
前回のSection 03-03にて、複数回試行のアンサンブルでも利益が出ること確認できました。
しかし、利益の推移は安定していませんでした。
そこで、モデルの閾値を変更して、利益の推移が変化するかを確かめます。
分析するのは
- 二連複
- 二連単
- 三連複
- 三連単
です。
関数
前処理
from sklearn.preprocessing import StandardScaler
def make_learning_data(df, not_use_columns, not_use_columns_keywards, ticket_type):
df['race_date'] = pd.to_datetime(df['race_date'])
if ticket_type == 'wide':
ticket_odds_df = df['ticket_odds'].str.split('\n~', expand=True).rename(columns={0:'ticket_odds_min',1:'ticket_odds_max'})
df['ticket_odds_min'] = ticket_odds_df['ticket_odds_min']
df['ticket_odds_max'] = ticket_odds_df['ticket_odds_max']
if 'ticket_odds' in not_use_columns:
not_use_columns.remove('ticket_odds')
not_use_columns.append('ticket_odds_min')
not_use_columns.append('ticket_odds_max')
#not_use_columns = ['race_id', 'race_date', 'ticket_odds', 'ticket_hit', 'ticket_payout']
#not_use_columns_keywards = ['rank', 'time']
for i in range(6):
for col_keyward in not_use_columns_keywards:
not_use_columns.append(f'{i}_{col_keyward}')
not_use_df = df[not_use_columns]
input_df = df.drop(columns=not_use_columns)
input_df = input_df.apply(pd.to_numeric, args=('coerce',))
for i in range(6):
if f'{i}_odds' in input_df.columns:
zero_mask = input_df[f'{i}_odds'] < 1.0
input_df[f'{i}_odds'] = np.log(input_df[f'{i}_odds'])
input_df.loc[zero_mask, f'{i}_odds'] = np.nan
if 'ticket_odds' in input_df.columns:
not_use_df['ticket_odds'] = input_df['ticket_odds']
zero_mask = input_df['ticket_odds'] < 1.0
input_df['ticket_odds'] = np.log(input_df['ticket_odds'])
input_df.loc[zero_mask, 'ticket_odds'] = np.nan
train_mask = not_use_df['race_date'] < '2023-01-01'
test_mask = not_use_df['race_date'] >= '2023-01-01'
train_input_df = input_df.loc[train_mask, :].reset_index(drop=True)
test_input_df = input_df.loc[test_mask, :].reset_index(drop=True)
categorical_columns = ['round', 'year', 'month', 'day', 'player_num', 'ticket']
if ticket_type != 'tansyo':
categorical_columns.remove('ticket')
for n in range(3):
col = f'ticket_{n}'
if col in input_df.columns:
categorical_columns.append(col)
scaler = StandardScaler()
train_X = pd.DataFrame(data=scaler.fit_transform(train_input_df), columns=train_input_df.columns)
test_X = pd.DataFrame(data=scaler.transform(test_input_df), columns=test_input_df.columns)閾値を変化させて利益の推移を見る関数
利益の推移を確認するための関数を書きました。これで利益の推移が安定的かどうかを確かめました。
import scipy
def print_win_money_line(models, train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask):
train_payout = not_use_df.loc[train_mask, 'ticket_payout'].reset_index(drop=True)
test_payout = not_use_df.loc[test_mask, 'ticket_payout'].reset_index(drop=True)
train_preds = [model.predict(train_X) for model in models]
test_preds = [model.predict(test_X) for model in models]
train_payout = train_payout.fillna(0)
test_payout = test_payout.fillna(0)
def calc_win_money_line(preds, hit, payout, th=0.5):
bets = np.array([(pred > th).astype(int) for pred in preds])
mode_bet, _ = scipy.stats.mode(bets, axis=0)
mode_bet = mode_bet[0]
hit = hit.to_numpy()
payout = payout.to_numpy()
return_money = mode_bet * hit * payout
bet_money = mode_bet
win_money_line = return_money - bet_money
return np.cumsum(win_money_line)
for th in np.linspace(0.2, 0.5, 31):
print('th', th)
train_win_money_line = calc_win_money_line(train_preds, train_y, train_payout, th)
test_win_money_line = calc_win_money_line(test_preds, test_y, test_payout, th)
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(121)
plt.plot(train_win_money_line, label='train')
plt.legend()
plt.xlabel('tickets(day)')
plt.ylabel('win_money')
plt.subplot(122)
plt.plot(test_win_money_line, label='test')
plt.legend()
plt.xlabel('tickets(day)')
plt.ylabel('win_money')
plt.show()モデルをロードして実行
import pickle
def check_models_th_win_line(ticket_type):
df = pd.read_pickle(f'/work/learning_data/learning_01_{ticket_type}.pkl')
not_use_columns = ['race_id', 'race_date', 'ticket_odds', 'ticket_hit', 'ticket_payout']
not_use_columns_keywards = ['rank', 'time', 'odds']
train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask = make_learning_data(df, not_use_columns, not_use_columns_keywards, ticket_type)
with open(f'/work/models/lgbm_{ticket_type}.pkl', 'rb') as f:
models = pickle.load(f)
print_win_money_line(models, train_X, train_y, test_X, test_y, not_use_df, train_mask, test_mask)分析
当たり前ですが利益の推移は、閾値が大きくなるほどベット数は少なくなり、信頼性は低下します。
二連複
閾値を0.3~0.5の間で変化させました。代表的な例をいくつか示します。
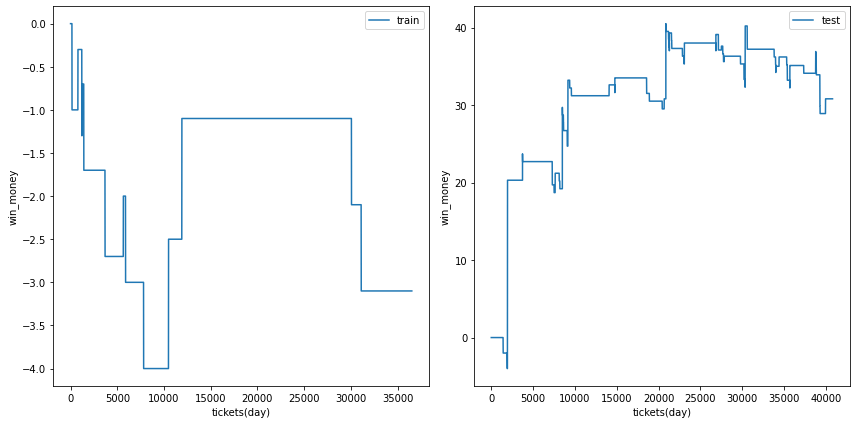
0.5
前回の結果です
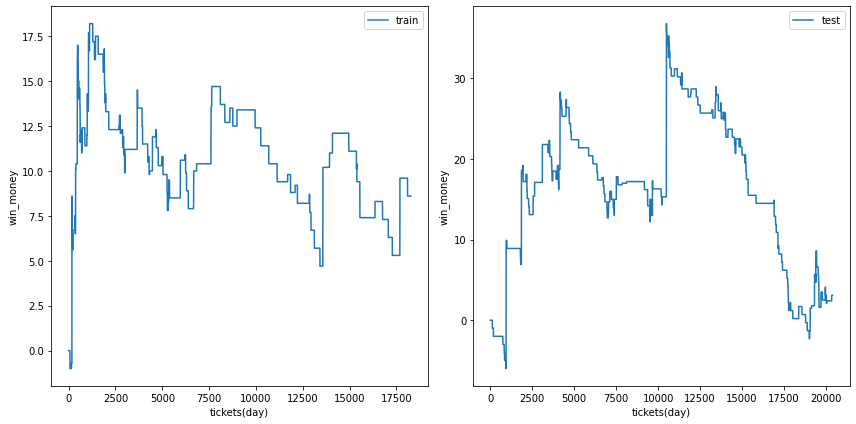
0.45
ベット数は増えましたが、利益は不安定になりました。
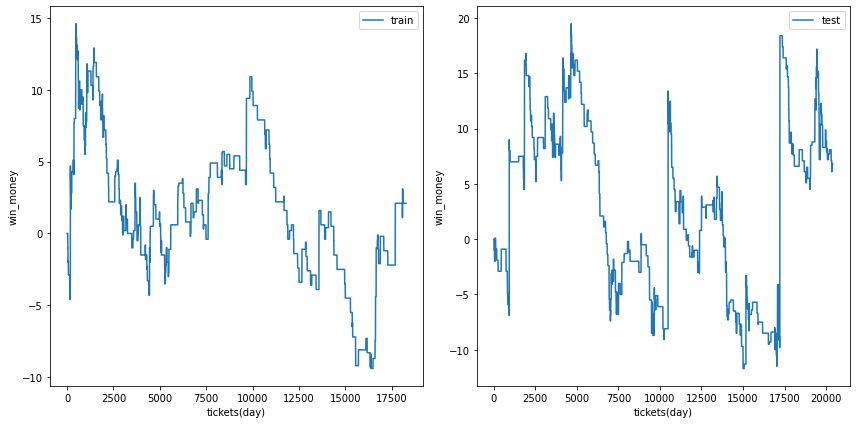
0.4
利益の推移は安定しましたが、マイナス方向へ安定してしまいました。
二連単
閾値を0.3~0.5の間で変化させました。代表的な例をいくつか示します。
0.5
前回の結果です
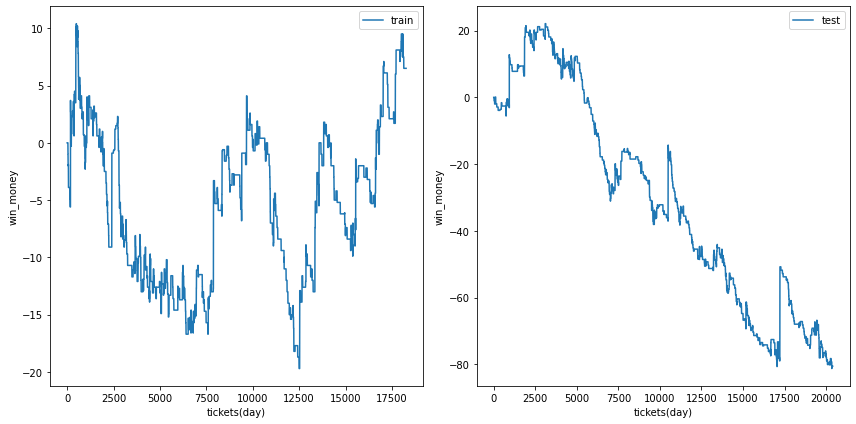
0.45
ベット数は増えましたが、右肩上がりでは無いような傾向があります。
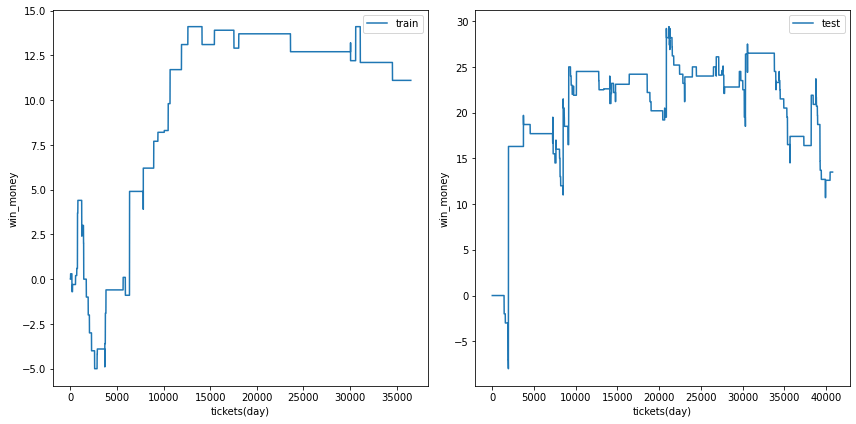
0.4
利益の推移は安定しましたが、マイナス方向へ安定してしまいました。
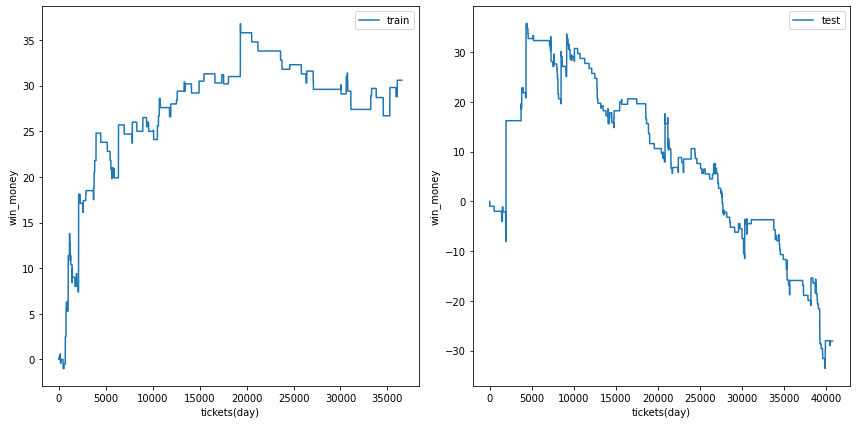
三連複
閾値を0.3~0.5の間で変化させました。代表的な例をいくつか示します。
0.5
前回の結果です
0.45
ベット数は増えましたが、安定的な右肩上がりでは無いようです。
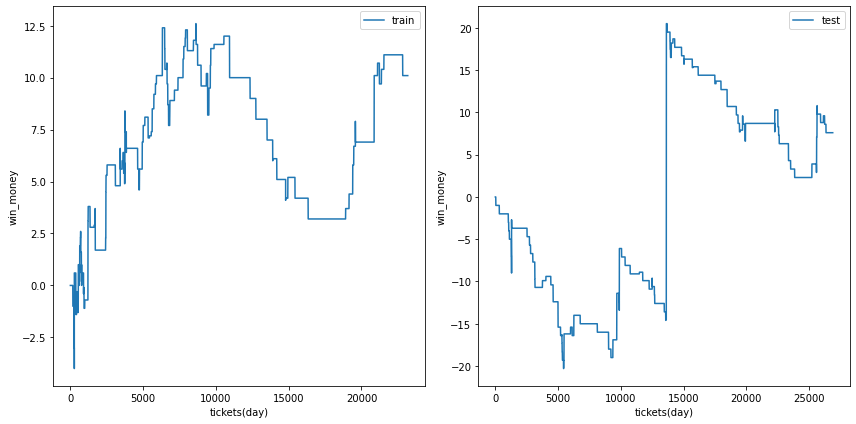
0.4
ベット数は増えましたが、安定的な右肩上がりでは無いようです。
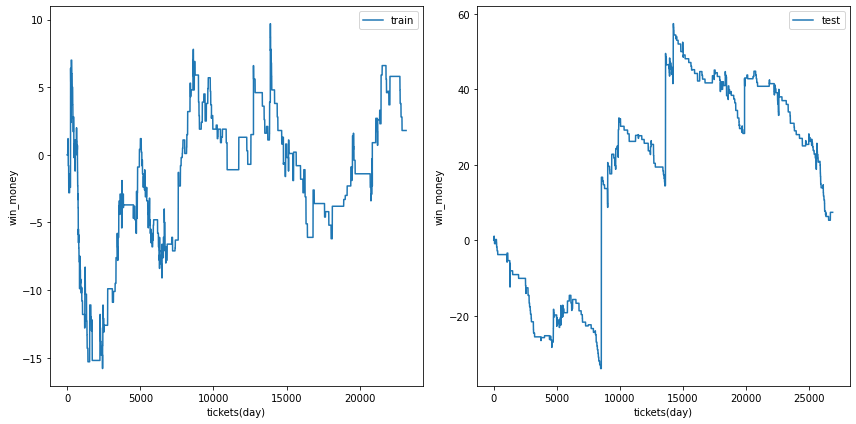
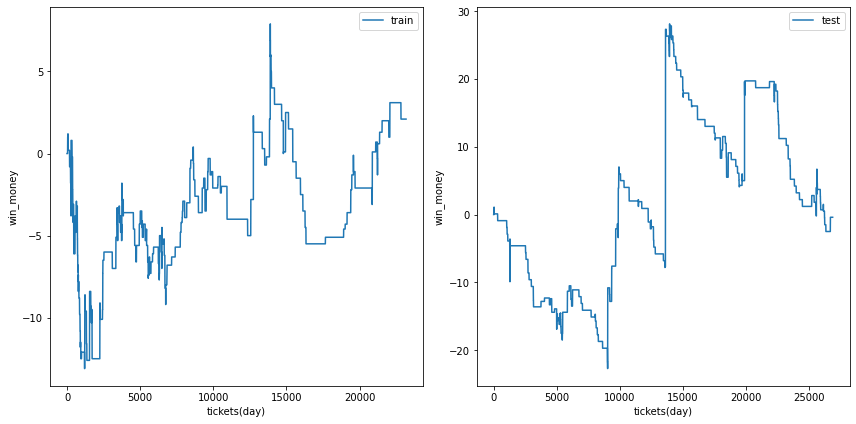
三連単
閾値を0.3~0.5の間で変化させました。代表的な例をいくつか示します。
0.5
前回の結果です
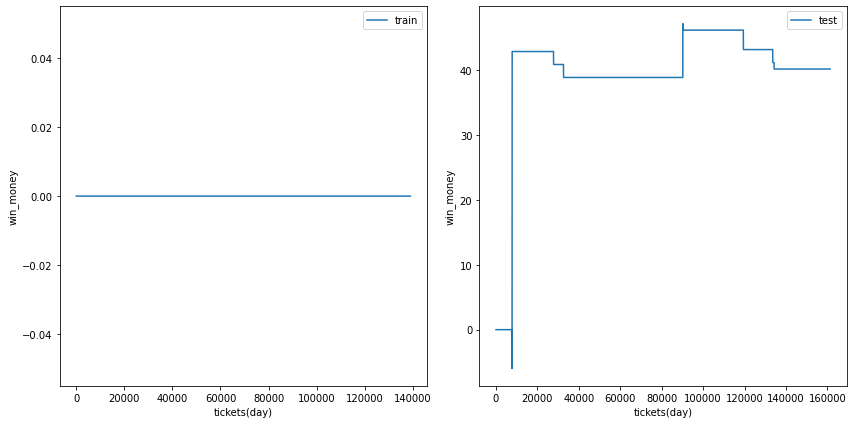
0.45
ベット数は増えましたが、利益は不安定です。
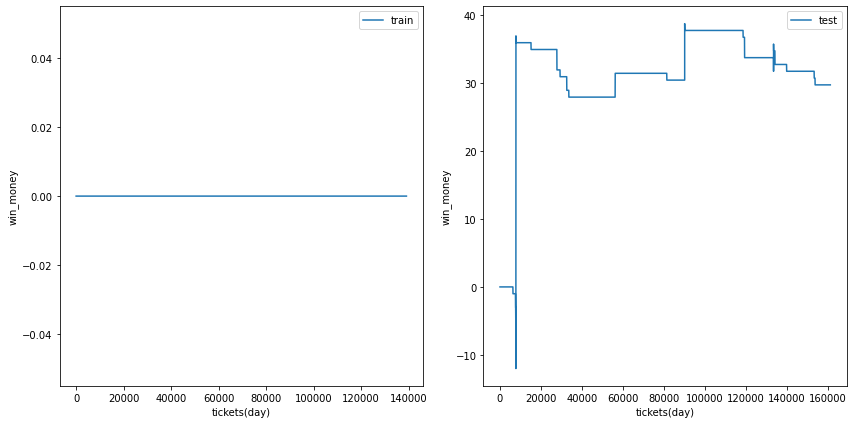
0.4
利益の推移は安定しましたが、ベット数はこれでも少ないです。
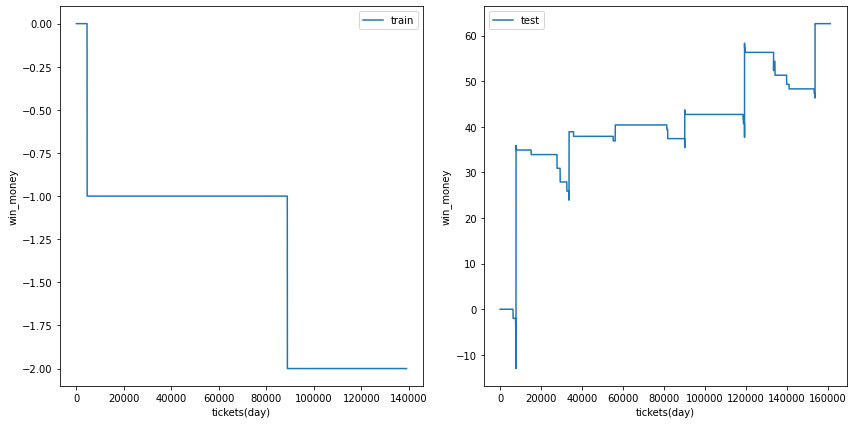
まとめ
閾値を調整しても利益の推移は安定しませんでした。
むしろ、ベット数が多くなるように調整すると利益はマイナスになりました。
三連単ではベット数が増え、調整前よりも安定性は増しましたが、全体としてのベット数が少ないため、利益の確実性は保証できませんでした。
