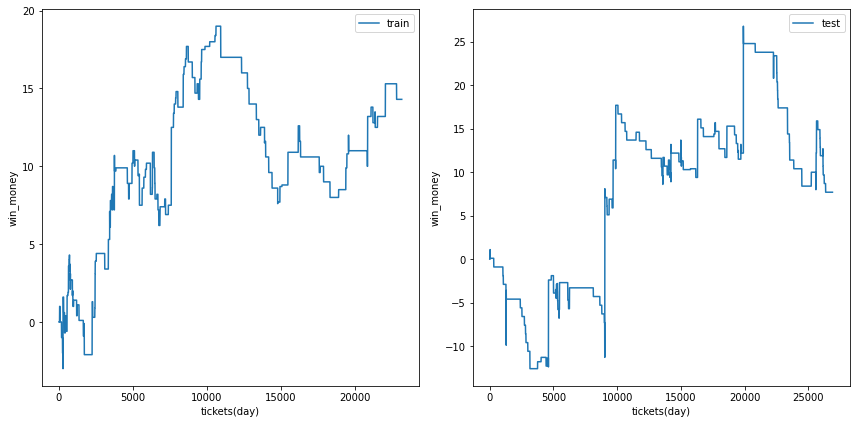 |
| trial ensemble | 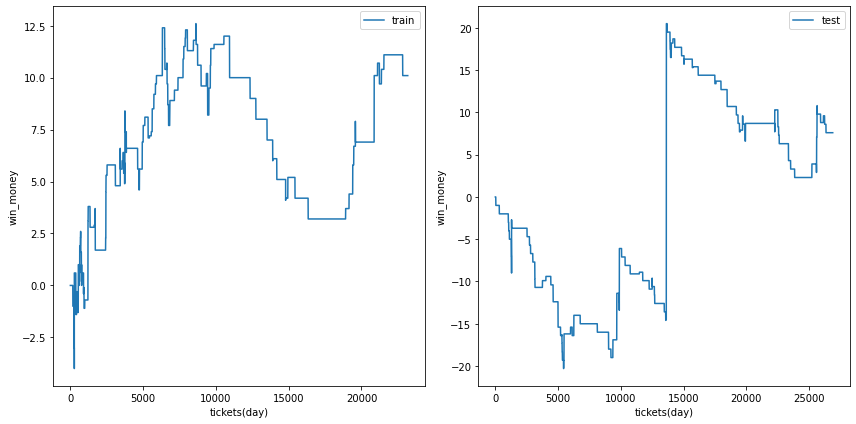 |
三連単
総利益
各試行の総利益をまとめます。また、最終行に各試行のアンサンブル結果を示しました。
三連複では何度かの試行でテストデータの利益がプラスに成ることがありました。
また、アンサンブル結果はテストデータの利益がプラスでした。
| 学習データ | テストデータ | |
|---|---|---|
| trial 1 | 0.0 | 36.8 |
| trial 2 | 0.0 | 50.80 |
| trial 3 | 0.0 | 40.2 |
| trial 4 | -1.0 | -13.0 |
| trial 5 | 0.0 | 49.5 |
| trials ensemble | 0.0 | 40.2 |
利益の推移
各試行の利益の推移を示します。また、最終行に各試行のアンサンブル結果を示しました。
図の横軸は日付でソートされたチケットであり、時間経過を表すものとして考えてください。縦軸はそれまでの総利益です。
利益の推移を見ると、確かにプラスですが、ベット数が少なく、安定的に勝っているとは言えない状況です。
| 利益の推移(学習:テスト) | |
|---|---|
| trial 1 | 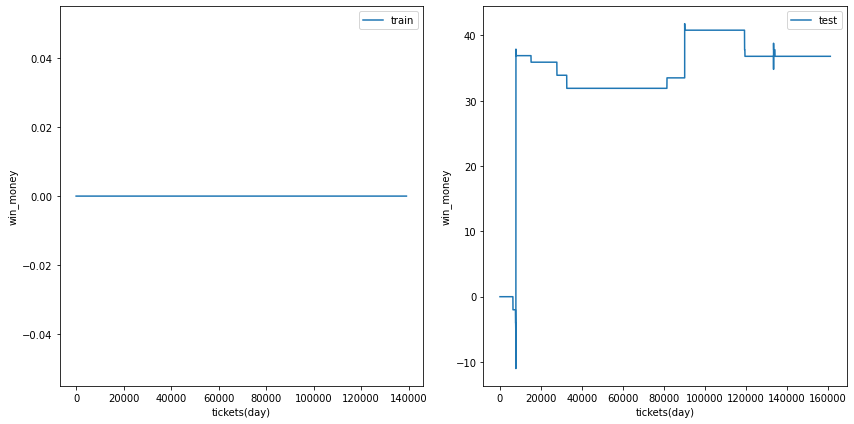 |
| trial 2 | 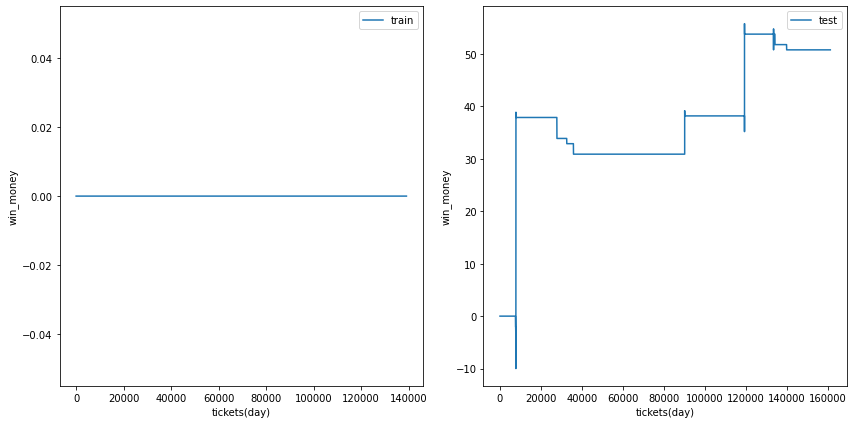 |
| trial 3 | 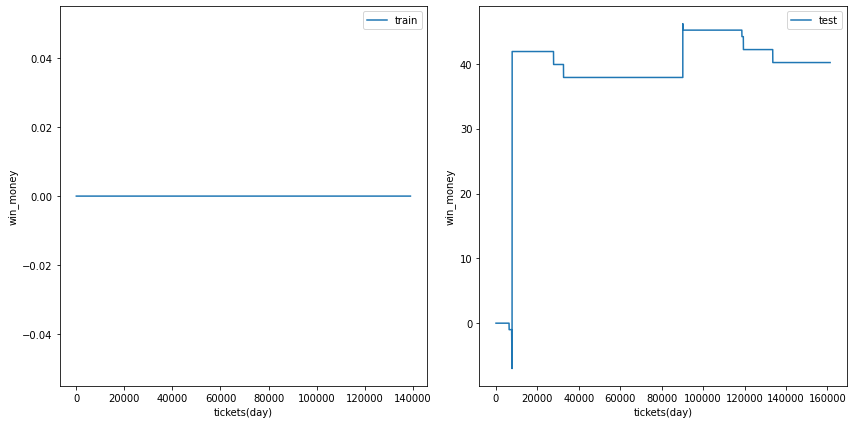 |
| trial 4 |  |
| trial 5 | 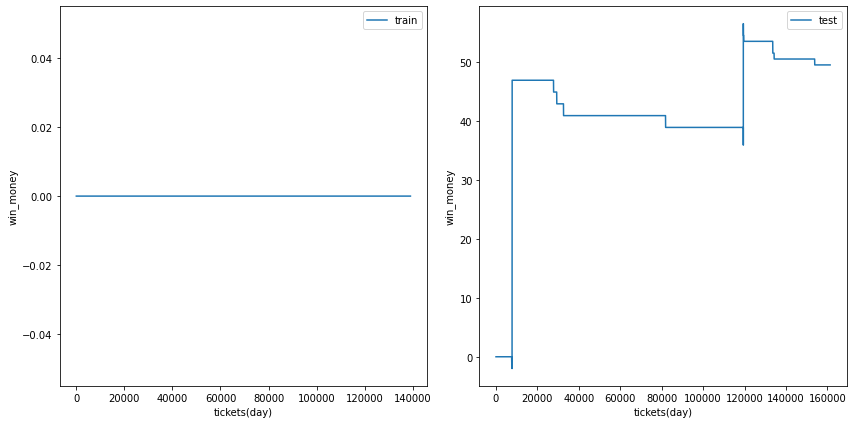 |
| trial ensemble | 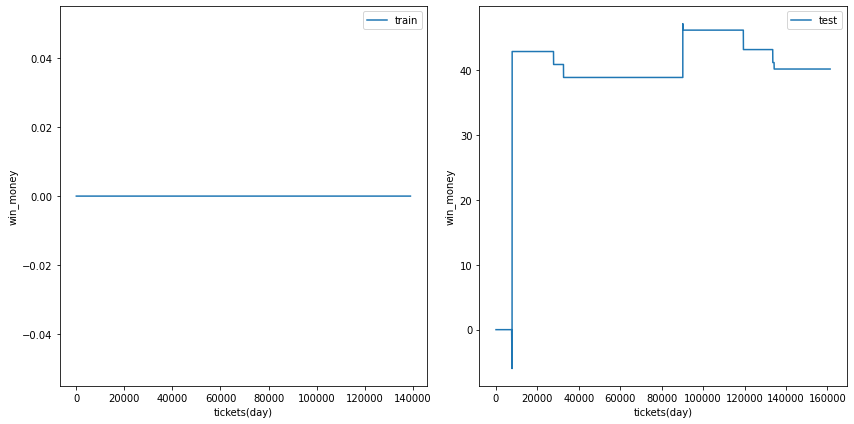 |
まとめ
- 単勝では利益は出ないことを確かめました。
- 二連複、二連単、三連複、三連単で複数回試行し、利益が偶然出たわけではないことを確かめました。
- しかし、利益の推移を確認すると、安定的に利益が増えているわけではないことも確認しました。
次回はモデルのベット閾値(現在は0.5)を変化させて、利益の推移が安定するかを確かめたいと思います。
