
3位以内になるかどうかを学習してみて、利益を算出してみます。
多くの競馬記事がこれと似たようなことをやっている気がします。
学習過程はipynbファイルで行いました。以下はその記録です。
前処理
まず、使いそうなライブラリをインポートします。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from IPython.display import display, Math学習データの読み込み
df = pd.read_pickle('/work/formatted_source_data/analysis_data02.pkl')
df正しく読み込めていれば、テーブルデータが表示されます。
次に、このテーブルデータの列名を見てみます。
print(list(df.columns))めちゃめちゃ表示されますが、後半は追加したデータなので、必ず学習に使うので見なくても大丈夫です。前半のデータを学習に入れるかをチェックします。
['race_date', 'race_id', 'place_id', 'race_grade', 'race_distance', 'race_type', 'race_total_prize', 'weather', 'race_condition', 'horse_count', 'waku', 'horse_number', 'name', 'sex', 'age', 'jocky_weight', 'jocky_name', 'odds', 'popular', 'weight', 'weight_sub', 'rank', 'time', 'prize', 'tansyo_hit', 'tansyo_payout', 'hukusyo_hit', 'hukusyo_payout', 'pre_race_count', 'pre_race_rankin1_rate', 'pre_race_rankin3_rate', 'pre_race_mean_rank', 'pre_race_weight_mean_rank', 'pre_race_mean_strength', 'pre_race_weight_mean_strength', 'pre_race_total_prize', 'pre_race_mean_prize', 'pre_race_weight_mean_prize', 'pre_race_jocky_count', 'pre_race_jocky_rankin1_rate', 'pre_race_jocky_rankin3_rate', 'pre_race_jocky_mean_rank', 'pre_race_jocky_weight_mean_rank', 'pre_race_jocky_mean_strength', 'pre_race_jocky_weight_mean_strength', 'pre_race_jocky_total_prize', 'pre_race_jocky_mean_prize', 'pre_race_jocky_weight_mean_prize', 'ped_0', 'ped_1', 'ped_2', 'ped_3', 'ped_4', 'ped_5', 'ped_6', 'ped_7', 'ped_8', 'ped_9', 'ped_10', 'ped_11', 'ped_12', 'ped_13', 'ped_14', 'ped_15', 'ped_16', 'ped_17', 'ped_18', 'ped_19', 'ped_20', 'ped_21', 'ped_22', 'ped_23', 'ped_24', 'ped_25', 'ped_26', 'ped_27', 'ped_28', 'ped_29', 'ped_30', 'ped_31', 'ped_32', 'ped_33', 'ped_34', 'ped_35', 'ped_36', 'ped_37', 'ped_38', 'ped_39', 'ped_40', 'ped_41', 'ped_42', 'ped_43', 'ped_44', 'ped_45', 'ped_46', 'ped_47', 'ped_48', 'ped_49', 'ped_50', 'ped_51', 'ped_52', 'ped_53', 'ped_54', 'ped_55', 'ped_56', 'ped_57', 'ped_58', 'ped_59', 'ped_60', 'ped_61', 'race_top_3_pre_race_rankin1_rate', 'race_top_3_pre_race_rankin3_rate', 'race_top_3_pre_race_mean_rank', 'race_top_3_pre_race_weight_mean_rank', 'race_top_3_pre_race_mean_strength', 'race_top_3_pre_race_weight_mean_strength', 'race_top_3_pre_race_total_prize', 'race_top_3_pre_race_mean_prize', 'race_top_3_pre_race_weight_mean_prize']使わないデータをnot_use_columnsとして書いておき、除外します。ただし、削除すると、あとで記録するときに困るかもしれないので、一応DataFrameとして取っておきます(not_use_df)。
また、2020年を境に、学習データとテストデータに切り分けます。
切り分けたら、StandardScalerによってデータを正規化します。
このとき、いくつかのデータはカテゴリー変数なので、それらは正規化後にもとに戻します。
正解ラベルもtrain_yとtest_yとして作成します。それぞれrankが三位以内のときに1、それ以外のときに0を表すbinary classificationデータです。
df = df.sort_values(['race_date']).reset_index(drop=True)
not_use_columns = [
'race_date', 'race_id', 'race_grade', 'name', 'jocky_name', 'odds', 'popular', 'rank', 'time', 'prize', 'tansyo_hit', 'tansyo_payout', 'hukusyo_hit', 'hukusyo_payout'
]
not_use_df = df[not_use_columns]
target_df = df.drop(columns=not_use_columns)
train_df = target_df.loc[not_use_df['race_date'] < '2020-01-01', :].reset_index(drop=True)
test_df = target_df.loc[not_use_df['race_date'] >= '2020-01-01', :].reset_index(drop=True)
from sklearn.preprocessing import StandardScaler
categoriy_columns = ['place_id', 'race_type', 'weather', 'race_condition', 'horse_count', 'waku', 'horse_number', 'sex', 'age']
scaler = StandardScaler()
train_X = pd.DataFrame(data=scaler.fit_transform(train_df), columns=train_df.columns)
test_X = pd.DataFrame(data=scaler.transform(test_df), columns=test_df.columns)
for col in categoriy_columns:
train_X.loc[:, col] = train_df.loc[:, col].astype('int64')
test_X.loc[:, col] = test_df.loc[:, col].astype('int64')
train_y = not_use_df.loc[not_use_df['race_date'] < '2020-01-01', 'rank'].reset_index(drop=True)
test_y = not_use_df.loc[not_use_df['race_date'] >= '2020-01-01', 'rank'].reset_index(drop=True)
train_y = (train_y <= 3).astype('int64')
test_y = (test_y <= 3).astype('int64')学習
学習にはoptunaのlightgbmラッパーを使います。optunaのlightgbmを使うことで、パラメータチューンを含めて学習してくれるので、Grid-Searchなどのhyper-parameter-turningのコードを書かなくても大丈夫になります。神経質な人は、書いてください。
import optuna.integration.lightgbm as lgb
#import lightgbm as lgb
params = {
'objective': 'binary',
'metric': 'binary_logloss',
'learning_rate': 0.01, # default = 0.1
}
num_round = 10000
from sklearn.model_selection import train_test_split
lgb_train_X, lgb_valid_X, lgb_train_y, lgb_valid_y = train_test_split(train_X, train_y, test_size=0.3)
lgb_train_X = lgb_train_X.reset_index(drop=True)
lgb_valid_X = lgb_valid_X.reset_index(drop=True)
lgb_train_y = lgb_train_y.reset_index(drop=True)
lgb_valid_y = lgb_valid_y.reset_index(drop=True)
lgb_train = lgb.Dataset(lgb_train_X, lgb_train_y)
lgb_eval = lgb.Dataset(lgb_valid_X, lgb_valid_y)
# training
model = lgb.train(params, lgb_train,
num_boost_round=num_round,
valid_sets=[lgb_train, lgb_eval],
valid_names=['train', 'valid'],
callbacks=[lgb.early_stopping(stopping_rounds=10, verbose=1)]
)
accuracy = lambda a, b : np.sum(a==b)/len(a)
lgb_train_pred = (model.predict(lgb_train_X) > 0.5).astype(int)
lgb_valid_pred = (model.predict(lgb_valid_X) > 0.5).astype(int)
test_pred = (model.predict(test_X) > 0.5).astype(int)
print(f'train base acc : {accuracy(np.zeros_like(lgb_train_y), lgb_train_y)}')
print(f'train acc : {accuracy(lgb_train_pred, lgb_train_y)}')
print(f'valid base acc : {accuracy(np.zeros_like(lgb_valid_y), lgb_valid_y)}')
print(f'valid acc : {accuracy(lgb_valid_pred, lgb_valid_y)}')
print(f'test base acc : {accuracy(np.zeros_like(test_y), test_y)}')
print(f'test acc : {accuracy(test_pred, test_y)}')計算過程が色々表示されますが、最終的にはaccuracyが表示されます。
baseと書かれているものは、予測をせずにすべて0ラベルを回答したときのものです。
train base acc : 0.7878342601623957
train acc : 0.8354356941084073
valid base acc : 0.7867749639403183
valid acc : 0.7970194604052872
test base acc : 0.7829890414949492
test acc : 0.7914114108968152作ったモデルやスカラー変換器を保存しておきます。
import pickle
result = {
'not_use_columns':not_use_columns,
'category_columns':categoriy_columns,
'scaler':scaler,
'model':model
}
with open('/work/models/chapter2_section1_top3_pred_model_result', 'wb') as f:
pickle.dump(result, f)学習結果の解析
学習データは83%となっていますが、バリデーションやテストデータのaccuracyはほとんど向上していないことが分かります。
また、本当に重要なのは、予測器が1の(当たるといった)とき、本当に当たるかです。それも計算してみます。
def out_one_accuracy(model, data_X, data_y):
pred = model.predict(data_X) > 0.5
data_y = data_y[pred].to_numpy()
return np.sum(data_y==1)/len(data_y)
print(f'train out 1 acc : {out_one_accuracy(model, lgb_train_X, lgb_train_y)}')
print(f'valid out 1 acc : {out_one_accuracy(model, lgb_valid_X, lgb_valid_y)}')
print(f'test out 1 acc : {out_one_accuracy(model, test_X, test_y)}')結果は次の通りでした。テストデータで57%程度の正答率となります。
train out 1 acc : 0.8499012998621922
valid out 1 acc : 0.5900821291194511
test out 1 acc : 0.5696471588493695利益の解析
次は利益を計算してみます。
train_hukusyo_df = not_use_df.loc[not_use_df['race_date'] < '2020-01-01', ['hukusyo_hit', 'hukusyo_payout']].reset_index(drop=True)
test_hukusyo_df = not_use_df.loc[not_use_df['race_date'] >= '2020-01-01', ['hukusyo_hit', 'hukusyo_payout']].reset_index(drop=True)
train_hukusyo_df = train_hukusyo_df.fillna(0)
test_hukusyo_df = test_hukusyo_df.fillna(0)
train_pred = model.predict(train_X)
test_pred = model.predict(test_X)
def calc_win_money(pred, hukusyo_df, th=0.5):
bet = (pred > th).astype(int)
hit = hukusyo_df['hukusyo_hit'].to_numpy()
payout = hukusyo_df['hukusyo_payout'].to_numpy()
return_money = np.sum(bet * hit * payout)
bet_money = np.sum(bet)
win_money = return_money - bet_money
return win_money
print(f'train win money :{calc_win_money(train_pred, train_hukusyo_df, 0.5)}')
print(f'test win money :{calc_win_money(test_pred, test_hukusyo_df, 0.5)}')学習データでは利益がでましたが、テストデータでは損益がでています。
train win money :8886.969999999994
test win money :-1079.0499999999984賭けるときの、しきい値を0.5から変動させたときに、利益がどのように推移するかを見てみます。基本的にはしきい値が高いほうが確信度が高いため、正答率は高くなります。
train_win_list = []
test_win_list = []
th_list = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
for th in th_list:
train_win_list.append(calc_win_money(model, train_X, train_hukusyo_df, th))
test_win_list.append(calc_win_money(model, test_X, test_hukusyo_df, th))
plt.plot(th_list, train_win_list, label='train')
plt.plot(th_list, test_win_list, label='test')
plt.legend()
plt.xlabel('th')
plt.ylabel('win money')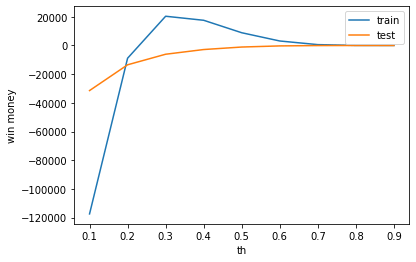
やはり学習データでは利益がでますが、テストデータでは利益がでません。
また、このあとも不均衡データのための調整等を行いましたが、テストデータで利益を上げることはできませんでした。
