
簡単に動かせる株価予測
「FinRL: A Deep Reinforcement Learning Library for Automated Stock Trading in Quantitative Finance1」という論文があります.これは発表されたのが2020年と,比較的新しい論文です.
内容をとても簡単に要約すると「株価を強化学習で予測するための環境をライブラリ化しました」という感じです.
このライブラリはGitHub上で公開されています.

さらに,論文上で掲載された結果を再現するためのipynbも公開されています.
もっとも簡単に株価を強化学習で予測してみたいのであれば,このipynbをGoogle Colaboratoryなどで実行するだけで,3-4時間程度で再現ができます.
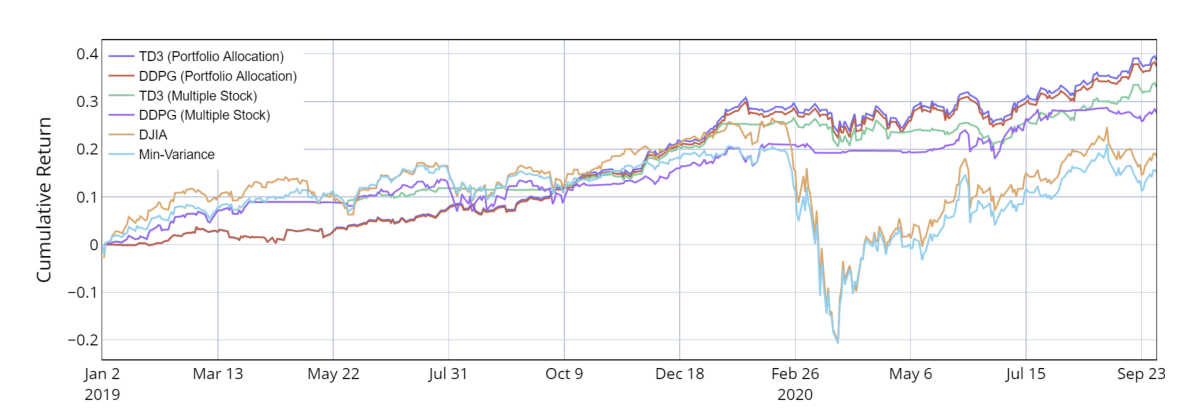
しかし,現在(2023年3月時点で)このipynbを実行しても,上記の画像のような右肩上がりの結果は得られません.
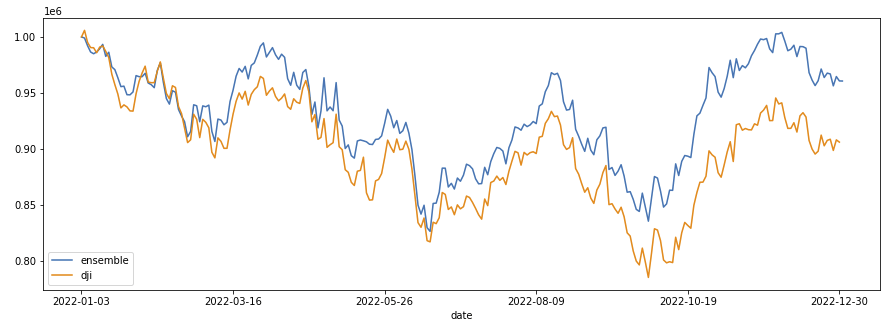
これは,上の論文中と下のipynbの適用期間が違うためです.つまり,2020年時点で論文中で有効だった手法が,2023年時点では有効ではないということです.
この結果の違いには,適用期間の差が生み出した要因(経済活動の変動や戦争など)が絡んでいますが,それとは別にこの強化学習による株価予測には根本的な問題が潜んでいます.
問題提起
強化学習による株価予測には,適用期間によって手法の有効性が変動すること以外にも問題点が2つあります.また,これらの問題点は,私がこれまでに読んだ論文でも未解決のまま扱っていることが多いです.
1 データ数が圧倒的に少ない
多くの論文では1日足を対象に研究していますが,これはあまりにもデータ数が少ないです.
例えば10年間のデータを利用しても10年×365日=3650日となり,たったの3650件のデータしか利用できません.また,過去のデータを利用すればするほど,過去に対する適応力が強まり,直近に対する適応力が弱まります.
一般にニューラルネットワークを利用する学習では少なくとも数万件程度のデータを用意しなければ過学習します.
これは強化学習であっても全く同じです.一般的に強化学習には過学習という概念は存在しません.これは,一般的に強化学習が「環境とのやり取り」を無数に行えるという環境をベースに考えられているからです.
一方で,株価予測を強化学習の環境として捉えたときには,このような「環境との無限のやり取り」は期待できません.なぜなら一人のエージェント(ユーザー)が株を取引したとしても,株価自体が大きく変動するわけではないからです.つまり,株価自体はエージェント一人のアクションに対して影響を受けません.
ニューラルネットワークを利用する強化学習で有名はDQNでは,以下の式を目的としてQネットワークを更新します.
$$
Q_π(s,a)=r+γQ_π(s^′,π(s^′))
$$
この式をすごく単調に表現するのであれば,$γ=0$,$Q_π(s,a)=f(X)$として考えて,
$$
f(X)=r
$$
となり,これを最適化することは,回帰の問題を解いていることとほぼ変わりません.つまり,Xのデータ数が少ないときには通常の機械学習と同様に過学習に陥ります.
2 適用範囲が狭い
もう一つの問題点とは,適用範囲が非常に狭いということです.例えば上記のFinRLでは±k個の売買を最適化できますが,exampleで対象としている銘柄は10個程度です.
しかし,東証に上場している銘柄はJPXのサイトで確認できますが,4000個以上存在します.これらすべてを最適化しようとすると,行動空間が4000×(2k+1)となり,膨大すぎて,最適化できません.
また,それぞれの株価を個別に予測器を作成しようとしても,一つの予測器の生成(学習)に10分もかかれば,10分×4000=27.7日となり,試行錯誤できる現実的な時間ではありません.
解決案
この本では上記で述べた問題に対して,学習中に銘柄を随時変更していくことで対応します.
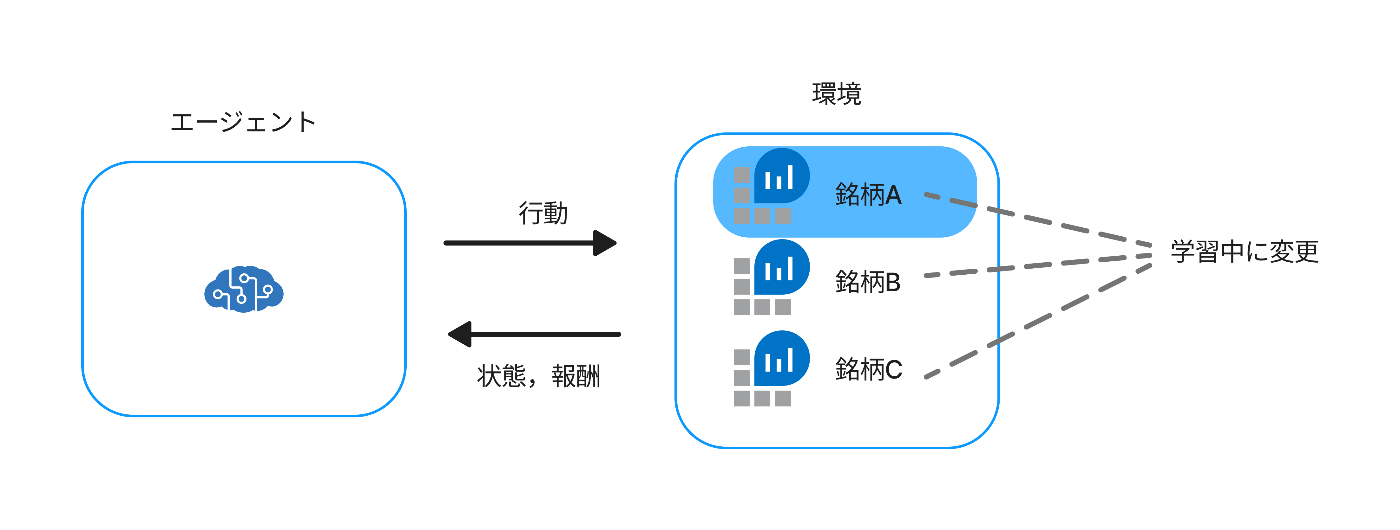
これには次のようなメリットがあります.
- 4000個の銘柄の5年間のデータを扱うとすれば,4000×365×5=7,300,000件であり,学習するデータセットのサイズとしては問題ない量となります.
- 複数の銘柄をスイッチングするように選択して学習するので,実質的に複数の銘柄を学習できます.
- 一つの銘柄に対して±k個の株を購買するときの行動空間は,(2k+1)個となり行動空間が膨大になるのを防げます.
一方で次のようなデメリット・懸念点が存在します.
- スイッチングして株価を学習することにより,学習が不安定になり,うまく学習できない可能性がある.
- 別の銘柄を学習すると,他の銘柄の学習を忘れてしまう可能性がある(catastrophic forgetting).
よって,この本の目的は「上記の懸念点が挙げられる中,本当に株価予測が可能なのか」を検証することとなります.
- LIU, Xiao-Yang, et al. FinRL: A deep reinforcement learning library for automated stock trading in quantitative finance. arXiv preprint arXiv:2011.09607, 2020. ↩︎
