
はじめに、jupyter notebook形式でlightGBMによる学習を行い、学習ができるのか、および評価項目が動作するかをチェックします。
その後のSectionでは、各ブロックを関数化し検証を行います。
前処理
まず、使いそうなライブラリをインポートします。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np学習データの読み込みます。正しく読み込めていれば、テーブルデータが表示されます。
df = pd.read_pickle('/work/learning_data/learning_01_tansyo.pkl')
dfこのテーブルデータの列名を見て、必要な特徴量および教師データ、付随データがあることを確認します。
print(list(df.columns))読み込んだDataFrameを学習データとテストデータに分割します。分割点は2023年を堺に分割しました。
その後、入力データをStandardScalerで標準化します。
また、カテゴリー変数を指定し、カテゴリー変数は標準化前のデータに戻します。
df['race_date'] = pd.to_datetime(df['race_date'])
not_use_columns = ['race_id', 'race_date', 'ticket_odds', 'ticket_hit', 'ticket_payout']
not_use_columns_keywards = ['rank', 'time', 'odds', 'pre_rap_time', 'pre_gear_rate']
for i in range(6):
for col_keyward in not_use_columns_keywards:
not_use_columns.append(f'{i}_{col_keyward}')
not_use_df = df[not_use_columns]
input_df = df.drop(columns=not_use_columns)
input_df = input_df.apply(pd.to_numeric, args=('coerce',))
train_mask = not_use_df['race_date'] < '2023-01-01'
test_mask = not_use_df['race_date'] >= '2023-01-01'
train_input_df = input_df.loc[train_mask, :].reset_index(drop=True)
test_input_df = input_df.loc[test_mask, :].reset_index(drop=True)
from sklearn.preprocessing import StandardScaler
categorical_columns = ['round', 'year', 'month', 'day', 'player_num', 'ticket']
scaler = StandardScaler()
train_X = pd.DataFrame(data=scaler.fit_transform(train_input_df), columns=train_input_df.columns)
test_X = pd.DataFrame(data=scaler.transform(test_input_df), columns=test_input_df.columns)
for col in categorical_columns:
train_X.loc[:, col] = train_input_df.loc[:, col].astype('int64')
test_X.loc[:, col] = test_input_df.loc[:, col].astype('int64')
train_y = not_use_df.loc[train_mask, 'ticket_hit'].reset_index(drop=True).astype('int64')
test_y = not_use_df.loc[test_mask, 'ticket_hit'].reset_index(drop=True).astype('int64')学習
学習器にデータを与えます。学習データを更に学習用とバリデーション用に分割し、early_stoppingがかかるようにします。
学習器はoptunaのlightgbmtureを使います。自動的にパラメータチューンまで済ましてくれるので楽です。
import optuna.integration.lightgbm as lgb
#import lightgbm as lgb
params = {
'objective': 'binary',
'metric': 'binary_logloss',
'learning_rate': 0.01,
}
num_round = 10000
from sklearn.model_selection import train_test_split
lgb_train_X, lgb_valid_X, lgb_train_y, lgb_valid_y = train_test_split(train_X, train_y, test_size=0.3)
lgb_train_X = lgb_train_X.reset_index(drop=True)
lgb_valid_X = lgb_valid_X.reset_index(drop=True)
lgb_train_y = lgb_train_y.reset_index(drop=True)
lgb_valid_y = lgb_valid_y.reset_index(drop=True)
lgb_train = lgb.Dataset(lgb_train_X, lgb_train_y)
lgb_eval = lgb.Dataset(lgb_valid_X, lgb_valid_y)
# training
model = lgb.train(params, lgb_train,
num_boost_round=num_round,
valid_sets=[lgb_train, lgb_eval],
valid_names=['train', 'valid'],
callbacks=[lgb.early_stopping(stopping_rounds=10, verbose=1)]
)
accuracy = lambda a, b : np.sum(a==b)/len(a)
lgb_train_pred = (model.predict(lgb_train_X) > 0.5).astype(int)
lgb_valid_pred = (model.predict(lgb_valid_X) > 0.5).astype(int)
test_pred = (model.predict(test_X) > 0.5).astype(int)
print(f'train base acc : {accuracy(np.zeros_like(lgb_train_y), lgb_train_y)}')
print(f'train acc : {accuracy(lgb_train_pred, lgb_train_y)}')
print(f'valid base acc : {accuracy(np.zeros_like(lgb_valid_y), lgb_valid_y)}')
print(f'valid acc : {accuracy(lgb_valid_pred, lgb_valid_y)}')
print(f'test base acc : {accuracy(np.zeros_like(test_y), test_y)}')
print(f'test acc : {accuracy(test_pred, test_y)}')学習が終わると、accuracyが表示されます。
予測しない場合のテストaccuracyが0.831、予測器のテストaccuracyが0.8711なので、学習はできているようです。
train base acc : 0.8178604651162791
train acc : 0.9013953488372093
valid base acc : 0.8411458333333334
valid acc : 0.8797743055555556
test base acc : 0.8314552284017933
test acc : 0.8711983521143827分析
学習器の出力分布を見てみます。
train_pred_p = model.predict(train_X)
test_pred_p = model.predict(test_X)
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(121)
plt.hist(train_pred_p[train_y==0], bins=10, label='not hit', alpha=0.5)
plt.hist(train_pred_p[train_y==1], bins=10, label='hit', alpha=0.5)
plt.legend()
plt.title('train')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(122)
plt.hist(test_pred_p[test_y==0], bins=10, label='not hit', alpha=0.5)
plt.hist(test_pred_p[test_y==1], bins=10, label='hit', alpha=0.5)
plt.legend()
plt.title('test')
plt.xlabel('pred')
plt.ylabel('y')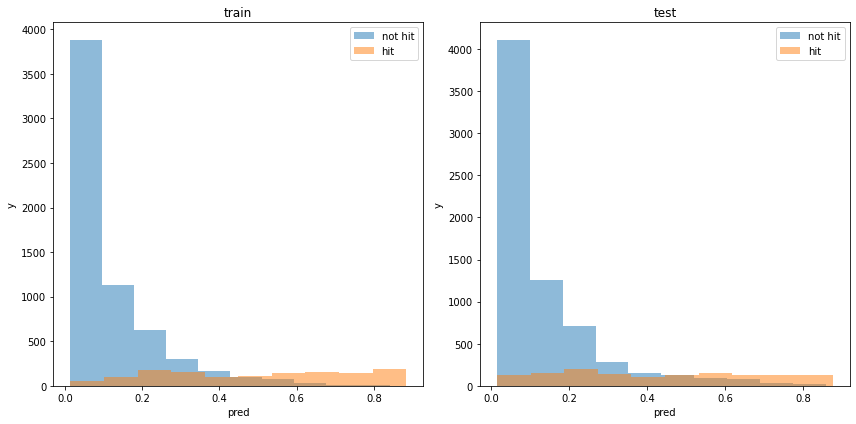
割と分類できている様に見えます。ただし、PIST6は予測しやすいことでも有名なので、妥当な結果です。
学習器が利用した特徴量を見てみます。
importance = pd.DataFrame(model.feature_importance(), index=train_X.columns, columns=['importance'])
importance = importance.sort_values(['importance'])
plt.figure(tight_layout=True, figsize=(12, 6))
plt.barh(importance.index, importance['importance'], align="center")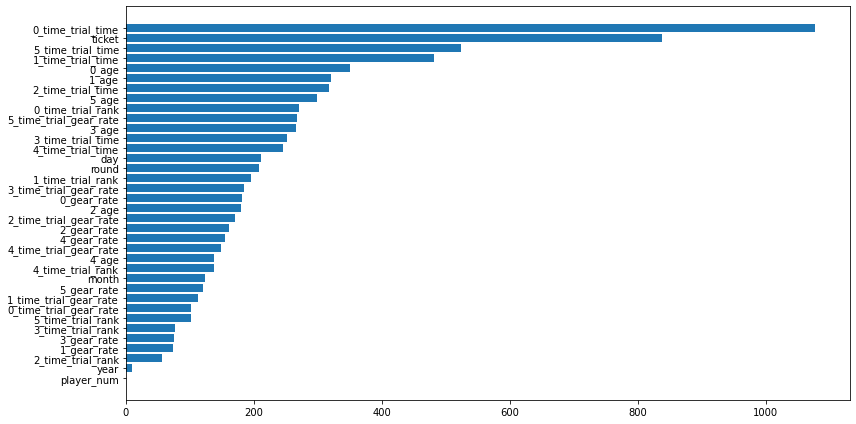
x_time_trial_timeやticketが有効な特徴量として候補に上がるみたいです。x_ageも上位に入ってきています。
やはり、タイムトライアルが早い人のチケットが当たるように予測しているみたいですね。
次に、この予測器に基づいてベットした場合の利益を見てみます。
train_payout = not_use_df.loc[train_mask, 'ticket_payout'].reset_index(drop=True)
test_payout = not_use_df.loc[test_mask, 'ticket_payout'].reset_index(drop=True)
def calc_win_money(pred, hit, payout, th=0.5):
bet = (pred > th).astype(int)
hit = hit.to_numpy()
payout = payout.to_numpy()
return_money = np.sum(bet * hit * payout)
bet_money = np.sum(bet)
win_money = return_money - bet_money
return win_money, return_money, bet_money
print(f'train win money :{calc_win_money(train_pred_p, train_y, train_payout, 0.5)}')
print(f'test win money :{calc_win_money(test_pred_p, test_y, test_payout, 0.5)}')実行すると次の表示が得られます。カッコ内の数字は右から、利益、払い戻し金額、支払った金額(ベット数)です。
train win money :(80.29999999999995, 908.3, 828)
test win money :(-102.39999999999998, 723.6, 826)学習データだと利益がでましたが、テストデータでは利益がでませんでした。
ベットするしきい値を変えた時の利益の推移を見てみます。
train_win_list = []
test_win_list = []
th_list = np.linspace(0.0, 1.0, 1000)
for th in th_list:
train_win_list.append(calc_win_money(train_pred_p, train_y, train_payout, th)[0])
test_win_list.append(calc_win_money(test_pred_p, test_y, test_payout, th)[0])
plt.plot(th_list, train_win_list, label='train')
plt.plot(th_list, test_win_list, label='test')
plt.legend()
plt.xlabel('th')
plt.ylabel('win money')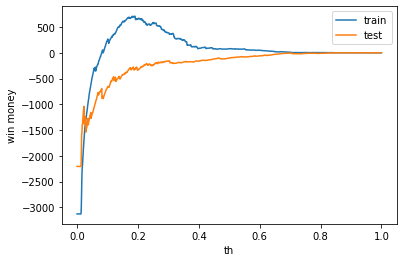
利益0以上で拡大してみます。
train_win_list = []
test_win_list = []
th_list = np.linspace(0.0, 1.0, 1000)
for th in th_list:
train_win_list.append(calc_win_money(train_pred_p, train_y, train_payout, th)[0])
test_win_list.append(calc_win_money(test_pred_p, test_y, test_payout, th)[0])
plt.plot(th_list, train_win_list, label='train')
plt.plot(th_list, test_win_list, label='test')
plt.legend()
plt.xlabel('th')
plt.ylabel('win money')
plt.ylim([0, max(max(train_win_list), max(test_win_list))])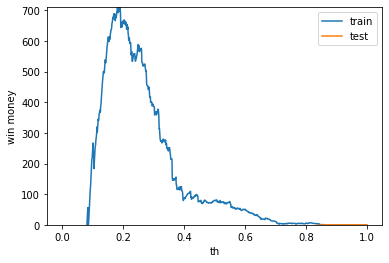
テストデータの利益はしきい値変えてもでなさそうです。
