
以前、googleのgeminiで返答をjsonフォーマットに指定する話をしました。

このときは「Googleは大量のjsonフォーマットを学習させたんだなー」と思っていました。
しかし、llama.cppの文献を漁っていたら、なんとllama.cppでもjsonフォーマットの指定ができることを発見しました。
今回の記事では、llamafile(llama.cppもしくはollamaも同様)にてjsonフォーマットを指定する方法を話したいと思います。
仕組み
仕組みについて話します。
私の以前までの知識では、プロンプトにjsonフォーマットを組み込むことで、出力文にjsonテキストを吐き出させるのが一般的だと思っていました。
What are the 5 planets closest to the sun? Reply with only a valid JSON array of objects formatted like this:
```json
[{
"planet": string,
"distanceFromEarth": number,
"diameter": number,
"moons": number
}]```この様に、質問文にjsonフォーマットいれると、LLMの回答がjsonになることが多いです。
しかし、Geminiでjson返答を受け取る記事でも話しましたが、これは絶対的な制約ではありません。
事実、LLMや乱数によってはjsonフォーマットを守ってくれなかったり、不要な単語(はい、わかりました、など)が付随してきます。
だからこそ、geminiのjson返答はすばらしいなーと思っていたのですが、どうやら学習文章にjson指定を大量に入れているわけでは無いようです。
どうやら、出力されるトークンの確率に対して、指定した構文(Grammar)に合わないものは0にする処理を施しているようです。そして、その構文(Grammar)をjsonフォーマットに適合させることで、かならずjsonが返ってくる仕組みでした。
そして、この構文(Grammar)の指定は、llama.cppでもできるのです。
Grammarの指定
grammarの指定に関しては、リファレンスを読めばいいと思います。私は次のissuesが参考になりました。

どうやら、実行オプションに--grammar-fileを指定すればいいようです。
そして、指定するgrammar-fileは、llama.cppに付属しているjson-schema-to-grammar.pyによってjsonフォーマットから変換できるみたいです。
さらに、Grammar Builderというサービスを使えば、json-schema-to-grammar.pyを使わなくても、grammar-fileが作れます。

今回はGrammar Builderを使って、grammar-fileを生成して、llamafileに指定してみます。
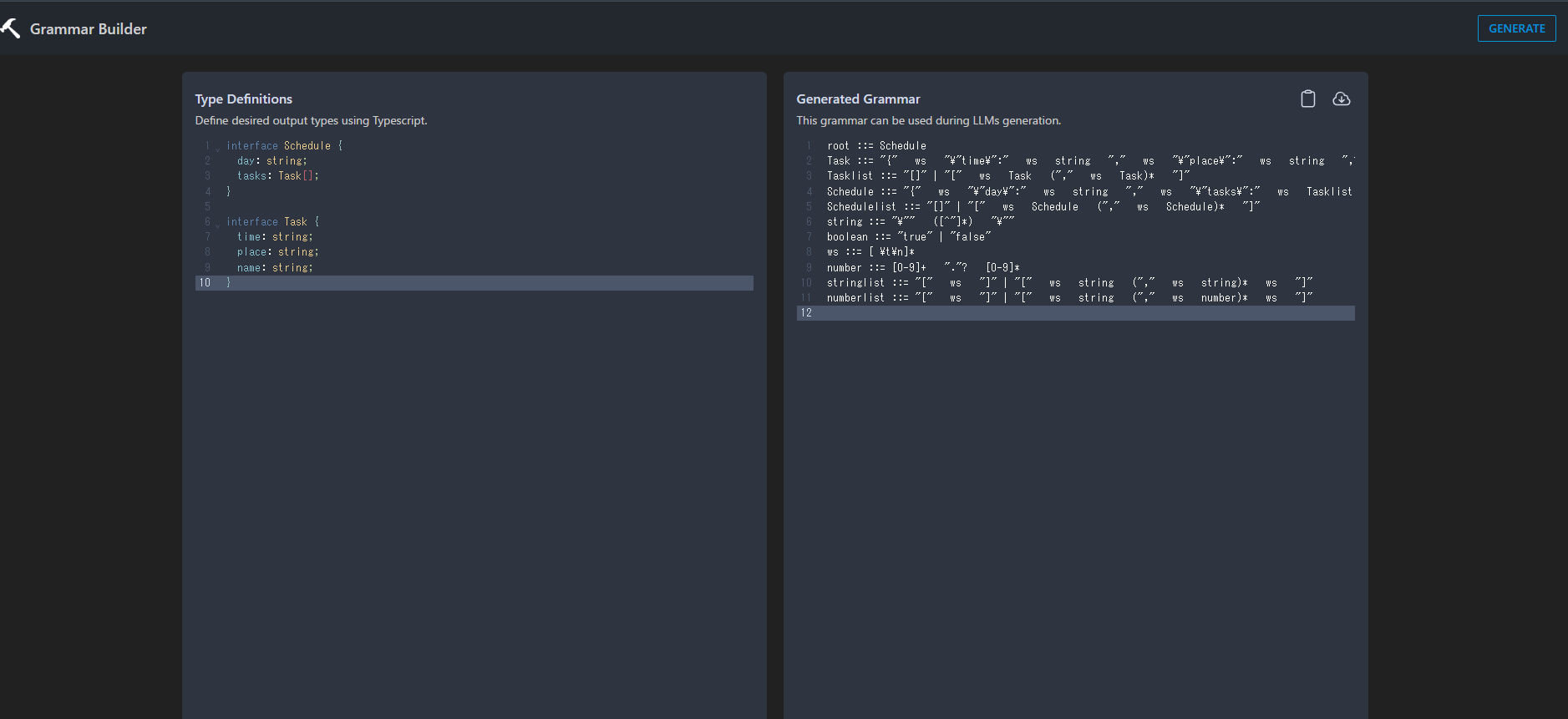
まず、Grammar Builderを開きます。左側にjsonフォーマットを書き、右上の「GENERATE」を押すと、左側にgrammer-fileが出力されます。その後、出力されたgrammar-fileをダウンロードして、llamafileと同じディレクトリに置きましょう。
試しに、次のType Definitionsを書きました。[ ]はリストを表しています。
interface Schedule {
day: string;
tasks: Task[];
}
interface Task {
time: string;
place: string;
name: string;
}GENERATEを押して、右側にGrammarが表示されたら、ダウンロードアイコンを押してダウンロードします。
ダウンロードされたファイル(grammar.gbnf)はllamafileと同じディレクトリに置きます。
実行
では実行してみます。
今回のllamafileはphi-3-miniを使いました。以下のリンクからダウンロードできます。

ターミナルで実行しても良いのですが、今回はpythonのsubprocessを使ってコマンド実行します。これはpromptが長くなると、ターミナルが見づらくなるためです。
import subprocess
question = 'What is the schedule today?'
llm_prompt = f'''<|system|>
You are a helpful AI assistant.<|end|>
<|user|>
{question}<|end|>
<|assistant|>
'''
command = [
'./Phi-3-mini-4k-instruct.Q4_K_M.llamafile.exe',
'-ngl', '9999',
'-e', '-p', f'"{llm_prompt}"',
'-n', '512',
'--grammar-file', 'grammar.gbnf',
'--no_display_prompt'
]
print(' '.join(command))
result = subprocess.run(command, capture_output=True, text=True, encoding='utf8')
print(result.stdout)
import json
import pprint
ret_text = result.stdout
start_index = ret_text.find('{')
end_index = ret_text.rfind('}')
ret_text = ret_text[start_index:end_index+1]
print(ret_text)
pprint.pprint(json.loads(ret_text))ターミナルで実行するなら、次のコマンドになります。
./Phi-3-mini-4k-instruct.Q4_K_M.llamafile.exe -ngl 9999 -e -p "<|system|>\nYou are a helpful AI assistant.<|end|>\n<|user|>\nWhat is the schedule today?<|end|>\n<|assistant|>" -n 512 --grammar-file grammar.gbnf --no_display_promptpythonのプログラムを実行すると、次のような結果が得られました。
{'day': 'Wednesday',
'tasks': [{'name': 'Team Meeting',
'place': 'Conference Room A',
'time': '09:00 AM'},
{'name': 'Project Presentation Preparation',
'place': 'Office 203',
'time': '11:00 AM'},
{'name': 'Coffee Break',
'place': 'Coffee Breakroom',
'time': '02:00 PM'},
{'name': 'Client Call', 'place': 'Office 101', 'time': '04:00 PM'}]}ちゃんと、jsonになって返ってきています!
日本語でのjson返答
次は、日本語の返答もjsonでやってくれるか確かめます。
import subprocess
question = '今日の予定はなんですか?'
llm_prompt = f'''<|system|>
あなたは優秀なAIアシスタントです<|end|>
<|user|>
{question}<|end|>
<|assistant|>
'''
command = [
'./Phi-3-mini-4k-instruct.Q4_K_M.llamafile.exe',
'-ngl', '9999',
'-e', '-p', f'"{llm_prompt}"',
'-n', '512',
'--grammar-file', 'grammar.gbnf',
'--no_display_prompt'
]
print(' '.join(command))
result = subprocess.run(command, capture_output=True, text=True, encoding='utf8')
print(result.stdout)
import json
import pprint
ret_text = result.stdout
start_index = ret_text.find('{')
end_index = ret_text.rfind('}')
ret_text = ret_text[start_index:end_index+1]
print(ret_text)
pprint.pprint(json.loads(ret_text))実行すると次の結果が得られました。
{'day': 'Today',
'tasks': [{'name': 'コーヒーを飲む', 'place': 'Tokyo', 'time': '09:00'},
{'name': 'ビジネスミーティング', 'place': 'Shinjuku', 'time': '12:00'},
{'name': '映画観覧', 'place': 'Ueno', 'time': '18:30'}]}んー場所が、ローマ字になってしまいました。これはphi-3-miniの性能もあると思います。
せっかくなので、さらに強制力を強めてみます。
場所を日本語にして、4つの場所のみにしてみます。
interface Schedule {
day: string;
tasks: Task[];
}
interface Task {
time: string;
place: Place;
name: string;
}
enum Place {
home = "家",
station = "駅",
office = "会社",
eat_space = "レストラン",
}これをGrammar Builderでgrammar-fileにして、もう一度実行してみます。
{'day': '今日',
'tasks': [{'name': 'ビジネスミーティング', 'place': '会社', 'time': '09:00'},
{'name': '昼食', 'place': 'レストラン', 'time': '13:00'},
{'name': 'プレゼントの受け取り', 'place': '家', 'time': '18:00'}]}指定したとおりにの場所が出力されました!。
時間やタスク名なども、Grammarをいじれば調整できそうですね。
また、日本語のgrammar-fileもllama.cppにはあるので、これも組み込めば、より日本語を強制できると思います。
まとめ
今回はllamafile(llama.cpp もしくはollama)にて、jsonフォーマットを強制する話をしました。
無事、jsonフォーマットを強制することができて、よかったです。
また、どうしてもgrammar-fileを参照しながらLLMが実行されるためか、処理速度は低下してしまいます。しかし、指定したjsonで返答されるメリットは計り知れないので、今後とも活用していきたいと思います。

