
LightGBMと同様に1位を予測するBinary Classificationを行います
学習過程はipynbファイルで行いました。以下はその記録です。
前処理
基本的にChapter03の前処理はほぼ同じです。教師データとなる列名によって、すこしコードをいじる程度の使いまわしです。
まず、使いそうなライブラリをインポートします。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from IPython.display import display, Math学習データの読み込み
df = pd.read_pickle('/work/formatted_source_data/analysis_data03.pkl')次に学習データとテストデータ、バリデーションデータの切り分け、および入力データと教師データの切り分けをします。データの正規化もします。
pytorchの学習はデフォルトがfloat32型なので、numpyのfloat32型へ変えておきます。
df = df.sort_values(['race_date']).reset_index(drop=True)
not_use_columns = [
'race_date', 'race_id', 'race_grade'
]
for n in range(1, 19):
for col_keyword in ['name', 'jocky_name', 'odds', 'popular', 'rank', 'time', 'prize', 'tansyo_hit', 'tansyo_payout', 'hukusyo_hit', 'hukusyo_payout']:
not_use_columns.append(f'horse_{n}_{col_keyword}')
not_use_columns += [col for col in df.columns if 'ped' in col]
not_use_df = df[not_use_columns]
target_df = df.drop(columns=not_use_columns)
train_df = target_df.loc[not_use_df['race_date'] < '2018-01-01', :].reset_index(drop=True)
valid_df = target_df.loc[('2018-01-01' <= not_use_df['race_date']) & (not_use_df['race_date'] < '2022-01-01'), :].reset_index(drop=True)
test_df = target_df.loc['2022-01-01' <= not_use_df['race_date'], :].reset_index(drop=True)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
train_X = scaler.fit_transform(train_df).astype(np.float32)
valid_X = scaler.transform(valid_df).astype(np.float32)
test_X = scaler.transform(test_df).astype(np.float32)
target_col_keyward = 'tansyo_hit'
Y_columns = [f'horse_{n}_{target_col_keyward}' for n in range(1, 19)]
train_Y = not_use_df.loc[not_use_df['race_date'] < '2018-01-01', Y_columns].reset_index(drop=True)
valid_Y = not_use_df.loc[('2018-01-01' <= not_use_df['race_date']) & (not_use_df['race_date'] < '2022-01-01'), Y_columns].reset_index(drop=True)
test_Y = not_use_df.loc['2022-01-01' <= not_use_df['race_date'], Y_columns].reset_index(drop=True)
train_Y = train_Y.to_numpy().astype(np.float32)
valid_Y = valid_Y.to_numpy().astype(np.float32)
test_Y = test_Y.to_numpy().astype(np.float32)学習
pytorchのライブラリ群をインポートします
import torch
from torch import nn
from torch.autograd import Variable学習パラーメターを設定します。
batch_size = 1024
learning_rate = 0.001
max_epoch = 30numpyデータからtorchのTensor型、およびそれらをミニバッチで切り出すDataLoaderへと変換します。valid_loaderはこの程度のバッチ数とモデルサイズだったら、一度で処理できるので必要ありませんが、モデルサイズが大きくなると切り出さないと処理できなくなるため、一応書きました。
Y_maskデータは、出力データが存在しない場合をマスキングして取り除くために使います。
train_X = np.nan_to_num(train_X)
valid_X = np.nan_to_num(valid_X)
test_X = np.nan_to_num(test_X)
train_Y_mask = np.isfinite(train_Y)
valid_Y_mask = np.isfinite(valid_Y)
test_Y_mask = np.isfinite(test_Y)
train_Y = np.nan_to_num(train_Y)
valid_Y = np.nan_to_num(valid_Y)
test_Y = np.nan_to_num(test_Y)
train_dataset = torch.utils.data.TensorDataset(torch.from_numpy(train_X), torch.from_numpy(train_Y), torch.from_numpy(train_Y_mask))
valid_dataset = torch.utils.data.TensorDataset(torch.from_numpy(valid_X), torch.from_numpy(valid_Y), torch.from_numpy(valid_Y_mask))
#test_dataset = torch.utils.data.TensorDataset(torch.from_numpy(test_X), torch.from_numpy(test_Y))
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
valid_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=batch_size, shuffle=True)ネットワークとオプティマイザーを作ります。損失関数はBinaryCrossEntropyLoss(BCELoss)を使いました。オプティマイザーは汎用的に使えるAdamWを使いました。
class NeuralNetwork(nn.Module):
def __init__(self, input_dim, output_dim):
super(NeuralNetwork, self).__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 512),
nn.ReLU(),
nn.BatchNorm1d(512),
nn.Dropout(0.5),
nn.Linear(512, 1024),
nn.ReLU(),
nn.BatchNorm1d(1024),
nn.Dropout(0.5),
nn.Linear(1024, 128),
nn.ReLU(),
nn.BatchNorm1d(128),
nn.Dropout(0.5),
nn.Linear(128, output_dim),
nn.Sigmoid()
)
def forward(self, x):
return self.net(x)
device = torch.device('cuda')
loss_func = nn.BCELoss()
model = NeuralNetwork(train_X.shape[1], train_Y.shape[1])
model.to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)では、学習させていきます。バリデーションデータが最も良い地点でモデルを保存して、最後にそれを読み込んでいます。
best_valid = {
'score':None,
'epoch':0,
'model_path':None
}
logging = []
for epoch in range(max_epoch):
model.train()
train_loss = 0
model.train()
for X, Y, Y_mask in train_loader:
X = Variable(X.to(device), requires_grad=True)
Y = Variable(Y.to(device))
Y_mask = Variable(Y_mask.to(device))
optimizer.zero_grad()
out = model(X)
loss = loss_func(out[Y_mask], Y[Y_mask])
train_loss += loss.item() * X.shape[0]
loss.backward()
optimizer.step()
train_loss = train_loss / len(train_X)
model.eval()
with torch.no_grad():
valid_loss = 0
for X, Y, Y_mask in valid_loader:
X = Variable(X.to(device))
Y = Variable(Y.to(device))
Y_mask = Variable(Y_mask.to(device))
out = model(X)
loss = loss_func(out[Y_mask], Y[Y_mask])
valid_loss += loss.item() * X.shape[0]
valid_loss = valid_loss / len(valid_X)
print(f'-------epoch : {epoch} ----------')
print(f'loss')
print(f' train loss : {train_loss}')
print(f' valid loss : {valid_loss}')
logging.append({
'train_loss': train_loss,
'valid_loss': valid_loss,
})
save_path = f'/work/models/chapter3_section2.model'
if best_valid['score'] == None or best_valid['score'] > valid_loss:
best_valid['score'] = valid_loss
best_valid['epoch'] = epoch
best_valid['model_path'] = save_path
torch.save(model.state_dict(), save_path)
model.load_state_dict(torch.load(best_valid['model_path']))実行すると、ログが流れます。
...
loss
train loss : 0.21969259853553075
valid loss : 0.2670241122583838
-------epoch : 27 ----------
loss
train loss : 0.21650702627775684
valid loss : 0.26868198579171454
-------epoch : 28 ----------
loss
train loss : 0.21435589612439995
valid loss : 0.2696654831906747
-------epoch : 29 ----------
loss
train loss : 0.2108408135445956
valid loss : 0.27245356111488434学習結果の解析
学習曲線を見てみます
logging_df = pd.DataFrame(logging)
plt.plot(logging_df['train_loss'], label='train loss')
plt.plot(logging_df['valid_loss'], label='valid loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()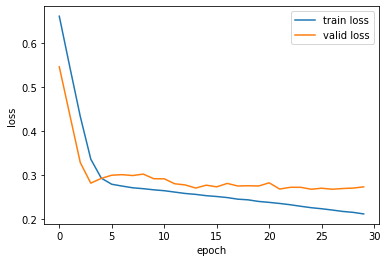
まぁ妥当な感じがします。バリデーションがすこしガタついていますが、問題ないでしょう。
次に、出力の分布を見てみます。一度、モデルの出力値を吐き出し、numpy型へと変換します。
train_pred = model(torch.from_numpy(train_X).to(device)).cpu().detach().numpy()
valid_pred = model(torch.from_numpy(valid_X).to(device)).cpu().detach().numpy()
test_pred = model(torch.from_numpy(test_X).to(device)).cpu().detach().numpy()その後、各データをマスクして、分布を見てみます。
train_pred_p =train_pred[train_Y_mask]
valid_pred_p = valid_pred[valid_Y_mask]
test_pred_p = test_pred[test_Y_mask]
train_Y_flat = train_Y[train_Y_mask]
valid_Y_flat = valid_Y[valid_Y_mask]
test_Y_flat = test_Y[test_Y_mask]
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(131)
plt.hist(train_pred_p[train_Y_flat==0], bins=10, label='not hit', alpha=0.5)
plt.hist(train_pred_p[train_Y_flat==1], bins=10, label='hit', alpha=0.5)
plt.legend()
plt.title('train')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(132)
plt.hist(valid_pred_p[valid_Y_flat==0], bins=10, label='not hit', alpha=0.5)
plt.hist(valid_pred_p[valid_Y_flat==1], bins=10, label='hit', alpha=0.5)
plt.legend()
plt.title('valid')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(133)
plt.hist(test_pred_p[test_Y_flat==0], bins=10, label='not hit', alpha=0.5)
plt.hist(test_pred_p[test_Y_flat==1], bins=10, label='hit', alpha=0.5)
plt.legend()
plt.title('test')
plt.xlabel('pred')
plt.ylabel('y')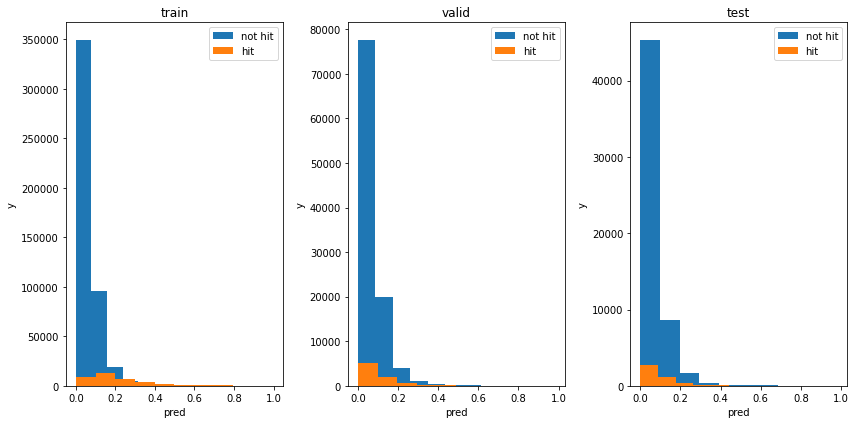
妥当な結果だと思います。あんまり、青とオレンジの分布が分離していないので、予測は難しかったようです。
accuracyはどうでしょう。確認します。
accuracy = lambda a,b : np.sum(a==b)/len(a)
th = 0.5
train_pred_bet = (train_pred > th).astype(int)
valid_pred_bet = (valid_pred > th).astype(int)
test_pred_bet = (test_pred > th).astype(int)
print(f'train base acc : {accuracy(np.zeros_like(train_Y[train_Y_mask]), train_Y[train_Y_mask])}')
print(f'train acc : {accuracy(train_pred_bet[train_Y_mask], train_Y[train_Y_mask])}')
print(f'valid base acc : {accuracy(np.zeros_like(valid_Y[valid_Y_mask]), valid_Y[valid_Y_mask])}')
print(f'valid acc : {accuracy(valid_pred_bet[valid_Y_mask], valid_Y[valid_Y_mask])}')
print(f'test base acc : {accuracy(np.zeros_like(test_Y[test_Y_mask]), test_Y[test_Y_mask])}')
print(f'test acc : {accuracy(test_pred_bet[test_Y_mask], test_Y[test_Y_mask])}')ベースラインよりも悪くなってしまっています。明らかな学習失敗です。おそらく、教師データが不均衡すぎたのだと思います。
train base acc : 0.9294191720447033
train acc : 0.9332834881158508
valid base acc : 0.9281997452046438
valid acc : 0.9271949184475426
test base acc : 0.9275250451634094
test acc : 0.9254393168007883利益の解析
利益を計算してみます。
target_col_keyward = 'tansyo_payout'
Y_columns = [f'horse_{n}_{target_col_keyward}' for n in range(1, 19)]
train_payout_Y = not_use_df.loc[not_use_df['race_date'] < '2018-01-01', Y_columns].reset_index(drop=True)
valid_payout_Y = not_use_df.loc[('2018-01-01' <= not_use_df['race_date']) & (not_use_df['race_date'] < '2022-01-01'), Y_columns].reset_index(drop=True)
test_payout_Y = not_use_df.loc['2022-01-01' <= not_use_df['race_date'], Y_columns].reset_index(drop=True)
train_payout_Y = train_payout_Y.to_numpy().astype(np.float32)
valid_payout_Y = valid_payout_Y.to_numpy().astype(np.float32)
test_payout_Y = test_payout_Y.to_numpy().astype(np.float32)
th = 0.5
train_pred_bet = (train_pred > th).astype(int)
valid_pred_bet = (valid_pred > th).astype(int)
test_pred_bet = (test_pred > th).astype(int)
train_win = np.sum(train_pred_bet[train_Y_mask] * train_payout_Y[train_Y_mask] - 1.0)
valid_win = np.sum(valid_pred_bet[valid_Y_mask] * valid_payout_Y[valid_Y_mask] - 1.0)
test_win = np.sum(test_pred_bet[test_Y_mask] * test_payout_Y[test_Y_mask] - 1.0)
print(f'train win : {train_win}')
print(f'valid win : {valid_win}')
print(f'test win : {test_win}')学習、バリデーション、テスト、すべてのデータでマイナスの利益でした。
train win : -497913.8999890089
valid win : -111176.69999337196
test win : -60783.80000054836