
Neural Networkを導入した理由は、LightGBMと違って多出力を考慮できるためでした。
今までのSectionでは、同じレース内の目的変数を同時に予測することを目標にしていましたが、今度は、複数の目的変数を同時に予測することを目標としたいと思います。
これにはNeuralNetworkの研究分野では、ある目的変数を予測するときに別の目的変数も同時に予測することで、精度が上がるという報告があります。
これの理由として
- 目的が増えることで、過学習が抑制される
- 目的への補助となる教師が与えられる
などの解釈がされています。
今回の例だと、タイムを当てるのにオッズを当てる事が重要となる、また、オッズの教師データが学習の手助けとなる、といった感じです。
そこで今回の実験では、これまでに扱った目的変数(三位以内、1位以内、順位、タイム、オッズ)を同時に予測してみます。
学習過程はipynbファイルで行いました。以下はその記録です。
前処理
基本的にChapter03の前処理はほぼ同じです。教師データとなる列名によって、すこしコードをいじる程度の使いまわしです。
まず、使いそうなライブラリをインポートします。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from IPython.display import display, Math学習データの読み込み
df = pd.read_pickle('/work/formatted_source_data/analysis_data03.pkl')タイムデータ(文字列)を秒数タイムデータ(float)へ変換します。
def time_str_to_sec_float(time_str):
sp_df = time_str.str.split(':', expand=True)
sp_df.columns = ['min', 'sec']
sp_df = sp_df.astype('float64')
return sp_df['min']*60 + sp_df['sec']
for n in range(1, 19):
df[f'horse_{n}_time_sec'] = time_str_to_sec_float(df[f'horse_{n}_time'])次に、入力データについて、学習データとテストデータ、バリデーションデータの切り分け、および入力データと教師データの切り分けをします。データの正規化もします。
ここまでは、前回と変わりありません。
df = df.sort_values(['race_date']).reset_index(drop=True)
not_use_columns = [
'race_date', 'race_id', 'race_grade'
]
for n in range(1, 19):
for col_keyword in ['name', 'jocky_name', 'odds', 'popular', 'rank', 'time', 'prize', 'tansyo_hit', 'tansyo_payout', 'hukusyo_hit', 'hukusyo_payout', 'time_sec']:
not_use_columns.append(f'horse_{n}_{col_keyword}')
not_use_columns += [col for col in df.columns if 'ped' in col]
not_use_df = df[not_use_columns]
target_df = df.drop(columns=not_use_columns)
train_df = target_df.loc[not_use_df['race_date'] < '2018-01-01', :].reset_index(drop=True)
valid_df = target_df.loc[('2018-01-01' <= not_use_df['race_date']) & (not_use_df['race_date'] < '2022-01-01'), :].reset_index(drop=True)
test_df = target_df.loc['2022-01-01' <= not_use_df['race_date'], :].reset_index(drop=True)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
train_X = scaler.fit_transform(train_df).astype(np.float32)
valid_X = scaler.transform(valid_df).astype(np.float32)
test_X = scaler.transform(test_df).astype(np.float32)そしたら、前処理が必要な順位データと、オッズデータについては処理を施します。
for n in range(1, 19):
not_use_df[f'horse_{n}_relative_rank'] = (not_use_df[f'horse_{n}_rank'] - 1.0) / (target_df['horse_count'] - 1.0)
not_use_df[f'horse_{n}_odds_log'] = np.log(not_use_df[f'horse_{n}_odds'])その後、各目的変数についても、学習データとテストデータ、バリデーションデータの切り分け、および入力データと教師データの切り分けをします。データの正規化もします。
target_col_keyward = 'tansyo_hit'
Y_columns = [f'horse_{n}_{target_col_keyward}' for n in range(1, 19)]
train_thit_Y = not_use_df.loc[not_use_df['race_date'] < '2018-01-01', Y_columns].reset_index(drop=True)
valid_thit_Y = not_use_df.loc[('2018-01-01' <= not_use_df['race_date']) & (not_use_df['race_date'] < '2022-01-01'), Y_columns].reset_index(drop=True)
test_thit_Y = not_use_df.loc['2022-01-01' <= not_use_df['race_date'], Y_columns].reset_index(drop=True)
train_thit_Y = train_thit_Y.to_numpy().astype(np.float32)
valid_thit_Y = valid_thit_Y.to_numpy().astype(np.float32)
test_thit_Y = test_thit_Y.to_numpy().astype(np.float32)
target_col_keyward = 'hukusyo_hit'
Y_columns = [f'horse_{n}_{target_col_keyward}' for n in range(1, 19)]
train_hhit_Y = not_use_df.loc[not_use_df['race_date'] < '2018-01-01', Y_columns].reset_index(drop=True)
valid_hhit_Y = not_use_df.loc[('2018-01-01' <= not_use_df['race_date']) & (not_use_df['race_date'] < '2022-01-01'), Y_columns].reset_index(drop=True)
test_hhit_Y = not_use_df.loc['2022-01-01' <= not_use_df['race_date'], Y_columns].reset_index(drop=True)
train_hhit_Y = train_hhit_Y.to_numpy().astype(np.float32)
valid_hhit_Y = valid_hhit_Y.to_numpy().astype(np.float32)
test_hhit_Y = test_hhit_Y.to_numpy().astype(np.float32)
target_col_keyward = 'relative_rank'
Y_columns = [f'horse_{n}_{target_col_keyward}' for n in range(1, 19)]
train_rrank_Y = not_use_df.loc[not_use_df['race_date'] < '2018-01-01', Y_columns].reset_index(drop=True)
valid_rrank_Y = not_use_df.loc[('2018-01-01' <= not_use_df['race_date']) & (not_use_df['race_date'] < '2022-01-01'), Y_columns].reset_index(drop=True)
test_rrank_Y = not_use_df.loc['2022-01-01' <= not_use_df['race_date'], Y_columns].reset_index(drop=True)
train_rrank_Y = train_rrank_Y.to_numpy().astype(np.float32)
valid_rrank_Y = valid_rrank_Y.to_numpy().astype(np.float32)
test_rrank_Y = test_rrank_Y.to_numpy().astype(np.float32)
target_col_keyward = 'time_sec'
Y_columns = [f'horse_{n}_{target_col_keyward}' for n in range(1, 19)]
train_timesec_Y = not_use_df.loc[not_use_df['race_date'] < '2018-01-01', Y_columns].reset_index(drop=True)
valid_timesec_Y = not_use_df.loc[('2018-01-01' <= not_use_df['race_date']) & (not_use_df['race_date'] < '2022-01-01'), Y_columns].reset_index(drop=True)
test_timesec_Y = not_use_df.loc['2022-01-01' <= not_use_df['race_date'], Y_columns].reset_index(drop=True)
scaler_time_sec_Y = StandardScaler()
train_timesec_Y = scaler_time_sec_Y.fit_transform(train_timesec_Y).astype(np.float32)
valid_timesec_Y = scaler_time_sec_Y.transform(valid_timesec_Y).astype(np.float32)
test_timesec_Y = scaler_time_sec_Y.transform(test_timesec_Y).astype(np.float32)
target_col_keyward = 'odds_log'
Y_columns = [f'horse_{n}_{target_col_keyward}' for n in range(1, 19)]
train_oddslog_Y = not_use_df.loc[not_use_df['race_date'] < '2018-01-01', Y_columns].reset_index(drop=True)
valid_oddslog_Y = not_use_df.loc[('2018-01-01' <= not_use_df['race_date']) & (not_use_df['race_date'] < '2022-01-01'), Y_columns].reset_index(drop=True)
test_oddslog_Y = not_use_df.loc['2022-01-01' <= not_use_df['race_date'], Y_columns].reset_index(drop=True)
scaler_oddslog_Y = StandardScaler()
train_oddslog_Y = scaler_oddslog_Y.fit_transform(train_oddslog_Y).astype(np.float32)
valid_oddslog_Y = scaler_oddslog_Y.transform(valid_oddslog_Y).astype(np.float32)
test_oddslog_Y = scaler_oddslog_Y.transform(test_oddslog_Y).astype(np.float32)学習
pytorchのライブラリ群をインポートします
import torch
from torch import nn
from torch.autograd import Variable学習パラーメターを設定します。30epochだと収束しなそうだったので、100epoch学習しました。
batch_size = 128
learning_rate = 0.001
max_epoch = 30numpyデータからtorchのTensor型、およびそれらをミニバッチで切り出すDataLoaderへと変換します。valid_loaderはこの程度のバッチ数とモデルサイズだったら、一度で処理できるので必要ありませんが、モデルサイズが大きくなると切り出さないと処理できなくなるため、一応書きました。
Y_maskデータは、出力データが存在しない場合をマスキングして取り除くために使います。
train_X = np.nan_to_num(train_X)
valid_X = np.nan_to_num(valid_X)
test_X = np.nan_to_num(test_X)
train_Y_mask = np.isfinite(train_thit_Y).astype(np.float32)
valid_Y_mask = np.isfinite(valid_thit_Y).astype(np.float32)
test_Y_mask = np.isfinite(test_thit_Y).astype(np.float32)
train_thit_Y = np.nan_to_num(train_thit_Y)
valid_thit_Y = np.nan_to_num(valid_thit_Y)
test_thit_Y = np.nan_to_num(test_thit_Y)
train_hhit_Y = np.nan_to_num(train_hhit_Y)
valid_hhit_Y = np.nan_to_num(valid_hhit_Y)
test_hhit_Y = np.nan_to_num(test_hhit_Y)
train_rrank_Y = np.nan_to_num(train_rrank_Y)
valid_rrank_Y = np.nan_to_num(valid_rrank_Y)
test_rrank_Y = np.nan_to_num(test_rrank_Y)
train_timesec_Y = np.nan_to_num(train_timesec_Y)
valid_timesec_Y = np.nan_to_num(valid_timesec_Y)
test_timesec_Y = np.nan_to_num(test_timesec_Y)
train_oddslog_Y = np.nan_to_num(train_oddslog_Y)
valid_oddslog_Y = np.nan_to_num(valid_oddslog_Y)
test_oddslog_Y = np.nan_to_num(test_oddslog_Y)
train_dataset = torch.utils.data.TensorDataset(torch.from_numpy(train_X), torch.from_numpy(train_Y_mask),
torch.from_numpy(train_thit_Y), torch.from_numpy(train_hhit_Y), torch.from_numpy(train_rrank_Y), torch.from_numpy(train_timesec_Y), torch.from_numpy(train_oddslog_Y))
valid_dataset = torch.utils.data.TensorDataset(torch.from_numpy(valid_X), torch.from_numpy(valid_Y_mask),
torch.from_numpy(valid_thit_Y), torch.from_numpy(valid_hhit_Y), torch.from_numpy(valid_rrank_Y), torch.from_numpy(valid_timesec_Y), torch.from_numpy(valid_oddslog_Y))
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
valid_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=batch_size, shuffle=True)ネットワークとオプティマイザーを作ります。損失関数はBCELossおよび、MSELossを使いました。オプティマイザーは汎用的に使えるAdamWを使いました。
各目的変数についての最終層を用意し、それぞれに対して処理をします。
class NeuralNetwork(nn.Module):
def __init__(self, input_dim, output_dim):
super(NeuralNetwork, self).__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 512),
nn.ReLU(),
nn.BatchNorm1d(512),
nn.Dropout(0.2),
nn.Linear(512, 1024),
nn.ReLU(),
nn.BatchNorm1d(1024),
nn.Dropout(0.2),
nn.Linear(1024, 128),
nn.ReLU(),
nn.BatchNorm1d(128),
nn.Dropout(0.2),
)
self.thit_layer = nn.Sequential(nn.Linear(128, output_dim), nn.Sigmoid())
self.hhit_layer = nn.Sequential(nn.Linear(128, output_dim), nn.Sigmoid())
self.rrank_layer = nn.Linear(128, output_dim)
self.timesec_layer = nn.Linear(128, output_dim)
self.oddslog_layer = nn.Linear(128, output_dim)
def forward(self, x, mask):
x = self.net(x)
y1 = self.thit_layer(x) * mask
y2 = self.hhit_layer(x) * mask
y3 = self.rrank_layer(x) * mask
y4 = self.timesec_layer(x) * mask
y5 = self.oddslog_layer(x) * mask
return y1, y2, y3, y4, y5
device = torch.device('cuda')
bce_loss_func = nn.BCELoss()
l1_loss_func = nn.MSELoss()
model = NeuralNetwork(train_X.shape[1], train_Y_mask.shape[1])
model.to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=learning_rate)では、学習させていきます。バリデーションデータが最も良い地点でモデルを保存して、最後にそれを読み込んでいます。
best_valid = {
'score':None,
'epoch':0,
'model_path':None
}
logging = []
for epoch in range(max_epoch):
model.train()
train_loss = 0
model.train()
for X, Y_mask, Y_thit, Y_hhit, Y_rrank, Y_timesec, Y_oddslog in train_loader:
X = Variable(X.to(device), requires_grad=True)
Y_mask = Variable(Y_mask.to(device), requires_grad=True)
Y_thit = Variable(Y_thit.to(device))
Y_hhit = Variable(Y_hhit.to(device))
Y_rrank = Variable(Y_rrank.to(device))
Y_timesec = Variable(Y_timesec.to(device))
Y_oddslog = Variable(Y_oddslog.to(device))
optimizer.zero_grad()
out1, out2, out3, out4, out5 = model(X, Y_mask)
loss_thit = bce_loss_func(out1, Y_thit)
loss_hhit = bce_loss_func(out2, Y_hhit)
loss_rrank = l1_loss_func(out3, Y_rrank)
loss_timesec = l1_loss_func(out4, Y_timesec)
loss_oddslog = l1_loss_func(out5, Y_oddslog)
loss = loss_thit + loss_hhit + loss_rrank + loss_timesec + loss_oddslog
train_loss += loss.item() * X.shape[0]
loss.backward()
optimizer.step()
train_loss = train_loss / len(train_X)
model.eval()
with torch.no_grad():
valid_loss = 0
for X, Y_mask, Y_thit, Y_hhit, Y_rrank, Y_timesec, Y_oddslog in valid_loader:
X = Variable(X.to(device), requires_grad=True)
Y_mask = Variable(Y_mask.to(device))
Y_thit = Variable(Y_thit.to(device))
Y_hhit = Variable(Y_hhit.to(device))
Y_rrank = Variable(Y_rrank.to(device))
Y_timesec = Variable(Y_timesec.to(device))
Y_oddslog = Variable(Y_oddslog.to(device))
optimizer.zero_grad()
out1, out2, out3, out4, out5 = model(X, Y_mask)
loss_thit = bce_loss_func(out1, Y_thit)
loss_hhit = bce_loss_func(out2, Y_hhit)
loss_rrank = l1_loss_func(out3, Y_rrank)
loss_timesec = l1_loss_func(out4, Y_timesec)
loss_oddslog = l1_loss_func(out5, Y_oddslog)
loss = loss_thit + loss_hhit + loss_rrank + loss_timesec + loss_oddslog
valid_loss += loss.item() * X.shape[0]
valid_loss = valid_loss / len(valid_X)
print(f'-------epoch : {epoch} ----------')
print(f'loss')
print(f' train loss : {train_loss}')
print(f' valid loss : {valid_loss}')
logging.append({
'train_loss': train_loss,
'valid_loss': valid_loss,
#'l2_loss': l2.item()*alpha,
})
save_path = f'/work/models/chapter3_section6_multiout.model'
if best_valid['score'] == None or best_valid['score'] > valid_loss:
best_valid['score'] = valid_loss
best_valid['epoch'] = epoch
best_valid['model_path'] = save_path
torch.save(model.state_dict(), save_path)
model.load_state_dict(torch.load(best_valid['model_path']))実行すると、ログが流れます。
...
-------epoch : 26 ----------
loss
train loss : 0.9763701431785646
valid loss : 1.0298888443235537
-------epoch : 27 ----------
loss
train loss : 0.971948601150688
valid loss : 1.032468459585061
-------epoch : 28 ----------
loss
train loss : 0.9670959621367399
valid loss : 1.0354180181244987
-------epoch : 29 ----------
loss
train loss : 0.9631742637602192
valid loss : 1.0359286463815147学習結果の解析
学習曲線を見てみます
logging_df = pd.DataFrame(logging)
plt.plot(logging_df['train_loss'], label='train loss')
plt.plot(logging_df['valid_loss'], label='valid loss')
plt.xlabel('epoch')
plt.ylabel('loss')
plt.legend()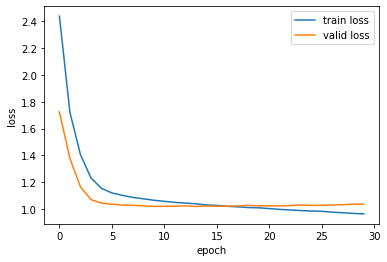
いい感じだと思います。
一度、モデルの出力値を吐き出し、numpy型へと変換します。
X = torch.from_numpy(train_X).to(device)
Y_mask = torch.from_numpy(train_Y_mask).to(device)
train_thit_pred, train_hhit_pred, train_rrank_pred, train_timesec_pred, train_oddslog_pred = [out.cpu().detach().numpy() for out in model(X, Y_mask)]
X = torch.from_numpy(valid_X).to(device)
Y_mask = torch.from_numpy(valid_Y_mask).to(device)
valid_thit_pred, valid_hhit_pred, valid_rrank_pred, valid_timesec_pred, valid_oddslog_pred = [out.cpu().detach().numpy() for out in model(X, Y_mask)]
X = torch.from_numpy(test_X).to(device)
Y_mask = torch.from_numpy(test_Y_mask).to(device)
test_thit_pred, test_hhit_pred, test_rrank_pred, test_timesec_pred, test_oddslog_pred = [out.cpu().detach().numpy() for out in model(X, Y_mask)]それぞれの目的変数に対しての結果を見ていきましょう。
1位の予測
1位か否かを予測した出力の分布を見てみます。
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(131)
plt.hist(train_thit_pred[(train_thit_Y==0) & (train_Y_mask==1)], bins=10, label='not hit', alpha=0.5)
plt.hist(train_thit_pred[(train_thit_Y==1) & (train_Y_mask==1)], bins=10, label='hit', alpha=0.5)
plt.legend()
plt.title('train')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(132)
plt.hist(valid_thit_pred[(valid_thit_Y==0) & (valid_Y_mask==1)], bins=10, label='not hit', alpha=0.5)
plt.hist(valid_thit_pred[(valid_thit_Y==1) & (valid_Y_mask==1)], bins=10, label='hit', alpha=0.5)
plt.legend()
plt.title('valid')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(133)
plt.hist(test_thit_pred[(test_thit_Y==0) & (test_Y_mask==1)], bins=10, label='not hit', alpha=0.5)
plt.hist(test_thit_pred[(test_thit_Y==1) & (test_Y_mask==1)], bins=10, label='hit', alpha=0.5)
plt.legend()
plt.title('test')
plt.xlabel('pred')
plt.ylabel('y')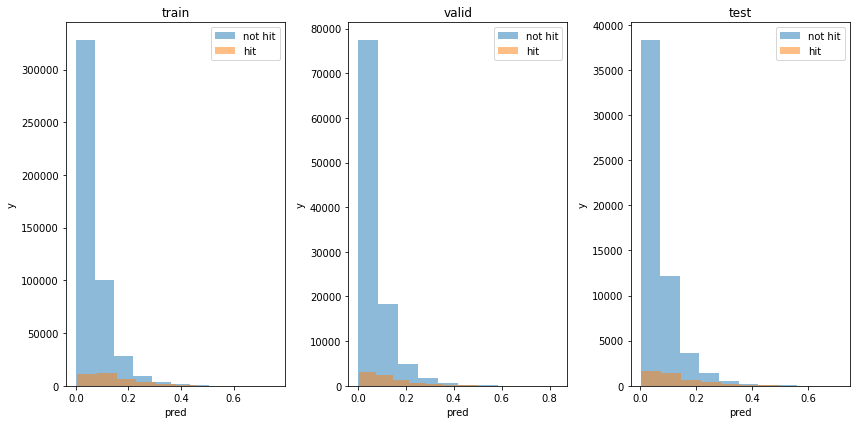
単体で予測したときとほぼ変わりないのではないです。
accuracyを確認すると、単体で予測したときよりはいいですが、基準値と同程度であり、あまり予測できているとは言えません。
accuracy = lambda a,b : np.sum(a==b)/len(a)
th = 0.5
train_pred_bet = (train_thit_pred > th).astype(int)
valid_pred_bet = (valid_thit_pred > th).astype(int)
test_pred_bet = (test_thit_pred > th).astype(int)
print(f'train base acc : {accuracy(np.zeros_like(train_thit_Y[train_Y_mask==1]), train_thit_Y[train_Y_mask==1])}')
print(f'train acc : {accuracy(train_pred_bet[train_Y_mask==1], train_thit_Y[train_Y_mask==1])}')
print(f'valid base acc : {accuracy(np.zeros_like(valid_thit_Y[valid_Y_mask==1]), valid_thit_Y[valid_Y_mask==1])}')
print(f'valid acc : {accuracy(valid_pred_bet[valid_Y_mask==1], valid_thit_Y[valid_Y_mask==1])}')
print(f'test base acc : {accuracy(np.zeros_like(test_thit_Y[test_Y_mask==1]), test_thit_Y[test_Y_mask==1])}')
print(f'test acc : {accuracy(test_pred_bet[test_Y_mask==1], test_thit_Y[test_Y_mask==1])}')train base acc : 0.9294191720447033
train acc : 0.9295096804659216
valid base acc : 0.9281997452046438
valid acc : 0.9279036801779978
test base acc : 0.9275250451634094
test acc : 0.92736081458367553位以内の予測
3位以内か否かを予測した出力の分布を見てみます。
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(131)
plt.hist(train_hhit_pred[(train_hhit_Y==0) & (train_Y_mask==1)], bins=10, label='not hit', alpha=0.5)
plt.hist(train_hhit_pred[(train_hhit_Y==1) & (train_Y_mask==1)], bins=10, label='hit', alpha=0.5)
plt.legend()
plt.title('train')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(132)
plt.hist(valid_hhit_pred[(valid_hhit_Y==0) & (valid_Y_mask==1)], bins=10, label='not hit', alpha=0.5)
plt.hist(valid_hhit_pred[(valid_hhit_Y==1) & (valid_Y_mask==1)], bins=10, label='hit', alpha=0.5)
plt.legend()
plt.title('valid')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(133)
plt.hist(test_hhit_pred[(test_hhit_Y==0) & (test_Y_mask==1)], bins=10, label='not hit', alpha=0.5)
plt.hist(test_hhit_pred[(test_hhit_Y==1) & (test_Y_mask==1)], bins=10, label='hit', alpha=0.5)
plt.legend()
plt.title('test')
plt.xlabel('pred')
plt.ylabel('y')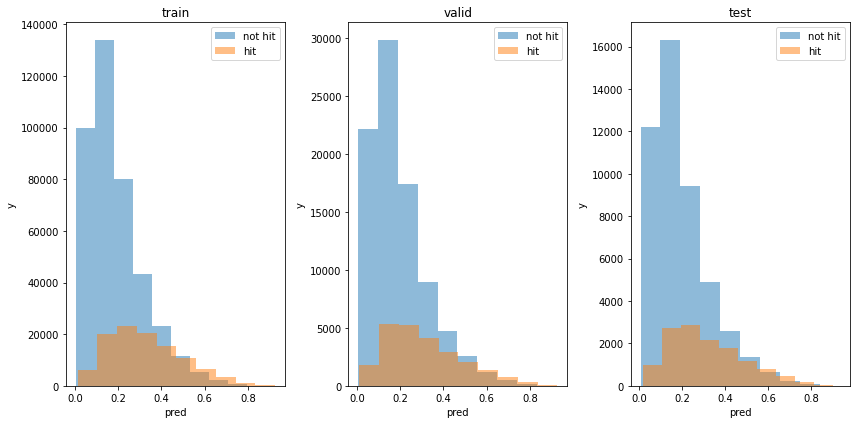
単体で予測したときと同程度です。
accuracyも見てみます
accuracy = lambda a,b : np.sum(a==b)/len(a)
th = 0.5
train_pred_bet = (train_hhit_pred > th).astype(int)
valid_pred_bet = (valid_hhit_pred > th).astype(int)
test_pred_bet = (test_hhit_pred > th).astype(int)
print(f'train base acc : {accuracy(np.zeros_like(train_hhit_Y[train_Y_mask==1]), train_hhit_Y[train_Y_mask==1])}')
print(f'train acc : {accuracy(train_pred_bet[train_Y_mask==1], train_hhit_Y[train_Y_mask==1])}')
print(f'valid base acc : {accuracy(np.zeros_like(valid_hhit_Y[valid_Y_mask==1]), valid_hhit_Y[valid_Y_mask==1])}')
print(f'valid acc : {accuracy(valid_pred_bet[valid_Y_mask==1], valid_hhit_Y[valid_Y_mask==1])}')
print(f'test base acc : {accuracy(np.zeros_like(test_hhit_Y[test_Y_mask==1]), test_hhit_Y[test_Y_mask==1])}')
print(f'test acc : {accuracy(test_pred_bet[test_Y_mask==1], test_hhit_Y[test_Y_mask==1])}')train base acc : 0.7884759168896585
train acc : 0.8007535809853612
valid base acc : 0.7851734223322747
valid acc : 0.7902154994527283
test base acc : 0.7834619806207916
test acc : 0.790096896042043これは単体で予測したときよりも0.1%悪いです。
順位の予測
順位を予測した出力分布を見てみます。
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(131)
plt.scatter(train_rrank_pred[train_Y_mask==1], train_rrank_Y[train_Y_mask==1])
plt.title('train')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(132)
plt.scatter(valid_rrank_pred[valid_Y_mask==1], valid_rrank_Y[valid_Y_mask==1])
plt.title('valid')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(133)
plt.scatter(test_rrank_pred[test_Y_mask==1], test_rrank_Y[test_Y_mask==1])
plt.title('test')
plt.xlabel('pred')
plt.ylabel('y')
んーほぼかわらない!
タイムの予測
タイムを予測した出力分布を見てみます。
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(131)
plt.scatter(train_timesec_pred[train_Y_mask==1], train_timesec_Y[train_Y_mask==1])
plt.title('train')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(132)
plt.scatter(valid_timesec_pred[valid_Y_mask==1], valid_timesec_Y[valid_Y_mask==1])
plt.title('valid')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(133)
plt.scatter(test_timesec_pred[test_Y_mask==1], test_timesec_Y[test_Y_mask==1])
plt.title('test')
plt.xlabel('pred')
plt.ylabel('y')
これもかわらないです。
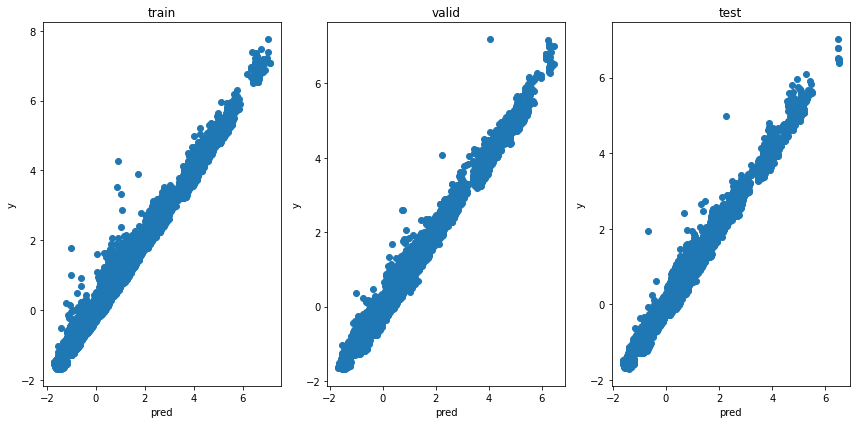
オッズの予測
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(131)
plt.scatter(train_oddslog_pred[train_Y_mask==1], train_oddslog_Y[train_Y_mask==1])
plt.title('train')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(132)
plt.scatter(valid_oddslog_pred[valid_Y_mask==1], valid_oddslog_Y[valid_Y_mask==1])
plt.title('valid')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(133)
plt.scatter(test_oddslog_pred[test_Y_mask==1], test_oddslog_Y[test_Y_mask==1])
plt.title('test')
plt.xlabel('pred')
plt.ylabel('y')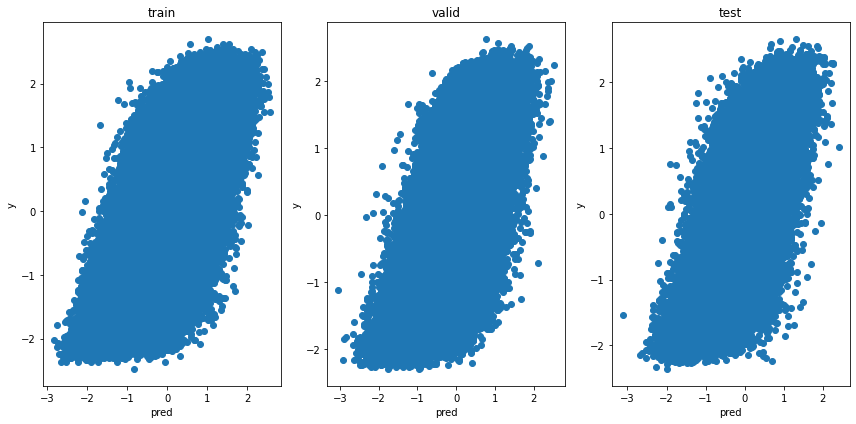
これもかわりません
利益の解析
次は利益を計算してみます。
1位の予測
利益はでませんでした。
target_col_keyward = 'tansyo_payout'
Y_columns = [f'horse_{n}_{target_col_keyward}' for n in range(1, 19)]
train_payout_Y = not_use_df.loc[not_use_df['race_date'] < '2018-01-01', Y_columns].reset_index(drop=True)
valid_payout_Y = not_use_df.loc[('2018-01-01' <= not_use_df['race_date']) & (not_use_df['race_date'] < '2022-01-01'), Y_columns].reset_index(drop=True)
test_payout_Y = not_use_df.loc['2022-01-01' <= not_use_df['race_date'], Y_columns].reset_index(drop=True)
train_payout_Y = train_payout_Y.to_numpy().astype(np.float32)
valid_payout_Y = valid_payout_Y.to_numpy().astype(np.float32)
test_payout_Y = test_payout_Y.to_numpy().astype(np.float32)
th = 0.5
train_win = np.sum(train_pred_bet[train_Y_mask==1] * train_payout_Y[train_Y_mask==1] - 1.0)
valid_win = np.sum(valid_pred_bet[valid_Y_mask==1] * valid_payout_Y[valid_Y_mask==1] - 1.0)
test_win = np.sum(test_pred_bet[test_Y_mask==1] * test_payout_Y[test_Y_mask==1] - 1.0)
print(f'train win : {train_win}')
print(f'valid win : {valid_win}')
print(f'test win : {test_win}')train win : -507771.8000000715
valid win : -111331.4000005722
test win : -60819.999999880793位以内の予想
利益はでませんでした。
target_col_keyward = 'hukusyo_payout'
Y_columns = [f'horse_{n}_{target_col_keyward}' for n in range(1, 19)]
train_payout_Y = not_use_df.loc[not_use_df['race_date'] < '2018-01-01', Y_columns].reset_index(drop=True)
valid_payout_Y = not_use_df.loc[('2018-01-01' <= not_use_df['race_date']) & (not_use_df['race_date'] < '2022-01-01'), Y_columns].reset_index(drop=True)
test_payout_Y = not_use_df.loc['2022-01-01' <= not_use_df['race_date'], Y_columns].reset_index(drop=True)
train_payout_Y = train_payout_Y.to_numpy().astype(np.float32)
valid_payout_Y = valid_payout_Y.to_numpy().astype(np.float32)
test_payout_Y = test_payout_Y.to_numpy().astype(np.float32)
th = 0.5
train_win = np.sum(train_pred_bet[train_Y_mask==1] * train_payout_Y[train_Y_mask==1] - 1.0)
valid_win = np.sum(valid_pred_bet[valid_Y_mask==1] * valid_payout_Y[valid_Y_mask==1] - 1.0)
test_win = np.sum(test_pred_bet[test_Y_mask==1] * test_payout_Y[test_Y_mask==1] - 1.0)
print(f'train win : {train_win}')
print(f'valid win : {valid_win}')
print(f'test win : {test_win}')train win : -481400.13991916925
valid win : -105692.56998400576
test win : -57660.25998886675順位の予測
利益はでませんでした。
target_col_keyward = 'tansyo_payout'
Y_columns = [f'horse_{n}_{target_col_keyward}' for n in range(1, 19)]
train_payout_Y = not_use_df.loc[not_use_df['race_date'] < '2018-01-01', Y_columns].reset_index(drop=True)
valid_payout_Y = not_use_df.loc[('2018-01-01' <= not_use_df['race_date']) & (not_use_df['race_date'] < '2022-01-01'), Y_columns].reset_index(drop=True)
test_payout_Y = not_use_df.loc['2022-01-01' <= not_use_df['race_date'], Y_columns].reset_index(drop=True)
train_payout_Y = train_payout_Y.to_numpy().astype(np.float32)
valid_payout_Y = valid_payout_Y.to_numpy().astype(np.float32)
test_payout_Y = test_payout_Y.to_numpy().astype(np.float32)
def calc_win_money(pred, hit, payout, th):
bet = (pred < th).astype(int)
return_money = np.sum(bet * hit * payout)
bet_money = np.sum(bet)
win_money = return_money - bet_money
return win_money
print(f'train win money :{calc_win_money(train_rrank_pred[train_Y_mask==1], train_thit_Y[train_Y_mask==1], train_payout_Y[train_Y_mask==1], 0.1)}')
print(f'valid win money :{calc_win_money(valid_rrank_pred[valid_Y_mask==1], valid_thit_Y[valid_Y_mask==1], valid_payout_Y[valid_Y_mask==1], 0.1)}')
print(f'test win money :{calc_win_money(test_rrank_pred[test_Y_mask==1], test_thit_Y[test_Y_mask==1], test_payout_Y[test_Y_mask==1], 0.1)}')train win money :-36.60000002384186
valid win money :-76.7000002861023
test win money :-45.90000057220459タイムの予想
利益はでませんでした。
target_col_keyward = 'tansyo_payout'
Y_columns = [f'horse_{n}_{target_col_keyward}' for n in range(1, 19)]
train_payout_Y = not_use_df.loc[not_use_df['race_date'] < '2018-01-01', Y_columns].reset_index(drop=True)
valid_payout_Y = not_use_df.loc[('2018-01-01' <= not_use_df['race_date']) & (not_use_df['race_date'] < '2022-01-01'), Y_columns].reset_index(drop=True)
test_payout_Y = not_use_df.loc['2022-01-01' <= not_use_df['race_date'], Y_columns].reset_index(drop=True)
train_payout_Y = train_payout_Y.to_numpy().astype(np.float32)
valid_payout_Y = valid_payout_Y.to_numpy().astype(np.float32)
test_payout_Y = test_payout_Y.to_numpy().astype(np.float32)
def calc_win_money(pred_Y, hit, payout, Y_mask):
Y_mask = Y_mask == 1
win_money = 0
for i in range(pred_Y.shape[0]):
mask = Y_mask[i, :]
race_pred_Y = pred_Y[i, mask]
race_hit = hit[i, mask]
race_payout = payout[i, mask]
n = np.argmin(race_pred_Y)
win_money += race_hit[n] * race_payout[n] - 1.0
return win_money
print(f'train win money :{calc_win_money(train_timesec_pred, train_thit_Y, train_payout_Y, train_Y_mask)}')
print(f'valid win money :{calc_win_money(valid_timesec_pred, valid_thit_Y, valid_payout_Y, valid_Y_mask)}')
print(f'test win money :{calc_win_money(test_timesec_pred, test_thit_Y, test_payout_Y, test_Y_mask)}')train win money :-3194.000029563904
valid win money :-1873.900005698204
test win money :-1041.4999984502792オッズの予測
利益はでませんでした。
target_col_keyward = 'tansyo_payout'
Y_columns = [f'horse_{n}_{target_col_keyward}' for n in range(1, 19)]
train_payout_Y = not_use_df.loc[not_use_df['race_date'] < '2018-01-01', Y_columns].reset_index(drop=True)
valid_payout_Y = not_use_df.loc[('2018-01-01' <= not_use_df['race_date']) & (not_use_df['race_date'] < '2022-01-01'), Y_columns].reset_index(drop=True)
test_payout_Y = not_use_df.loc['2022-01-01' <= not_use_df['race_date'], Y_columns].reset_index(drop=True)
train_payout_Y = train_payout_Y.to_numpy().astype(np.float32)
valid_payout_Y = valid_payout_Y.to_numpy().astype(np.float32)
test_payout_Y = test_payout_Y.to_numpy().astype(np.float32)
def calc_win_money(pred, hit, payout, Y, th):
bet = (pred > (Y + th)).astype(int)
return_money = np.sum(bet * hit * payout)
bet_money = np.sum(bet)
win_money = return_money - bet_money
return win_money
print(f'train win money :{calc_win_money(train_oddslog_pred[train_Y_mask==1], train_thit_Y[train_Y_mask==1], train_payout_Y[train_Y_mask==1], train_oddslog_Y[train_Y_mask==1], 0.1)}')
print(f'valid win money :{calc_win_money(valid_oddslog_pred[valid_Y_mask==1], valid_thit_Y[valid_Y_mask==1], valid_payout_Y[valid_Y_mask==1], valid_oddslog_Y[valid_Y_mask==1], 0.1)}')
print(f'test win money :{calc_win_money(test_oddslog_pred[test_Y_mask==1], test_thit_Y[test_Y_mask==1], test_payout_Y[test_Y_mask==1], test_oddslog_Y[test_Y_mask==1], 0.1)}')train win money :-57329.900017380714
valid win money :-10074.199993491173
test win money :-6479.100013375282総評
結局のところ、単体で予測した場合と比較してみても、明確な精度向上はみられませんでした。
ただ逆を言えば、複数の目的変数を同時に予測しても精度は下がらないということでもあります。
