
このプログラムの目的
NSGA2とNeuroEvolutionによる株取引を最適化することです.
NSGA2は多目的最適化の手法です.このプログラムでは次の2つの目的関数を設定します,
- 総資産が単調増加するときの傾き(大きいほどよい)
- 総資産の単調増加するときのブレ(小さいほど良い)
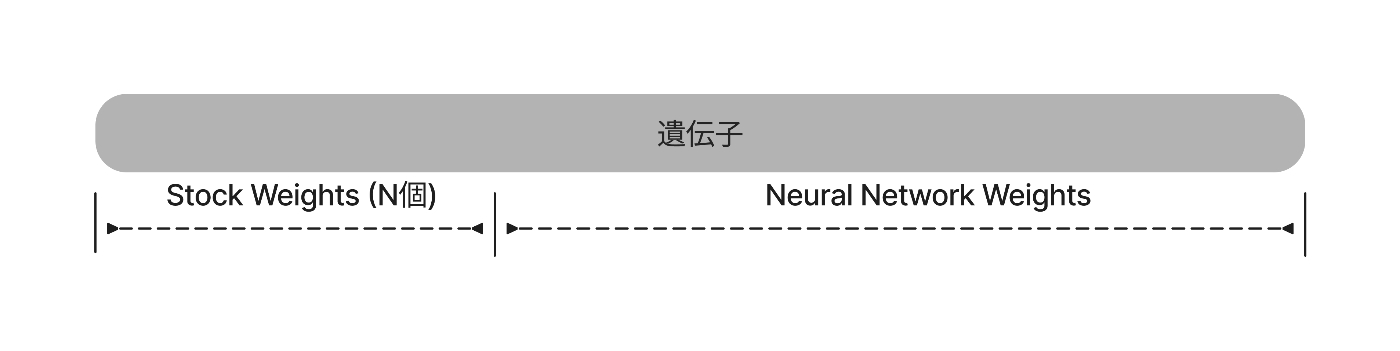
また,N個ある銘柄の中からK個の銘柄を利用します.このとき,利用する銘柄も最適化します.
遺伝子型は以下の様な実数値1次元配列です.
先頭のN個の遺伝子座からTop Kの銘柄の特徴量をニューラルネットワークに入力します.
work_share
├07_evolutionary_algorithms
├Dockerfile
├docker-compose.yml
└src
└neuro_evolution_torch
├nsga2_neuroevo.py (これを作成)
├torch_model.py
├simulation_cython.pyx
└setup.py使用ライブラリ
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import random
import time
import pickle
from copy import deepcopy
import warnings
import os
import gc
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LinearRegression
from deap import base
from deap import creator
from deap import tools
import torch
import neuro_evolution_torch.simulation_cython as sim_cy
import neuro_evolution_torch.torch_model as torch_model個体生成・交叉・コピー
- pytorchのTensortを継承した遺伝子を個体として定義する予定です.
- 個体生成関数の返り値がtorch.Tensorに渡される.
- 交叉は実装が容易だったため,Blend-Alpha法を実装.
- 個体のコピー関数は自分で実装する必要がある(単純にdeppcopyを呼ぶと,torch.Tensorのコピーがうまくいかなかった).
def uniform(low, up, size=None):
return np.random.uniform(low, up, size)
def blend_alpha(ind1, ind2, alpha):
_min = torch.minimum(ind1, ind2)
_max = torch.maximum(ind1, ind2)
r = (_max - _min)*alpha
_min = _min - r
_max = _max + r
size = ind1.shape[0]
ind1[:] = (_max - _min)* torch.rand(size) + _min
ind2[:] = (_max - _min)* torch.rand(size) + _min
return ind1, ind2
def individual_copy(individual_class, ind):
new_ind = individual_class()
new_ind[:] = ind.clone()
new_ind.fitness = deepcopy(ind.fitness)
return new_ind個体の実行
- 個体と入力値等を渡して,シミュレーション結果を得る.
- 個体が選択した銘柄も返す.
adjust_money_rateを呼んで,現金の保有率の最低値を10%にしている.
この関数は評価以外にも,途中結果の出力にも使われる.
def run_ind(X, init_money, values, nn_model, num_select, input_time_length, device, ind):
columns = values.columns
select_w = ind[:len(columns)]
w = ind[len(columns):]
top_k_indexes = torch.topk(select_w, num_select).indices
select_codes = columns[top_k_indexes.numpy()]
X_columns = [f't{t}_{col}' for col in select_codes for t in range(1, input_time_length+1)]
X = X[X_columns]
X = X.values.astype(np.float32)
X = torch.from_numpy(X)
values = values[select_codes].values.astype(np.float64)
P = torch_model.model_calculate(nn_model, w, X, device)
P = sim_cy.adjust_money_rate(P, 0.1)
logging = sim_cy.trade_simulate(init_money, P, values)
return logging, select_codes個体の評価
この関数のステップは以下の通りです.
- 個体を評価する.引数は個体の評価と同じ.
- 個体を実行して,総資産の推移を算出する.
- 総資産の推移を線形回帰して,その傾きと回帰モデルとの誤差を計測する.
- 傾きと誤差を返して,多目的最適化にする.
def evaluate(X, init_money, values, nn_model, num_select, input_time_length, device, ind):
logging, _ = run_ind(X, init_money, values, nn_model, num_select, input_time_length, device, ind)
total_assets = logging.logging_total_assets
y = (total_assets - init_money)/init_money
x = np.linspace(0, 1.0, len(y))[:, np.newaxis]
model = LinearRegression().fit(x, y)
coef = model.coef_[0]
pred_y = model.predict(x)
rmse = np.sqrt(np.mean((y - pred_y)**2))
del logging
return coef, rmseNSGA2による最適化
GAのパラメータを与えます.また,学習期間やテスト期間の設定を行います.
class NSGA2_Learner:
def __init__(self, max_generation=200, seed=0, pop_size=100,
init_money=10000000, device='cuda', num_select=10,
train_start_date='2021-01-01', train_end_date='2022-01-01',
re_production_type='crossover'):
self.max_generation = max_generation
self.seed = seed
self.pop_size = pop_size
self.init_money = init_money
self.dataset = None
self.input_num = None
self.output_num = None
self.unit_num = None
self.model = None
self.device = device
self.num_select = num_select
self.re_production_type = re_production_type
self.train_start_date = f'{train_start_date} 00:00+09:00'
self.train_end_date = f'{train_end_date} 00:00+09:00'
self.pop = None
print(f'training term : start :{self.train_start_date}, end :{self.train_end_date}')NSGA2_Learnerのメンバ関数 : データセットの登録
データセットのパスを与えて読み込みます.
生成するニューラルネットワークの各層のユニット数を決定する.
隠れ層のユニット数(self.unit_num)はここではself.outputの2倍とした.
def set_dataset(self, dataset_dir):
print('load dataset')
df = pd.read_pickle(f'{dataset_dir}/original_value.dfpkl')
df = df.fillna(method='ffill').fillna(0)
self.dataset = {
'is_train_data':df['is_train_data'],
'date':df['date'],
'values':df.drop(['is_train_data', 'date'], axis=1)
}
self.input_time_length = 30
df = pd.DataFrame()
for t in range(1, self.input_time_length+1):
t_df = pd.read_pickle(f'{dataset_dir}/pred_codes_-t{t}.dfpkl')
t_df = t_df.drop(['is_train_data', 'date'], axis=1)
t_df = t_df.fillna(method='ffill').fillna(0)
rename_columns = {col:f't{t}_{col}' for col in t_df.columns}
t_df = t_df.rename(columns=rename_columns)
df = pd.concat([df, t_df], axis=1)
self.dataset['X'] = df
self.input_num = self.num_select*self.input_time_length
self.output_num = self.num_select + 1# +1 is money out
self.unit_num = self.output_num*2
self.original_x_dim = self.dataset['X'].shape[1]
self.stock_code_list = [code for code in self.dataset['values'].columns]NSGA2_Learnerのメンバ関数 : 使用するデータセットの選択
データセットのタイプを選びます.学習モード(is_train_data)がTrueならば学習データセットのみを返します.
def get_eval_dataset(self, is_train_data=True):
if is_train_data==False:
return self.dataset
mask = self.dataset['is_train_data'] & (self.train_start_date < self.dataset['date']) & (self.dataset['date'] < self.train_end_date)
dataset = {
'date':self.dataset['date'][mask].reset_index(drop=True),
'values':self.dataset['values'][mask].reset_index(drop=True),
'X':self.dataset['X'][mask].reset_index(drop=True),
}
return datasetNSGA2_Learnerのメンバ関数 : 最適化の開始
最適化を開始します.deapのnsga2のexampleを参考にしています.
ただし,exampleのコードではpythonのlistで個体を表現していますが,非常に処理が遅いので,pytorchのTensorで表現することにしました.
args['save_interval']世代間隔で母集団の情報を保存します.
def learning(self, args):
self.set_dataset(args['dataset_dir'])
self.model = torch_model.Neural_Network_3layer(self.input_num, self.output_num, self.unit_num)
print(f'input_num {self.input_num}, output_num {self.output_num}')
select_code_NDIM = self.dataset['values'].shape[1]
nn_NDIM = torch_model.model_w_to_vec(self.model).shape[0]
NDIM = select_code_NDIM + nn_NDIM
print(f'NDIM {NDIM}:: select code {select_code_NDIM} + nn {nn_NDIM}')
BOUND_LOW, BOUND_UP = -5, 5
warnings.simplefilter('ignore', category=RuntimeWarning)
random.seed(self.seed)
np.random.seed(self.seed)
torch.manual_seed(self.seed)
creator.create("FitnessMin", base.Fitness, weights=(1.0, -1.0))
creator.create("Individual", torch.Tensor, fitness=creator.FitnessMin)
toolbox = base.Toolbox()
toolbox.register("attr_float", uniform, BOUND_LOW, BOUND_UP, NDIM)
toolbox.register("individual", tools.initIterate, creator.Individual, toolbox.attr_float)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
toolbox.register("clone", individual_copy, toolbox.individual)
learning_dataset = self.get_eval_dataset(is_train_data=True)
X = learning_dataset['X']
values = learning_dataset['values']
toolbox.register("evaluate", evaluate, X, self.init_money, values,
self.model, self.num_select, self.input_time_length, self.device)
toolbox.register("mate", blend_alpha, alpha=0.5)
toolbox.register("select", tools.selNSGA2)
stats = tools.Statistics(lambda ind: ind.fitness.values)
stats.register("min", np.min, axis=0)
stats.register("max", np.max, axis=0)
logbook = tools.Logbook()
logbook.header = "gen", "evals", "std", "min", "avg", "max"
pop = toolbox.population(n=self.pop_size)
invalid_count = sum([1 for ind in pop if not ind.fitness.valid])
for ind in pop:
if not ind.fitness.valid:
ind.fitness.values = toolbox.evaluate(ind)
pop = toolbox.select(pop, len(pop))
record = stats.compile(pop)
logbook.record(gen=0, evals=invalid_count, **record)
print(logbook.stream)
for gen in range(self.max_generation+1):
offspring = tools.selTournamentDCD(pop, len(pop))
offspring = [toolbox.clone(ind) for ind in offspring]
if self.re_production_type == 'crossover':
for ind1, ind2 in zip(offspring[::2], offspring[1::2]):
if random.random() <= 0.95:
toolbox.mate(ind1, ind2)
del ind1.fitness.values, ind2.fitness.values
invalid_count = sum([1 for ind in offspring if not ind.fitness.valid])
for ind in offspring:
if not ind.fitness.valid:
ind.fitness.values = toolbox.evaluate(ind)
pop = toolbox.select(pop + offspring, self.pop_size)
record = stats.compile(pop)
logbook.record(gen=gen, evals=invalid_count, **record)
print(logbook.stream)
if gen % args['save_interval'] == 0:
save_pop_info(pop, args, gen, self)
gc.collect()
with open(f'{args["result_dir"]}/logbook.pkl', 'wb') as f:
pickle.dump(logbook, f)
return self母集団の情報を可視化して保存
母集団の情報を保存する関数です.
パレートフロントおよび,その個体の総資産推移情報を可視化して保存します.
def save_pop_info(pop, args, gen, learner):
save_dir = f'{args["result_dir"]}/generation_info/{gen}'
os.makedirs(save_dir, exist_ok=True)
ind_info_save_dir = f'{save_dir}/ind_info'
os.makedirs(ind_info_save_dir, exist_ok=True)
eval_dataset = learner.get_eval_dataset(is_train_data=False)
X = eval_dataset['X']
values = eval_dataset['values']
scaler = StandardScaler()
scaled_values = pd.DataFrame(data=scaler.fit_transform(values), columns=values.columns)
date = eval_dataset['date'].values
front_pop = tools.sortNondominated(pop, len(pop), first_front_only=True)[0]
front_pop_dict = {ind.fitness.values:ind for ind in front_pop}
front_pop = list(front_pop_dict.values())
front_pop.sort(key=lambda ind:ind.fitness.values[0], reverse=True)
save_path = f'{save_dir}/pareto_front.jpg'
save_pareto_front_curve(save_path, front_pop)
for i, ind in enumerate(front_pop):
logging, select_codes = run_ind(X, learner.init_money, values, learner.model, learner.num_select,
learner.input_time_length, learner.device, ind)
save_path = f'{ind_info_save_dir}/ind_{i}.jpg'
save_ind_info(logging,
date,
scaled_values,
learner.train_start_date,
learner.train_end_date,
select_codes,
save_path)パレートフロントの描画
パレートフロントの保存します.
def save_pareto_front_curve(save_path, pop):
front = np.array([ind.fitness.values for ind in pop])
plt.cla()
plt.clf()
plt.scatter(front[:,0], front[:,1], c="b")
plt.xlabel('coef')
plt.ylabel('rmse')
plt.savefig(save_path, bbox_inches='tight')個体の総資産推移の詳細を描画
個体の総資産推移の詳細を保存します.
- ax1 : 銘柄・現金の保有割合の時間推移
- ax2 : 銘柄の株価の時間推移(正規化したもの)
- ax3 : 総資産の時間推移と現金の時間推移
def save_ind_info(logging, x, scaled_values, train_start_date, train_end_date, select_codes, save_path):
plt.cla()
plt.clf()
P = logging.logging_p
Y = [P[:, i] for i in range(P.shape[1])]
labels = [f'{select_codes[i]}' for i in range(P.shape[1]-1)] + ['money']
fig = plt.figure(figsize=(12, 12))
ax1 = fig.add_subplot(3, 1, 1)
ax1.stackplot(x, Y, labels=labels)
ax1.legend(loc='upper left', bbox_to_anchor=(1., .5))
ax1.set_xlabel('date')
ax1.set_ylabel('hold rate')
ax2 = fig.add_subplot(3, 1, 2)
for code in select_codes:
ax2.plot(x, scaled_values[code], label=f'{code}')
#ax2.legend(loc='upper left', bbox_to_anchor=(1., .5))
ax2.set_xlabel('date')
ax2.set_ylabel('scaled value')
y1 = logging.logging_total_assets
y2 = logging.logging_money
ax3 = fig.add_subplot(3, 1, 3)
ax3.plot(x, y1, label='total assets')
ax3.plot(x, y2, label='money')
ax3.axvspan(train_start_date, train_end_date, color="gray", alpha=0.3, label='training')
ax3.legend()
ax3.set_xlabel('date')
ax3.set_ylabel('total_assets')
plt.savefig(save_path, bbox_inches='tight')