
まえがき
以前、GodotでもLLMを使う方法について話しました。

しかし、上記の方法にはいくつかの課題点がありました。具体的には
- LLM実行が終わるまで、ゲームが停止する
- フリーズに近い状態なので、ゲームとして成り立たなくなる
- LLMの吐き出す文字数が多いと、返答まで待つことになる
- ローカルLLMをGPUで実行しても2、3秒待つので、ユーザー体験が損なわれる
1つ目の課題点は、threadやos.create_processなどを使うことで解決できます。しかし、別プロセスとして実行すると、ノードが持つオブジェクトにはアクセスできなくなるので、実装は面倒になります。
2つ目の課題点は、Godot 4.3で実装予定のOS.execute_with_pipe()で解決できるかもしれません。しかし、自分で動かしてみたのですが、資料が少なく、期待通りの実装はできませんでした。
そこで、今回は別の方法を利用して、この2つの課題を解決しようと思います。
追記
C#をGDScriptと併用してGodotで使うことで、簡単にLLMを逐次表示できました。別プロセスで実行するよりはこちらのほうがいいかも

解決策
GodotでのLLMの実行は現時点では、別の実行ファイルに頼る形式が最も実装が楽です。
前の記事ではllama.cppを使うことを推奨し、その後、llamafileを使うことを推奨しました。
そして、llamafile(llama.cpp)には、サーバーモードが実装されているのです。
そこで今回は、godotでサーバーモードのllamafileを実行し、http通信によって返答を逐次受け取りながらgodotに表示する方法を取りたいと思います。
ディレクトリ
ディレクトリ構成は次のようになっています。godot側ではllm_connectというシーンを追加して、スクリプトをアタッチするだけです。
godot_llamafile_stream_test
│ llm_connect.gd
│ llm_connect.tscn
│ project.godot
└─models
└─ Phi-3-mini-4k-instruct.Q4_K_M.llamafile.exeまた、Phi-3-miniのllamafileをmodelsというディレクトリを作って、入れておきます。phi-3-miniのllamafileは以下からダウンロードできます。windows環境下では、拡張子に.exeを付け足してください。

※お好きなモデルのllamafileをダウンロードしてもらって構いません。
シーン構成
llm_connectのノードは次のような構成になっています。
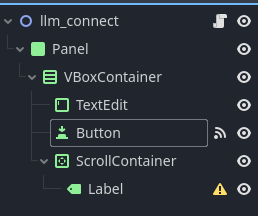
UIの位置調整等は適当に配置してもらって構いません。例を上げときます。TextEditのtextにデフォルトで「What is best movie?」と入れていますが、テスト用なので入れなくて構いません。
Buttonのpressedシグナルはスクリプトにアタッチしてください。
プログラム
llm_connectにアタッチしたllm_connect.gdを編集します。以下、全文です。
extends Node2D
var llm_pid: int
signal recived_tokens
var http_client := HTTPClient.new()
var http_is_connected := false
var http_is_requested := false
var port := 8080
var host := 'http://127.0.0.1'
var url := '/completion'
var header := 'Content-Type: application/json'
var output_text := ''
var n_predict := 512
func _ready() -> void:
tree_exited.connect(_exit_tree)
var arguments := [
'-ngl', '9999', '--host', '0.0.0.0', '--server', '--nobrowser'
]
llm_pid = OS.create_process('models/Phi-3-mini-4k-instruct.Q4_K_M.llamafile.exe', arguments)
recived_tokens.connect(_on_recived_tokens)
func _on_button_pressed() -> void:
connect_llm()
func _on_recived_tokens(tokens: Array):
for token in tokens:
output_text += token
$Panel/VBoxContainer/ScrollContainer/Label.text = output_text
func connect_llm():
$Panel/VBoxContainer/Button.disabled = true
output_text = ''
print('call connect_llm')
var err := http_client.connect_to_host(host, port)
print(' err :', err)
if err == OK:
http_is_connected = true
else:
http_is_connected = false
func close_connect():
$Panel/VBoxContainer/Button.disabled = false
http_client.close()
http_is_connected = false
http_is_requested = false
func request_llm(http_client_status):
print('call request_llm')
print(' http_client_status :',http_client_status)
if http_client_status == HTTPClient.STATUS_CONNECTING or http_client_status == HTTPClient.STATUS_RESOLVING:
return
if http_client_status == HTTPClient.STATUS_CONNECTED:
var body = get_send_body()
var err = http_client.request(HTTPClient.METHOD_POST, url, [header], body)
print(' err :', err)
if err == OK:
http_is_requested = true
func _process(delta):
if http_is_connected == false:
return
http_client.poll()
var http_client_status = http_client.get_status()
if http_is_requested == false:
request_llm(http_client_status)
return
if http_client.has_response() and http_client_status == HTTPClient.STATUS_BODY:
http_client.poll()
var chunk := http_client.read_response_body_chunk()
if chunk.size() == 0:
return
var string_body := chunk.get_string_from_utf8()
if string_body :
var tokens = to_token(string_body)
emit_signal('recived_tokens', tokens)
func get_send_body():
var input_text :String = $Panel/VBoxContainer/TextEdit.text
var prompt := "<|user|>\n{0}<|end|>\n<|assistant|>\n".format([input_text])
var body = {
'prompt':prompt,
'n_predict':n_predict,
'stream':true
}
return JSON.stringify(body)
func to_token(string_body: String):
#print('call to_token')
var ret = []
var data_list = string_body.strip_edges().split('\n\n')
for data in data_list:
var dict_data = JSON.parse_string(data.replace('data: ', ''))
if dict_data != null:
if dict_data.has('content'):
ret.append(dict_data['content'])
if dict_data.has('stop') and dict_data['stop']:
close_connect()
return ret
func _exit_tree():
if http_client:
http_client.close()
OS.kill(llm_pid)
プログラム解説
プログラムの解説を軽くしておきます。流れとしては、
- サーバーの起動
- サーバー接続(Buttonクリック時)
- サーバーへのリクエスト
- responseの逐次受け取り
- 更新シグナルの送受信
- 接続終了
となっています。ChatGPTのapiで同じようなことをする話は、Web上にあると思いますので、そこら辺を参考にしながら実装しました。
サーバーの起動
サーバーの起動はOS.create_processで実行しました。引数についてですが、-nglはGPUの仕様割合をきめるパラメータ(9999でGPU最大限使用)で、–nobrowserはWeb UIを立ち上げないことを表しています。
また、pidを保存しておき、プログラム終了時に、サーバーを終了するようにします。
func _ready() -> void:
tree_exited.connect(_exit_tree)
var arguments := [
'-ngl', '9999', '--host', '0.0.0.0', '--server', '--nobrowser'
]
llm_pid = OS.create_process('models/Phi-3-mini-4k-instruct.Q4_K_M.llamafile.exe', arguments)
...
func _exit_tree():
if http_client:
http_client.close()
OS.kill(llm_pid)
サーバー接続
Buttonが押されたら、connect_llmを呼び出します。呼び出されたら、HTTPClinetによってサーバーへの接続を確立します。接続が確立できたら、http_is_connectedがtrueになります。
また、LLMから返答が返ってくるまで、Buttonをdisableにして、送信できないようにします。
func _on_button_pressed() -> void:
connect_llm()
func connect_llm():
$Panel/VBoxContainer/Button.disabled = true
output_text = ''
print('call connect_llm')
var err := http_client.connect_to_host(host, port)
print(' err :', err)
if err == OK:
http_is_connected = true
else:
http_is_connected = falseサーバーへのリクエスト
サーバーへ接続済みかつ、リクエストを送っていない場合は、_processにてサーバーにリクエストを送ります。
リクエストとして、TextEditのtextフィールドをpromptとして書き起こして、json形式でサーバーへ送ります。promptは用途によって書き換えてもらっていいです。
リクエストを送ると、http_is_requestedがtrueになります。
func _process(delta):
if http_is_connected == false:
return
http_client.poll()
var http_client_status = http_client.get_status()
if http_is_requested == false:
request_llm(http_client_status)
return
func request_llm(http_client_status):
print('call request_llm')
print(' http_client_status :',http_client_status)
if http_client_status == HTTPClient.STATUS_CONNECTING or http_client_status == HTTPClient.STATUS_RESOLVING:
return
if http_client_status == HTTPClient.STATUS_CONNECTED:
var body = get_send_body()
var err = http_client.request(HTTPClient.METHOD_POST, url, [header], body)
print(' err :', err)
if err == OK:
http_is_requested = true
func get_send_body():
var input_text :String = $Panel/VBoxContainer/TextEdit.text
var prompt := "<|user|>\n{0}<|end|>\n<|assistant|>\n".format([input_text])
var body = {
'prompt':prompt,
'n_predict':n_predict,
'stream':true
}
return JSON.stringify(body)responseの逐次受け取り
サーバーへリクエストを送っていた場合は、_processにてresponseを逐次受け取ります。
chunkで受け取って、それをutf8の文字列に変換します。
変換された文字列(json)から、LLMの逐次回答(tokens)を抜き出して、recived_tokensシグナルへと渡します。
func _process(delta):
...
if http_client.has_response() and http_client_status == HTTPClient.STATUS_BODY:
http_client.poll()
var chunk := http_client.read_response_body_chunk()
if chunk.size() == 0:
return
var string_body := chunk.get_string_from_utf8()
if string_body :
var tokens = to_token(string_body)
emit_signal('recived_tokens', tokens)
func to_token(string_body: String):
#print('call to_token')
var ret = []
var data_list = string_body.strip_edges().split('\n\n')
for data in data_list:
var dict_data = JSON.parse_string(data.replace('data: ', ''))
if dict_data != null:
if dict_data.has('content'):
ret.append(dict_data['content'])
if dict_data.has('stop') and dict_data['stop']:
close_connect()
return ret更新シグナルの送受信
_process中の
emit_signal('recived_tokens', tokens)にて、recived_tokensシグナルへ逐次受け取ったtokensを渡します。
そして、recived_tokensシグナルは、_readyにて_on_recived_tokens関数へと繋げます。
func _ready() -> void:
...
recived_tokens.connect(_on_recived_tokens)
func _on_recived_tokens(tokens: Array):
for token in tokens:
output_text += token
$Panel/VBoxContainer/ScrollContainer/Label.text = output_text_on_recived_tokensでは、受け取ったtokenをoutput_textへとつかして、それをLabelのtextフィールドへセットします。これで、ノードのLabelのtextへ、LLMから受け取ったトークンが逐次表示されます。
接続終了
トークンを逐次受け取る際に、dict_dataのstopがtrueになった場合は、LLMの出力が止まったことを意味します。その場合は、httpの接続を切ります。
送信ボタンのdisabledを解除し、http_is_connectedとhttp_is_requestedをfalseに直します。
func to_token(string_body: String):
#print('call to_token')
var ret = []
var data_list = string_body.strip_edges().split('\n\n')
for data in data_list:
var dict_data = JSON.parse_string(data.replace('data: ', ''))
if dict_data != null:
if dict_data.has('content'):
ret.append(dict_data['content'])
if dict_data.has('stop') and dict_data['stop']:
close_connect()
return ret
func close_connect():
$Panel/VBoxContainer/Button.disabled = false
http_client.close()
http_is_connected = false
http_is_requested = false実行
実行します。llamafileのサーバーを実行するのにネットワークの接続に許可を求められるかもしれません。
※llamafileサーバーの起動まで数秒かかるときがあります。その場合は、数秒待ってから、sendを押してください
※「プロジェクトの実行を停止(F8)」ボタンでゲームを停止すると、別プロセスで起動したサーバーが終了されません。そうすると、次回実行時に正常にLLMとのHTTP通信ができなくなります。ゲームのウィンドウのバツボタン、もしくはタスクバーのウィンドウを終了して、ゲームを閉じてください。もしも、サーバープロセスが残ってしまった場合は、タスクマネージャーで終了してください。
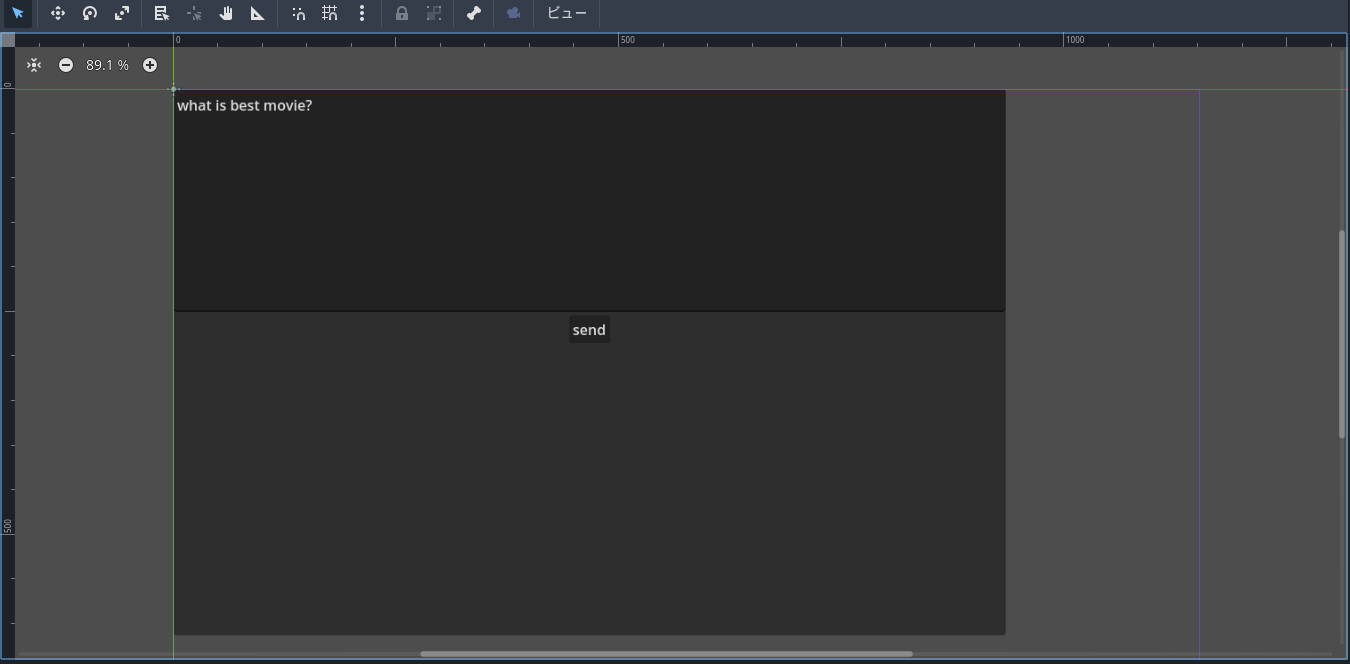
phi-3-miniは日本語も出力できるので、試してみます。
いい感じですね!
まとめ
Godotでローカルで逐次表示できるLLM環境を作りました。
いい感じに表示できるようになったと思います。これを利用すれば、ゲーム作成の幅が結構広がる気がします。
※追記 : エラー処理が甘いので、使うときは適切に編集することを推奨します

