
基本的にほとんどSection 02-02と同じです。データを水増しする関数を追加するだけです。
検証するチケットの種類は
- 単勝
- 二連複
- 二連単
- 三連複
- 三連単
の5種類です。
不均衡データを均衡がとれるように水増しするので、データ数は二倍弱増えます。その分計算時間がかかります。
使いそうなライブラリをインポートします。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np関数定義
前処理
from sklearn.preprocessing import StandardScaler
def make_learning_data(df, not_use_columns, not_use_columns_keywards, ticket_type):
df['race_date'] = pd.to_datetime(df['race_date'])
if ticket_type == 'wide':
ticket_odds_df = df['ticket_odds'].str.split('\n~', expand=True).rename(columns={0:'ticket_odds_min',1:'ticket_odds_max'})
df['ticket_odds_min'] = ticket_odds_df['ticket_odds_min']
df['ticket_odds_max'] = ticket_odds_df['ticket_odds_max']
if 'ticket_odds' in not_use_columns:
not_use_columns.remove('ticket_odds')
not_use_columns.append('ticket_odds_min')
not_use_columns.append('ticket_odds_max')
#not_use_columns = ['race_id', 'race_date', 'ticket_odds', 'ticket_hit', 'ticket_payout']
#not_use_columns_keywards = ['rank', 'time']
for i in range(6):
for col_keyward in not_use_columns_keywards:
not_use_columns.append(f'{i}_{col_keyward}')
not_use_df = df[not_use_columns]
input_df = df.drop(columns=not_use_columns)
input_df = input_df.apply(pd.to_numeric, args=('coerce',))
for i in range(6):
if f'{i}_odds' in input_df.columns:
zero_mask = input_df[f'{i}_odds'] < 1.0
input_df[f'{i}_odds'] = np.log(input_df[f'{i}_odds'])
input_df.loc[zero_mask, f'{i}_odds'] = np.nan
if 'ticket_odds' in input_df.columns:
zero_mask = input_df['ticket_odds'] < 1.0
input_df['ticket_odds'] = np.log(input_df['ticket_odds'])
input_df.loc[zero_mask, 'ticket_odds'] = np.nan
train_mask = not_use_df['race_date'] < '2023-01-01'
test_mask = not_use_df['race_date'] >= '2023-01-01'
train_input_df = input_df.loc[train_mask, :].reset_index(drop=True)
test_input_df = input_df.loc[test_mask, :].reset_index(drop=True)
categorical_columns = ['round', 'year', 'month', 'day', 'player_num', 'ticket']
if ticket_type != 'tansyo':
categorical_columns.remove('ticket')
for n in range(3):
col = f'ticket_{n}'
if col in input_df.columns:
categorical_columns.append(col)
scaler = StandardScaler()
train_X = pd.DataFrame(data=scaler.fit_transform(train_input_df), columns=train_input_df.columns)
test_X = pd.DataFrame(data=scaler.transform(test_input_df), columns=test_input_df.columns)
for col in categorical_columns:
train_X.loc[:, col] = train_input_df.loc[:, col].astype('int64')
test_X.loc[:, col] = test_input_df.loc[:, col].astype('int64')
train_y = not_use_df.loc[train_mask, 'ticket_hit'].reset_index(drop=True).astype('int64')
test_y = not_use_df.loc[test_mask, 'ticket_hit'].reset_index(drop=True).astype('int64')
return train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask水増し(Up-Sampling)
from imblearn.over_sampling import SMOTENC
from collections import Counter
def up_sampling(train_X, train_y, ticket_type):
print(f'Original dataset samples per class {Counter(train_y)}')
categorical_columns = ['round', 'year', 'month', 'day', 'player_num', 'ticket']
if ticket_type != 'tansyo':
categorical_columns.remove('ticket')
for n in range(3):
col = f'ticket_{n}'
if col in train_X.columns:
categorical_columns.append(col)
sm = SMOTENC(categorical_features=categorical_columns)
upsampling_X, upsampling_y = sm.fit_resample(train_X.fillna(0), train_y)
print(f'Resampled dataset samples per class {Counter(upsampling_y)}')
return upsampling_X, upsampling_y学習
import optuna.integration.lightgbm as lgb
def learning(train_X, train_y):
#import lightgbm as lgb
params = {
'objective': 'binary',
'metric': 'binary_logloss',
'learning_rate': 0.01,
}
num_round = 10000
from sklearn.model_selection import train_test_split
lgb_train_X, lgb_valid_X, lgb_train_y, lgb_valid_y = train_test_split(train_X, train_y, test_size=0.3)
lgb_train_X = lgb_train_X.reset_index(drop=True)
lgb_valid_X = lgb_valid_X.reset_index(drop=True)
lgb_train_y = lgb_train_y.reset_index(drop=True)
lgb_valid_y = lgb_valid_y.reset_index(drop=True)
lgb_train = lgb.Dataset(lgb_train_X, lgb_train_y)
lgb_eval = lgb.Dataset(lgb_valid_X, lgb_valid_y)
# training
model = lgb.train(params, lgb_train,
num_boost_round=num_round,
valid_sets=[lgb_train, lgb_eval],
valid_names=['train', 'valid'],
callbacks=[lgb.early_stopping(stopping_rounds=10, verbose=0)]
)
return model, (lgb_train_X, lgb_train_y, lgb_valid_X, lgb_valid_y)正答率の表示
def accuracy_print(model, X, y):
accuracy = lambda a, b : np.sum(a==b)/len(a)
pred = (model.predict(X) > 0.5).astype(int)
print(f' base acc : {accuracy(np.zeros_like(y), y)}')
print(f' acc : {accuracy(pred, y)}')モデルの出力分布の表示
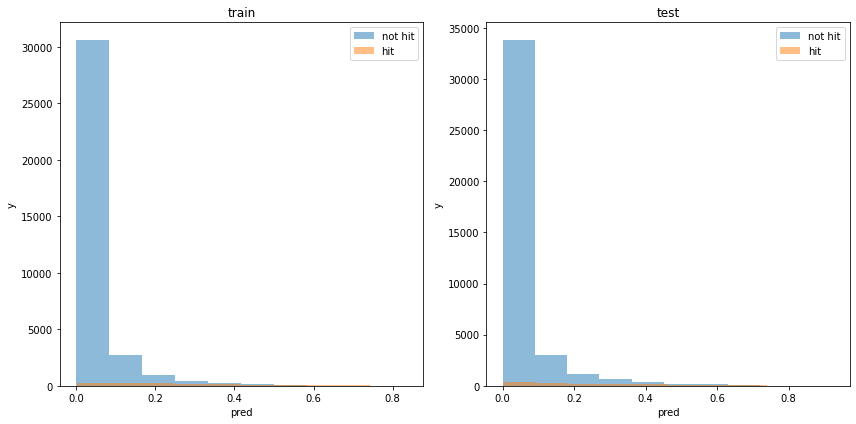
def print_model_p(model, train_X, train_y, test_X, test_y):
train_pred_p = model.predict(train_X)
test_pred_p = model.predict(test_X)
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(121)
plt.hist(train_pred_p[train_y==0], bins=10, label='not hit', alpha=0.5)
plt.hist(train_pred_p[train_y==1], bins=10, label='hit', alpha=0.5)
plt.legend()
plt.title('train')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(122)
plt.hist(test_pred_p[test_y==0], bins=10, label='not hit', alpha=0.5)
plt.hist(test_pred_p[test_y==1], bins=10, label='hit', alpha=0.5)
plt.legend()
plt.title('test')
plt.xlabel('pred')
plt.ylabel('y')
plt.show()使用した特徴量の表示
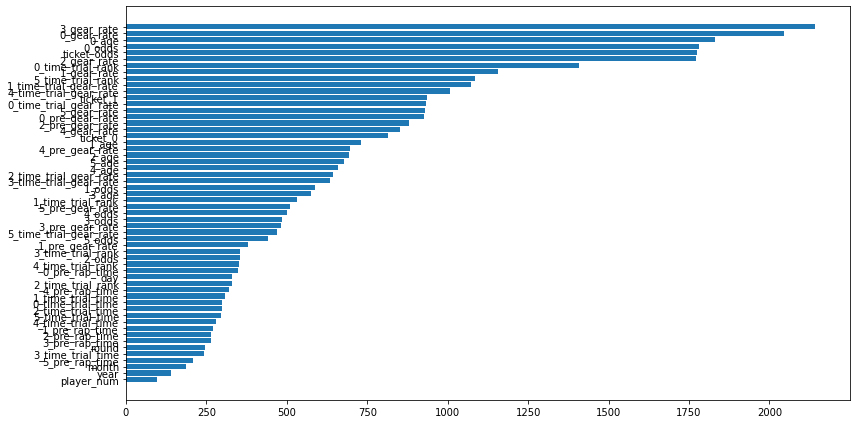
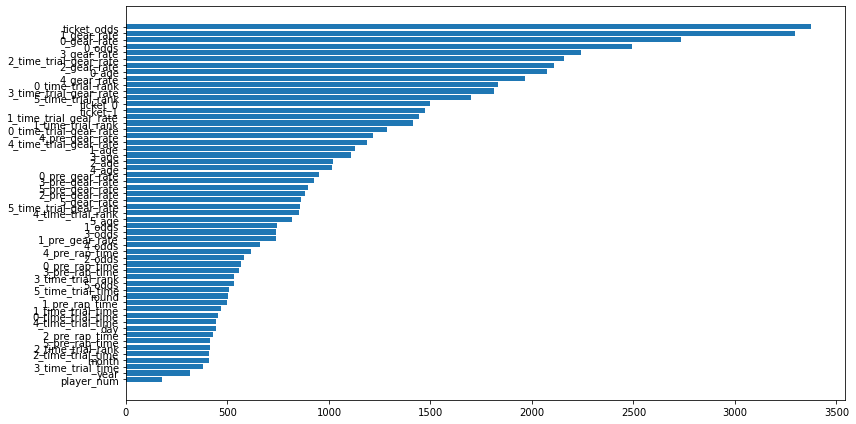
def print_feature_importance(model, X):
importance = pd.DataFrame(model.feature_importance(), index=X.columns, columns=['importance'])
importance = importance.sort_values(['importance'])
plt.figure(tight_layout=True, figsize=(12, 6))
plt.barh(importance.index, importance['importance'], align="center")
plt.show()利益の表示
def print_win_money(model, train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask):
train_payout = not_use_df.loc[train_mask, 'ticket_payout'].reset_index(drop=True)
test_payout = not_use_df.loc[test_mask, 'ticket_payout'].reset_index(drop=True)
train_pred = model.predict(train_X)
test_pred = model.predict(test_X)
def calc_win_money(pred, hit, payout, th=0.5):
bet = (pred > th).astype(int)
hit = hit.to_numpy()
payout = payout.to_numpy()
return_money = np.sum(bet * hit * payout)
bet_money = np.sum(bet)
win_money = return_money - bet_money
return win_money, return_money, bet_money
print(f'train win money :{calc_win_money(train_pred, train_y, train_payout, 0.5)[0]}')
print(f'test win money :{calc_win_money(test_pred, test_y, test_payout, 0.5)[0]}')
train_win_list = []
test_win_list = []
th_list = np.linspace(0.0, 1.0, 1000)
for th in th_list:
train_win_list.append(calc_win_money(train_pred, train_y, train_payout, th)[0])
test_win_list.append(calc_win_money(test_pred, test_y, test_payout, th)[0])
plt.plot(th_list, train_win_list, label='train')
plt.plot(th_list, test_win_list, label='test')
plt.legend()
plt.xlabel('th')
plt.ylabel('win money')
plt.show()学習の流れ
def analysis_columns_effect(df, not_use_columns, not_use_columns_keywards):
train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask = make_learning_data(df, not_use_columns, not_use_columns_keywards)
upsampint_X, upsampling_y = up_sampling(train_X, train_y, ticket_type)
model, (lgb_train_X, lgb_train_y, lgb_valid_X, lgb_valid_y) = learning(upsampint_X, upsampling_y)
print('train')
accuracy_print(model, lgb_train_X, lgb_train_y)
print('valid')
accuracy_print(model, lgb_valid_X, lgb_valid_y)
print('test')
accuracy_print(model, test_X, test_y)
print_model_p(model, train_X, train_y, test_X, test_y)
print_feature_importance(model, train_X)
print_win_money(model, train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask)チケットの影響を調べる関数
def analysis_ticket_effect(ticket_type):
df = pd.read_pickle(f'/work/learning_data/learning_01_{ticket_type}.pkl')
not_use_columns = ['race_id', 'race_date', 'ticket_hit', 'ticket_payout']
not_use_columns_keywards = ['rank', 'time']
analysis_columns_effect(df, not_use_columns, not_use_columns_keywards, ticket_type)チケットの種類別の分析(オッズ情報を使う)
単勝
analysis_ticket_effect('tansyo')正答率
水増ししたデータでは90%の精度でした。
つまり、アタリのデータもかなりよく学習できているということです。
実際のテストデータの精度は0.876なので、前回と変わりありません。
lgbm train
base acc : 0.5018608322995376
acc : 0.9491372504793053
lgbm valid
base acc : 0.4956590370955012
acc : 0.9087082346750855
train
base acc : 0.8248469852845423
acc : 0.8969917958067457
test
base acc : 0.8314552284017933
acc : 0.8767720828789531モデルの出力分布
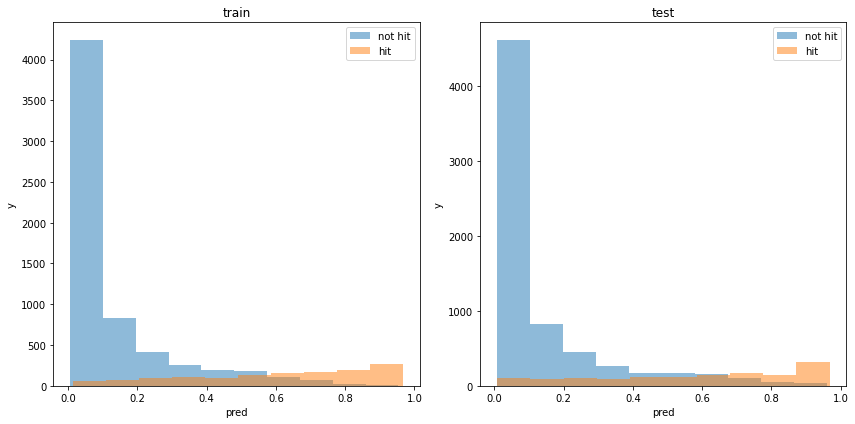
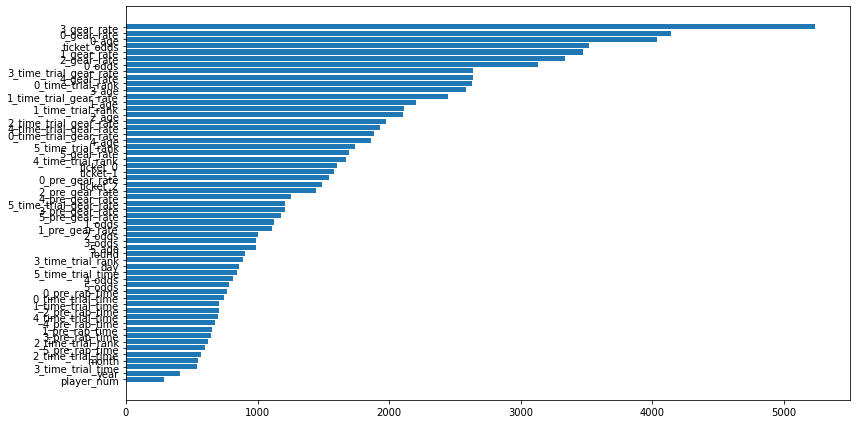
使用した特徴量
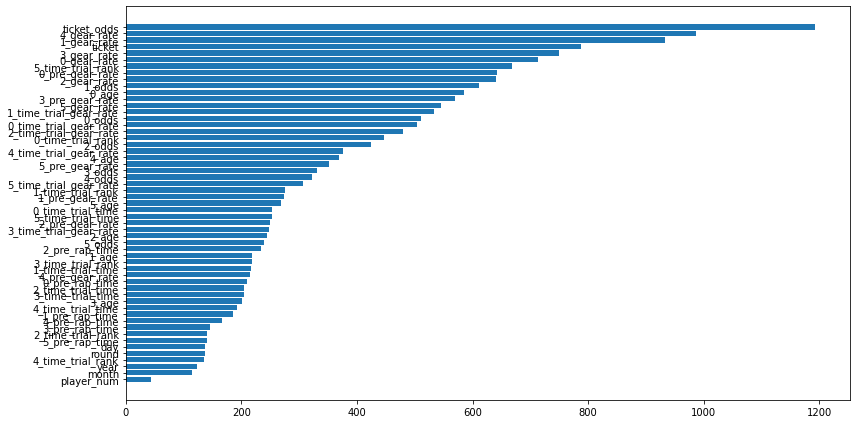
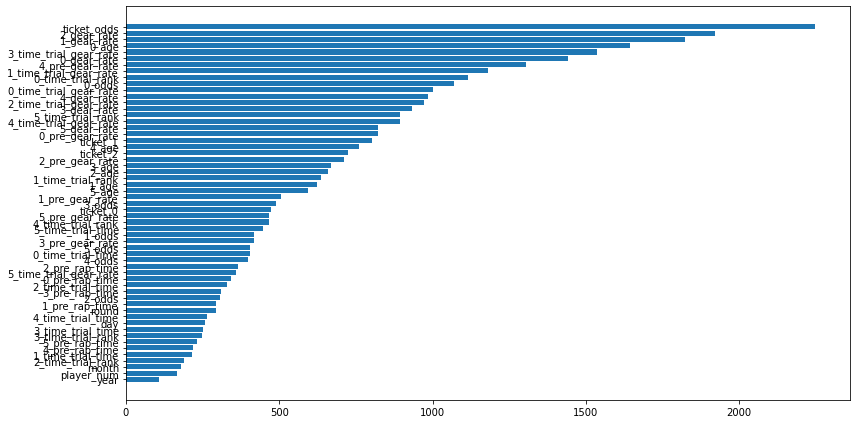
面白いことに、利用する特徴量の上位にx_gear_rateがあります。競輪では、ギア倍率も重要な要因と考えられているので、これが学習器にも反映できたのはいいこです。
利益
利益はマイナスでした
train win money :(-3.800000000000182, 1250.1999999999998, 1254)
test win money :(-245.0999999999999, 1114.9, 1360)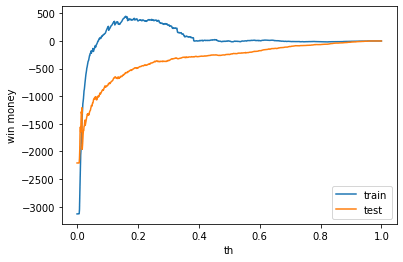
二連複
analysis_ticket_effect('nirenhuku')正答率
水増ししたデータでの95%の精度でした。
lgbm train
base acc : 0.5007598784194529
acc : 0.9707024653833164
lgbm valid
base acc : 0.49822695035460995
acc : 0.956855791962175
train
base acc : 0.9263618943334245
acc : 0.9382972898987134
test
base acc : 0.9317869752844252
acc : 0.9312965868968223モデルの出力分布
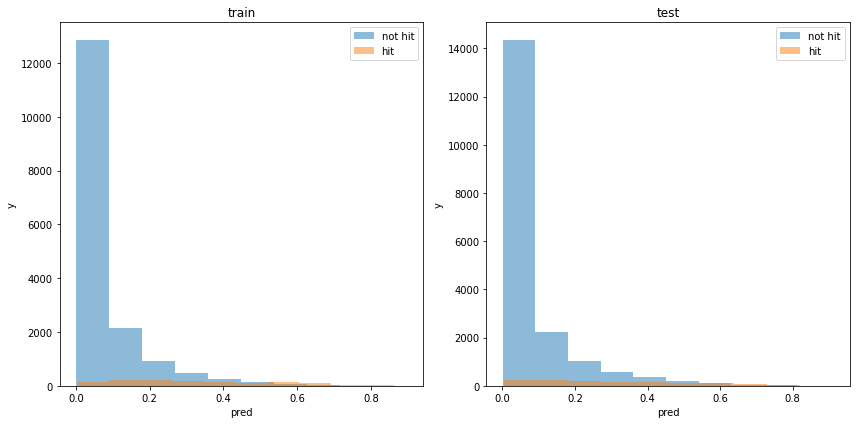
使用した特徴量
利益
train win money :(79.70000000000005, 593.7, 514)
test win money :(-136.29999999999995, 457.70000000000005, 594)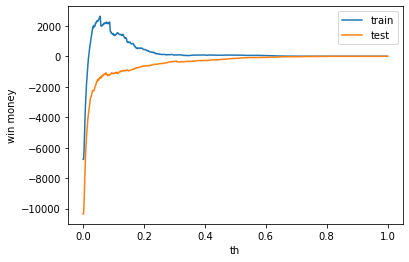
二連単
analysis_ticket_effect('nirentan')正答率
水増ししたデータでの98%の精度でした。
lgbm train
base acc : 0.49889360319941534
acc : 0.9835969061491301
lgbm valid
base acc : 0.5025815925346976
acc : 0.9794893657335039
train
base acc : 0.9631809471667123
acc : 0.9661374212975636
test
base acc : 0.9658934876422126
acc : 0.9630982738328756モデルの出力分布
使用した特徴量
利益
利益はマイナスでした。
train win money :(57.30000000000001, 347.3, 290)
test win money :(-99.89999999999998, 436.1, 536)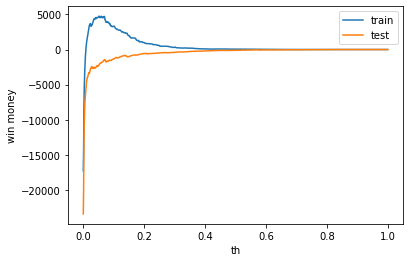
三連複
analysis_ticket_effect('sanrenhuku')正答率
水増ししたデータでの96%の精度でした。
lgbm train
base acc : 0.49968922764892537
acc : 0.9748110831234257
lgbm valid
base acc : 0.5007251354858407
acc : 0.9643538661170903
train
base acc : 0.9419758412424504
acc : 0.9471527178602244
test
base acc : 0.9482668848556977
acc : 0.9440642665873252モデルの出力分布
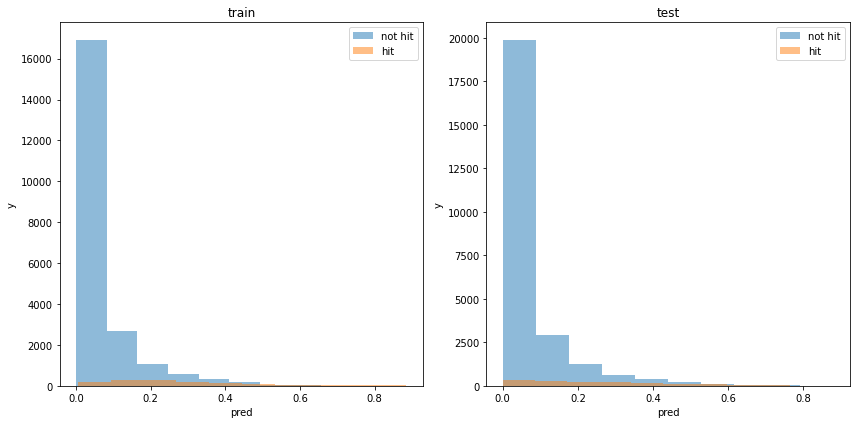
使用した特徴量
利益
利益はマイナスでした。
train win money :(53.900000000000034, 397.90000000000003, 344)
test win money :(-91.20000000000005, 327.79999999999995, 419)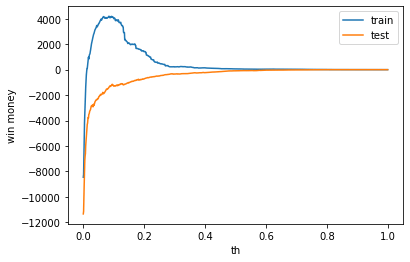
三連単
analysis_ticket_effect('sanrentan')正答率
水増ししたデータでの99%の精度でした。
lgbm train
base acc : 0.5006249060048021
acc : 0.9954415570272106
lgbm valid
base acc : 0.4985418859887949
acc : 0.9945063588291526
train
base acc : 0.9903293068737418
acc : 0.9904443485763589
test
base acc : 0.9913778141426163
acc : 0.9908819299811564モデルの出力分布
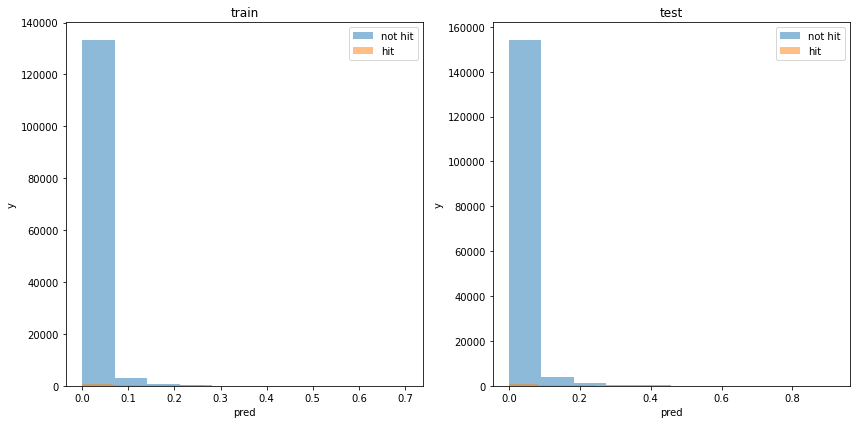
使用した特徴量
利益
利益はマイナスでした。
train win money :(26.299999999999997, 58.3, 32)
test win money :(-43.80000000000001, 74.19999999999999, 118)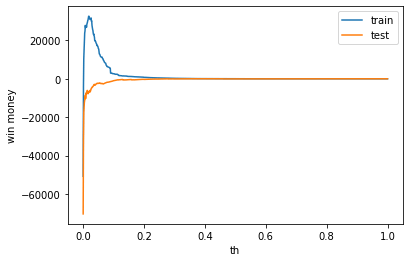
まとめ
水増しすることで、学習が進まなかったチケット(単勝以外)も学習が進むようになりました。
しかし、すべてのチケットで利益はでませんでした。
