
はじめに
最近、統計局のデータを利用する機会がありました。

あまりアクセスする機会が少ないページで、私の最後にアクセスした記憶は学生時代の何かの授業だった気がします。
相変わらず、使いにくいページだな…と思っていると、API経由で統計データをダウンロードできるではありませんか(当時もできたのかもしれません)。
この記事では、API経由で統計局のデータをダウンロードしてみて、解析してみようと思います。
e-StatのAPIの利用
APIの利用は、ユーザー登録すればOK(Googleアカウントで登録可)

登録したら、マイページ→API機能(アプリケーションID発行)と進みます。
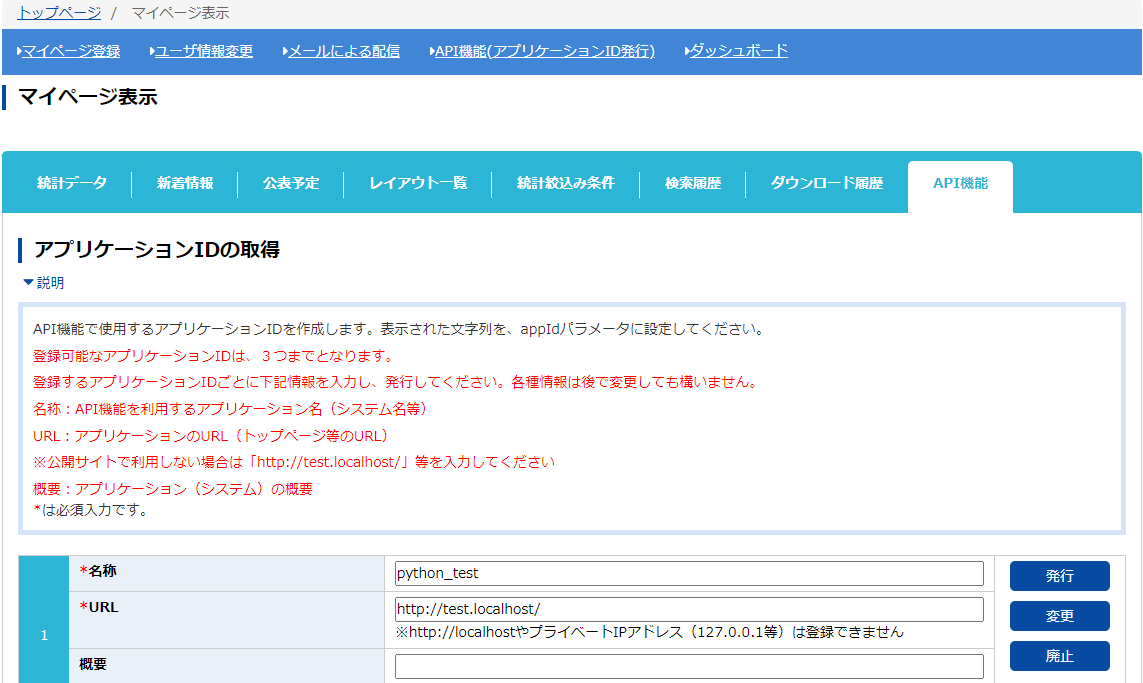
3つまでアプリケーションIDが発行できるようで、名称とURLを入力し、発行ボタンを押します。
URLは公開サイトで利用するわけではないので、http://test.localhost/としました。
発行すると、概要の下にあるappIdが表示されます。これをapiをリクエストする際に使うことで、当家データを引っ張ってこれます。
実行環境
apiを叩くだけなので、実行環境はネットが繋がっていれば大丈夫です。今回はpythonで可視化しようと思うので、pythonのデータ解析環境を用意しました。
Dev Containerが好きなので、よく使うDev container環境を用意しましたが、下記のrequirements.txtのライブラリが入っていれば動きます。
また、バージョンを依存も無いので、pipでnumpy、pandas、requests、matplotlib、seabornあたりが入っていれば大丈夫だと思います。
以下プロジェクトのディレクトリ構成です。
e_stats_analysis
├── .devcontainer
│ ├── Dockerfile
│ ├── devcontainer.json
│ ├── requirements.txt
│ └── docker-compose.yml
....devcontainer以下のファイルを作成して、コンテナをビルドしてください
Dockerfile
ベースはpython:3.10-slim-bullseyeにしました。自分がよく使うテンプレをそのまま使いました。
FROM python:3.10-slim-bullseye
ARG USERNAME=vscode
ARG USER_UID=1000
ARG USER_GID=$USER_UID
ENV LANG ja_JP.UTF-8
ENV LANGUAGE ja_JP:ja
ENV LC_ALL ja_JP.UTF-8
ENV TZ JST-9
ENV TERM xterm
RUN apt-get update \
&& groupadd --gid $USER_GID $USERNAME \
&& useradd -s /bin/bash --uid $USER_UID --gid $USER_GID -m $USERNAME \
&& apt-get install -y sudo \
&& echo $USERNAME ALL=\(root\) NOPASSWD:ALL > /etc/sudoers.d/$USERNAME \
&& chmod 0440 /etc/sudoers.d/$USERNAME \
&& apt-get -y install locales \
&& localedef -f UTF-8 -i ja_JP ja_JP.UTF-8
RUN apt-get -y install git
RUN pip install --upgrade pip
RUN pip install --upgrade setuptools
COPY ./requirements.txt .
RUN pip install -r requirements.txtdevcontainer.json
名前とサービス名を設定してください。拡張機能は好きなものを入れてください。python、jupyter、rainbor-csvあたりを入れておくと、データ分析の最低限はやりやすいです。
{
"name": "e_stat_analysis",
"service": "e_stat_analysis",
"dockerComposeFile": "docker-compose.yml",
"remoteUser": "vscode",
"workspaceFolder": "/work",
"customizations": {
"vscode": {
"extensions": [
"ms-python.python",
"ms-toolsai.jupyter",
"mechatroner.rainbow-csv"
]
}
}
}requirements.txt
pythonにいれるライブラリ・モジュールを書きます。絶対こんなに使いませんが、とりあえず、今後使うかもしれない奴らを書きました。バージョン指定とかあれば、自分で指定してください。
また、japanize_matplotlibは入れないと日本語が文字化けします
requests
numpy
pandas
matplotlib
bs4
scikit-learn
optuna
lightgbm
tqdm
timeout-decorator
requests-html
seaborn
pyarrow
schedule
japanize_matplotlibdocker-compose.yml
サービス名を先ほど設定したものと同一にしてください。
version: '3'
services:
e_stat_analysis:
container_name: 'e_stat_analysis_container'
hostname: 'e_stat_analysis_container'
build: .
restart: always
working_dir: '/work'
tty: true
volumes:
- type: bind
source: ..
target: /work
とりあえずデータを取ってみる
とりあえずデータを取得してみて、どんなもんか見てみます。
APIの仕様はここにかいてありました。記事作成時点でのAPIバージョンは3.0でした。
またJPy-DataReaderというpythonのe-stat apiのラッパーも公開されていますが、開発は二年前に止まっているので、今回は自分でやってみます(APIバージョン 3.0対応なので使えるとは思います)。
では、適当なjupyter notebook(test.ipynb)を作って、実行しながら見ていきます。
まず、requestなどをimportして、e-statのappidを定義します
import requests
import pandas as pd
import io
api_appid = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx'次に、URLを作成して、リクエストする関数を用意します。パラメータを&で繋げて結合するだけですね。
e-statのAPIはXMLやJSON、CSVなどで返してくれます。今回は表に直しやすいCSVで返してもらいます。詳しくは仕様を見てください。
base_url = 'https://api.e-stat.go.jp/rest/3.0/app/getSimpleStatsData?'
def get_data(params: dict) -> dict:
url = base_url + '&'.join([f'{key}={value}' for key, value in params.items()])
print(url)
return requests.get(url).json()では、試しに人口推計のデータを取ってきます。
まず、e-Statのページから対象となるDBのページまでたどり着きます(ここが一番面倒)
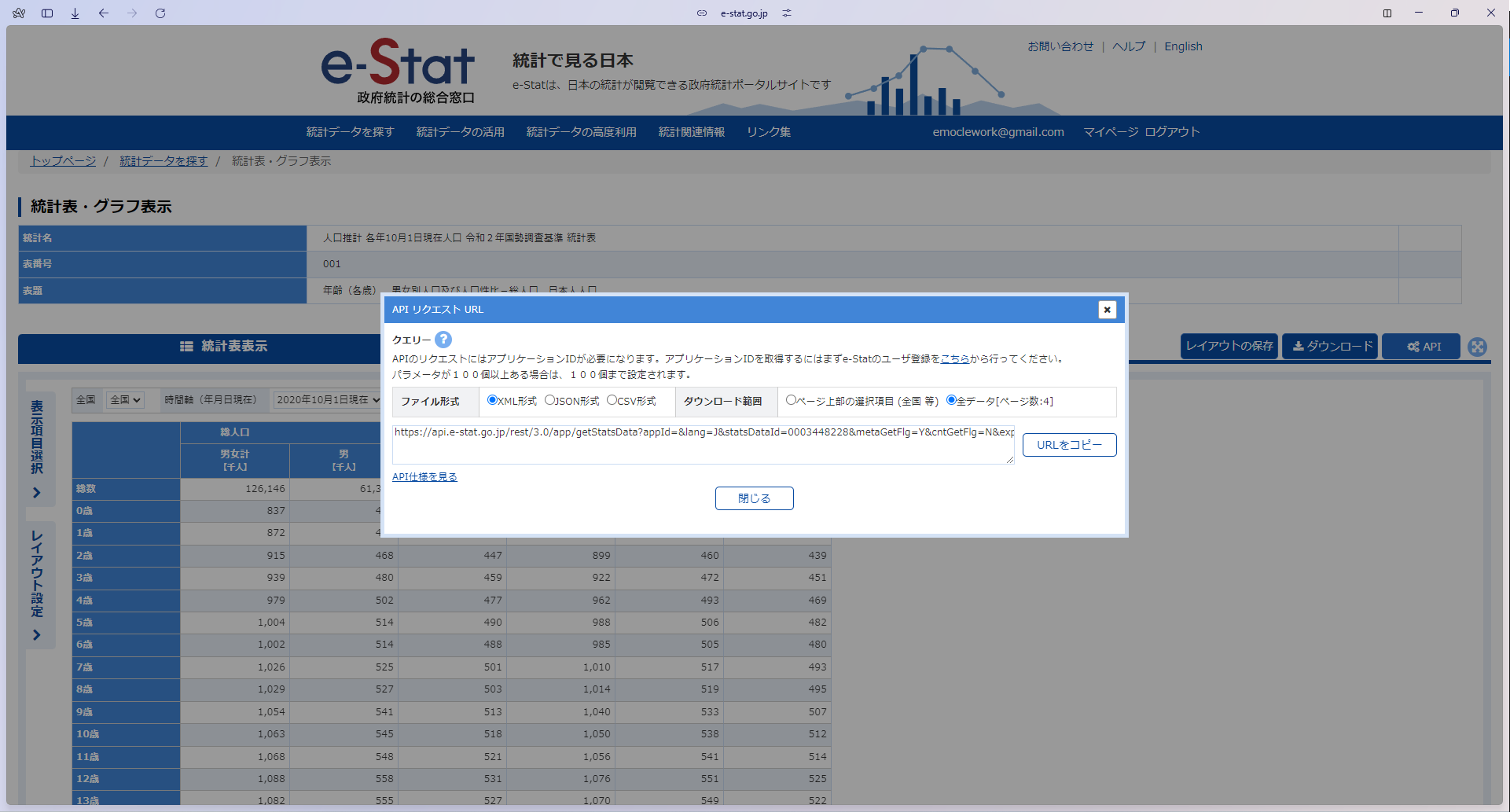
次に、APIボタンを押して(なければDB→API)、リクエストURLを確認します。ここで確認したいのは、対象となるDBの固有ID(statsDataId)です。
これを確認したら、pythonでこのURLを生成できるようにコードを書きます。もちろん、直接このURLをリクエストしても問題ありません。
params = {
'appId':api_appid,
'lang':'J',
'statsDataId':'0003448228',
}
data = get_data(params)
print(data)実行すると、CSV形式になったデータが返ってきます。
https://api.e-stat.go.jp/rest/3.0/app/getSimpleStatsData?appId=3206490c39669d49fe6caa8e08d76162c83e0612&lang=J&statsDataId=0003448228
"RESULT"
"STATUS","0"
"ERROR_MSG","正常に終了しました。"
"DATE","2024-06-24T01:31:28.950+09:00"
"RESULT_INF"
"TOTAL_NUMBER","3060"
"FROM_NUMBER","1"
"TO_NUMBER","3060"
"TABLE_INF","0003448228"
"STAT_NAME","00200524","人口推計"
"GOV_ORG","00200","総務省"
"STATISTICS_NAME","人口推計 各年10月1日現在人口 令和2年国勢調査基準 統計表"
"TITLE","001","年齢(各歳),男女別人口及び人口性比-総人口,日本人人口"
"CYCLE","年次"
"SURVEY_DATE","0"
"OPEN_DATE","2024-04-12"
"SMALL_AREA","0"
"COLLECT_AREA","該当なし"
"MAIN_CATEGORY","02","人口・世帯"
"SUB_CATEGORY","01","人口"
"OVERALL_TOTAL_NUMBER","2244"
"UPDATED_DATE","2024-04-12"
"STATISTICS_NAME_SPEC","人口推計","各年10月1日現在人口","令和2年国勢調査基準","統計表","",""
"TITLE_SPEC","","年齢(各歳),男女別人口及び人口性比-総人口,日本人人口","","","",""
"NOTE","***","該当数値がないもの"
"NOTE","-","該当数値がないもの "
"VALUE"
"cat01_code","男女別・性比","cat02_code","人口","cat03_code","年齢各歳","area_code","全国","time_code","時間軸(年月日現在)","unit","value","annotation"
"001","男女計","001","総人口","01000","総数","00000","全国","1601","2020年10月1日現在","千人","126146",""
"001","男女計","001","総人口","01000","総数","00000","全国","1301","2021年10月1日現在","千人","125502",""
"001","男女計","001","総人口","01000","総数","00000","全国","1701","2022年10月1日現在","千人","124947",""
"001","男女計","001","総人口","01000","総数","00000","全国","1801","2023年10月1日現在","千人","124352",""
...このCSVデータには、統計の表以外のデータも含まれているので、それを消して、統計データの表だけを抽出します。
ぱっと見た感じでは、”VALUE”から表データが始まるようなので、それ以前を切り捨ててpandasへ与えます。
s = data.text.find('"VALUE"') + len('"Value"\n')
f = io.StringIO(data.content.decode('utf-8')[s:])
df = pd.read_csv(f)
dfちゃんと、pandasのDataFrameとして読み込めました。
cat01_code 男女別・性比 cat02_code 人口 cat03_code 年齢各歳 area_code 全国 time_code 時間軸(年月日現在) unit value annotation
0 1 男女計 1 総人口 1000 総数 0 全国 1601 2020年10月1日現在 千人 126146.0 NaN
1 1 男女計 1 総人口 1000 総数 0 全国 1301 2021年10月1日現在 千人 125502.0 NaN
2 1 男女計 1 総人口 1000 総数 0 全国 1701 2022年10月1日現在 千人 124947.0 NaN
3 1 男女計 1 総人口 1000 総数 0 全国 1801 2023年10月1日現在 千人 124352.0 NaN
4 1 男女計 1 総人口 1001 0歳 0 全国 1601 2020年10月1日現在 千人 837.0 NaN
... ... ... ... ... ... ... ... ... ... ... ... ... ...
3055 4 人口性比 2 日本人人口 1100 99歳 0 全国 1701 2022年10月1日現在 女性=100 16.7 NaN
3056 4 人口性比 2 日本人人口 1100 99歳 0 全国 1801 2023年10月1日現在 女性=100 17.8 NaN
3057 4 人口性比 2 日本人人口 1101 100歳以上 0 全国 1301 2021年10月1日現在 女性=100 13.7 NaN
3058 4 人口性比 2 日本人人口 1101 100歳以上 0 全国 1701 2022年10月1日現在 女性=100 13.6 NaN
3059 4 人口性比 2 日本人人口 1101 100歳以上 0 全国 1801 2023年10月1日現在 女性=100 13.8 NaN
3060 rows × 13 columnscat01_codeが男女、男性、女性、人口比の4つで、cat02_codeは総人口or日本人人口ですね。
全国のみのデータなので、area_codeや全国は一つのカテゴリしかありません。
この表データをグラフにしてみます。
import seaborn as sns
import japanize_matplotlib
plot_data = df.query('cat02_code == 1 and 年齢各歳 != "総数"')
plot_data.loc[:, 'year'] = pd.to_datetime(plot_data['時間軸(年月日現在)'], format='%Y年%m月%d日現在').dt.year
plot_data.loc[:, 'age'] = plot_data['年齢各歳'].str.extract(r'(\d+)').astype(int)
ax = sns.barplot(plot_data.query('year == 2023 and cat01_code == 1'), x='value', y='age', native_scale=True, errorbar=None, orient='h')
ax.set_xlabel('千人')
ax.set_ylabel('年\n齢', labelpad=15, rotation=0)
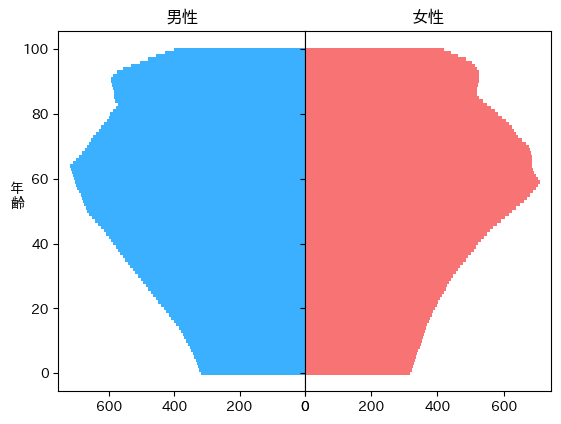
ax.set_title('人口と年齢')2023年の男女の年齢別の人数をグラフにしました。思ってた感じの人口ピラミッドが、e-statから取得できました。
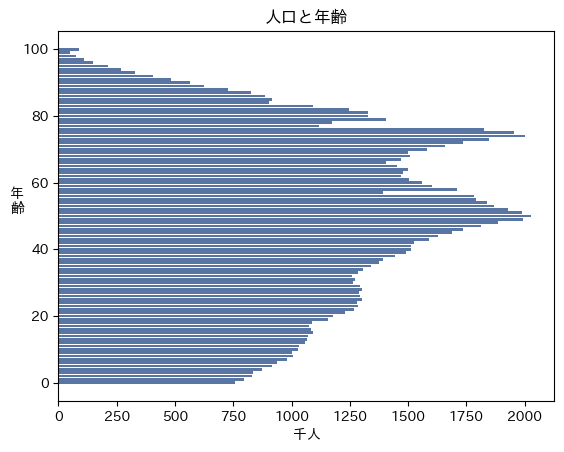
人口ピラミッド的には、男性と女性を分けたグラフのほうが見慣れているので、修正します。
import matplotlib.pyplot as plt
plot_data = df.query('cat02_code == 1 and 年齢各歳 != "総数"')
plot_data.loc[:, 'year'] = pd.to_datetime(plot_data['時間軸(年月日現在)'], format='%Y年%m月%d日現在').dt.year
plot_data.loc[:, 'age'] = plot_data['年齢各歳'].str.extract(r'(\d+)').astype(int)
fig, axes = plt.subplots(ncols=2, sharey=True)
man = plot_data.query('year == 2023 and cat01_code == 2').reset_index()
axes[0].barh(man['age'], man['value'], align='center', color='#3AB0FF', height=1)
axes[0].invert_xaxis()
axes[0].set_title('男性')
woman = plot_data.query('year == 2023 and cat01_code == 3')
axes[1].barh(woman['age'], woman['value'], align='center', color='#F87474', height=1)
axes[1].set_title('女性')
plt.subplots_adjust(wspace=0, top=0.85, bottom=0.1, left=0.18, right=0.95)
axes[0].set_ylabel('年\n齢', rotation=0)見慣れた人口ピラミッドがでました。日本の人口は性別で大きく変わらないので、二方向に分けるメリットはあまりないようなき気がします。
分析・予測してみる
未来の人口ピラミッドを推測してみます。先程のipynbの続きです。
まず、データをe-StatのAPIから持ってきます。このとき、各表は国勢調査によってまとめられているため、国勢調査ごとの表データが必要になります。
def get_df(statsDataId):
params = {
'appId':api_appid,
'lang':'J',
'statsDataId':statsDataId,
}
response = get_data(params)
s = response.text.find('"VALUE"') + len('"Value"\n')
f = io.StringIO(response.content.decode('utf-8')[s:])
df = pd.read_csv(f)
df = df.query('cat02_code == 1 and 年齢各歳 != "総数"')
df.loc[:, 'year'] = pd.to_datetime(df['時間軸(年月日現在)'], format='%Y年%m月%d日現在').dt.year
df.loc[:, 'age'] = df['年齢各歳'].str.extract(r'(\d+)').astype(int)
return df
df_2020_2023 = get_df('0003448228')
df_2015_2019 = get_df('0003459018')
df_2010_2014 = get_df('0004008040')
df_2005_2009 = get_df('0004010040')この表データたちを一つの表データにまとめます
df = pd.DataFrame()
target_columns = ['year', 'age', 'cat01_code', 'value']
for _df in [df_2005_2009, df_2010_2014, df_2015_2019, df_2020_2023]:
man = _df.query('cat01_code == 2').reset_index()
woman = _df.query('cat01_code == 3').reset_index()
df = pd.concat([df, man[target_columns]], axis=0)
df = pd.concat([df, woman[target_columns]], axis=0)
df = df.reset_index(drop=True)
y = df['value']
X = df.drop(columns=['value'])整形されたデータをスケーリングして、学習器が扱いやすいようにします。yの人口データは1000で割る形にしました。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X = pd.DataFrame(data=scaler.fit_transform(X), columns=X.columns)
y = y/1000あとはneural networkによって学習させます。lightgbmのような決定木だと未来予測は難しいので、今回はsklearnに実装してあるMLPRegressorを使いました。本気で人口予測するなら、モデルを選別したほうがいいです。
また、sklearnのMLPはただの多層パーセプトロンなので、精度があまり良くないため、層を深くしました。
from sklearn.neural_network import MLPRegressor
model_params = {
'hidden_layer_sizes':[100, 100, 100, 100, 100],
'max_iter':500,
'random_state':1,
}
model = MLPRegressor(**model_params).fit(X, y)あとは、年齢と年、性別を入れれば人口が出力されます。ためしに、2040年の人口ピラミッドを作成してみます。
def make_year_df(year):
data = []
for sex in [2, 3]:
for age in range(0, 101):
data.append({'year':year, 'age':age, "cat01_code":sex})
new_df = pd.DataFrame(data)
new_X = scaler.transform(new_df)
new_y = model.predict(new_X)
new_df['value'] = new_y * 1000
return new_df
def make_plot(plot_df, axes):
man = plot_df.query('cat01_code == 2').reset_index()
ax0 = axes[0].barh(man['age'], man['value'], align='center', color='#3AB0FF', height=1)
axes[0].set_xlim([0, 1200])
axes[0].invert_xaxis()
axes[0].set_title('男性')
woman = plot_df.query('cat01_code == 3')
ax1 = axes[1].barh(woman['age'], woman['value'], align='center', color='#F87474', height=1)
axes[1].set_xlim([0, 1200])
axes[1].set_title('女性')
plt.subplots_adjust(wspace=0, top=0.85, bottom=0.1, left=0.18, right=0.95)
axes[0].set_ylabel('年\n齢', rotation=0)
return ax0, ax1
fig, axes = plt.subplots(ncols=2, sharey=True)
plot_data = make_year_df(2010)
make_plot(plot_data, axes)2040年の人口ピラミッドが予測できました。ちょっとスムーズ過ぎる気もしますが、パラメータを調整すれば直るかもしれません。
各年のグラフをgifとして連続画にしてみてみます。
from matplotlib import animation
ims = []
fig, axes = plt.subplots(ncols=2, sharey=True)
for year in range(2000, 2100):
plot_data = make_year_df(year)
ax0, ax1 = make_plot(plot_data, axes)
ax3 = axes[1].text(0.47, 1.0, f'{year}年')
ims.append(ax0 + ax1 + (ax3,))
ani = animation.ArtistAnimation(fig, ims, interval=50, repeat=True)
ani.save('/work/test_anim.gif', writer='imagemagick', dpi = 300)matplotlibでアニメーションを描画しましたが、各画像を保存してgifに繋げたほうが良かったかもしれません。
数十秒待つと、gifが保存されました。
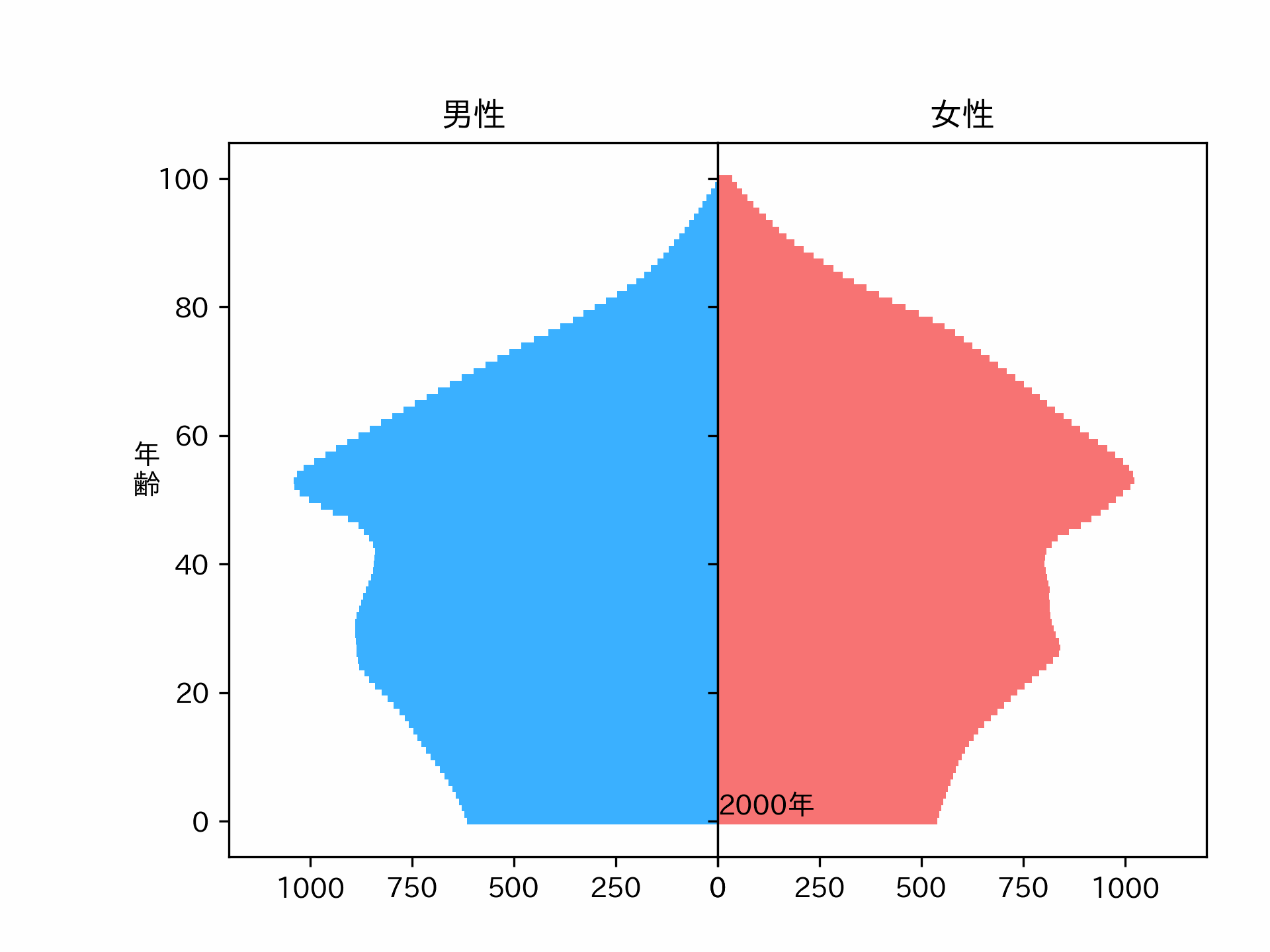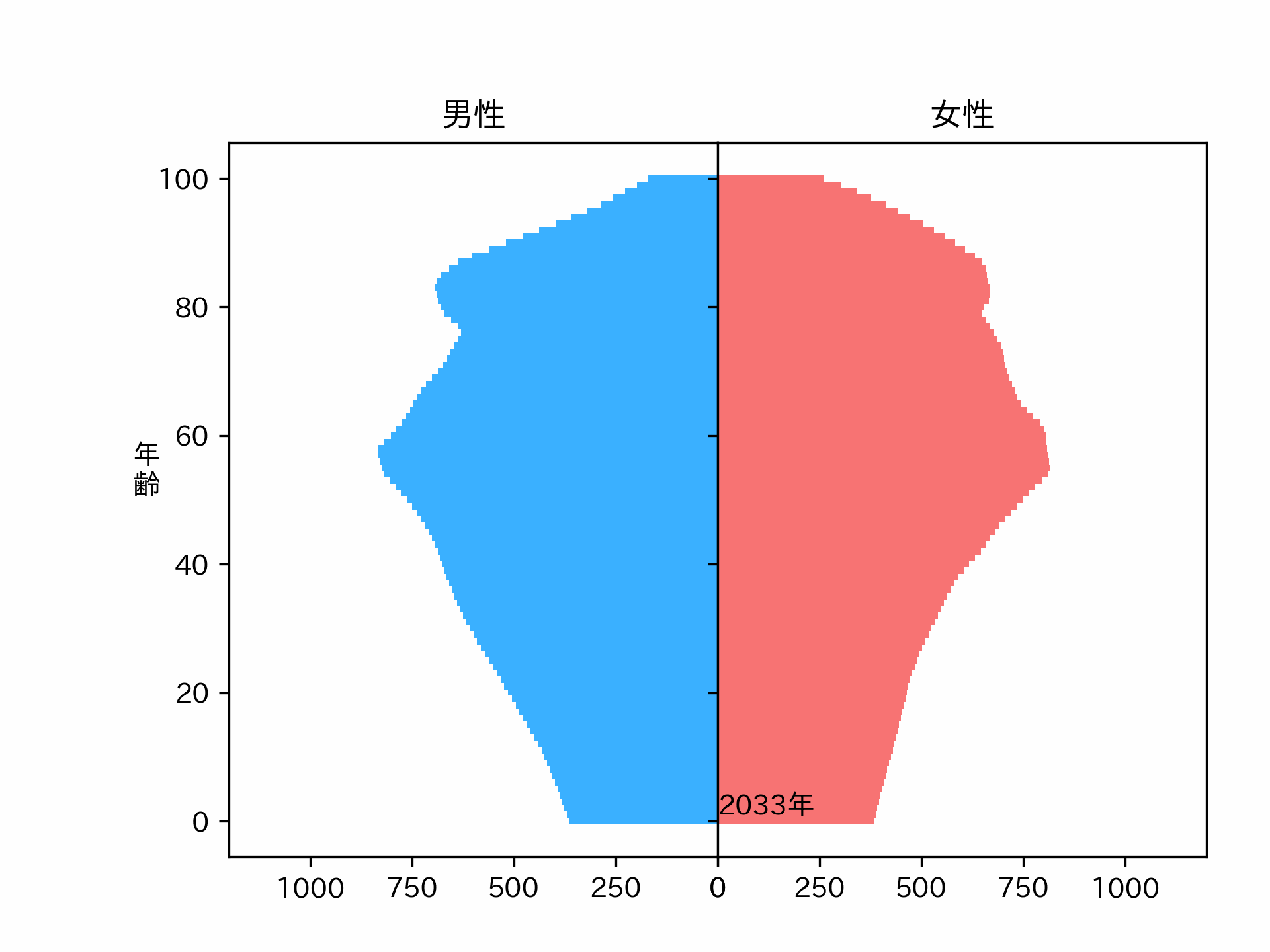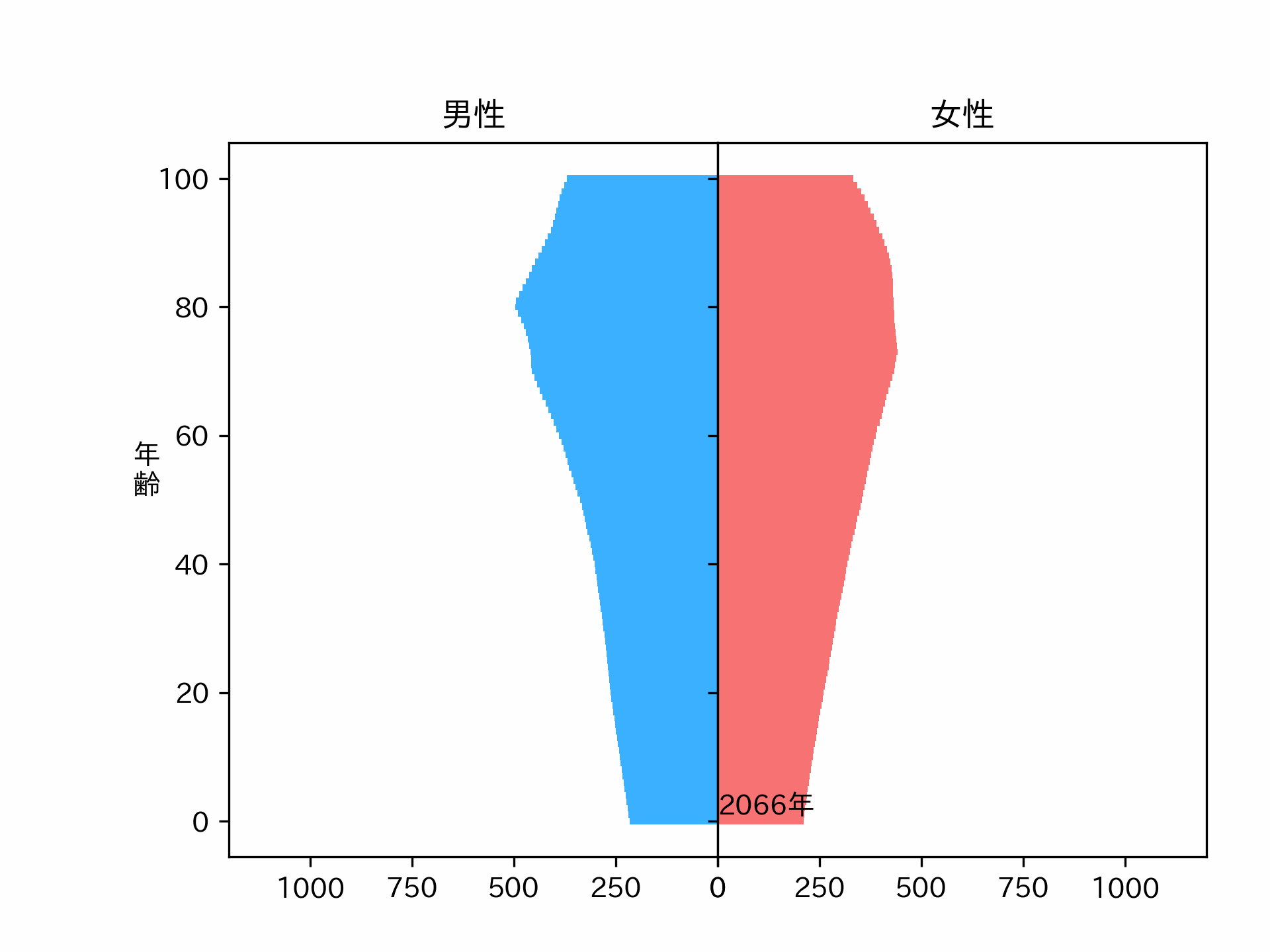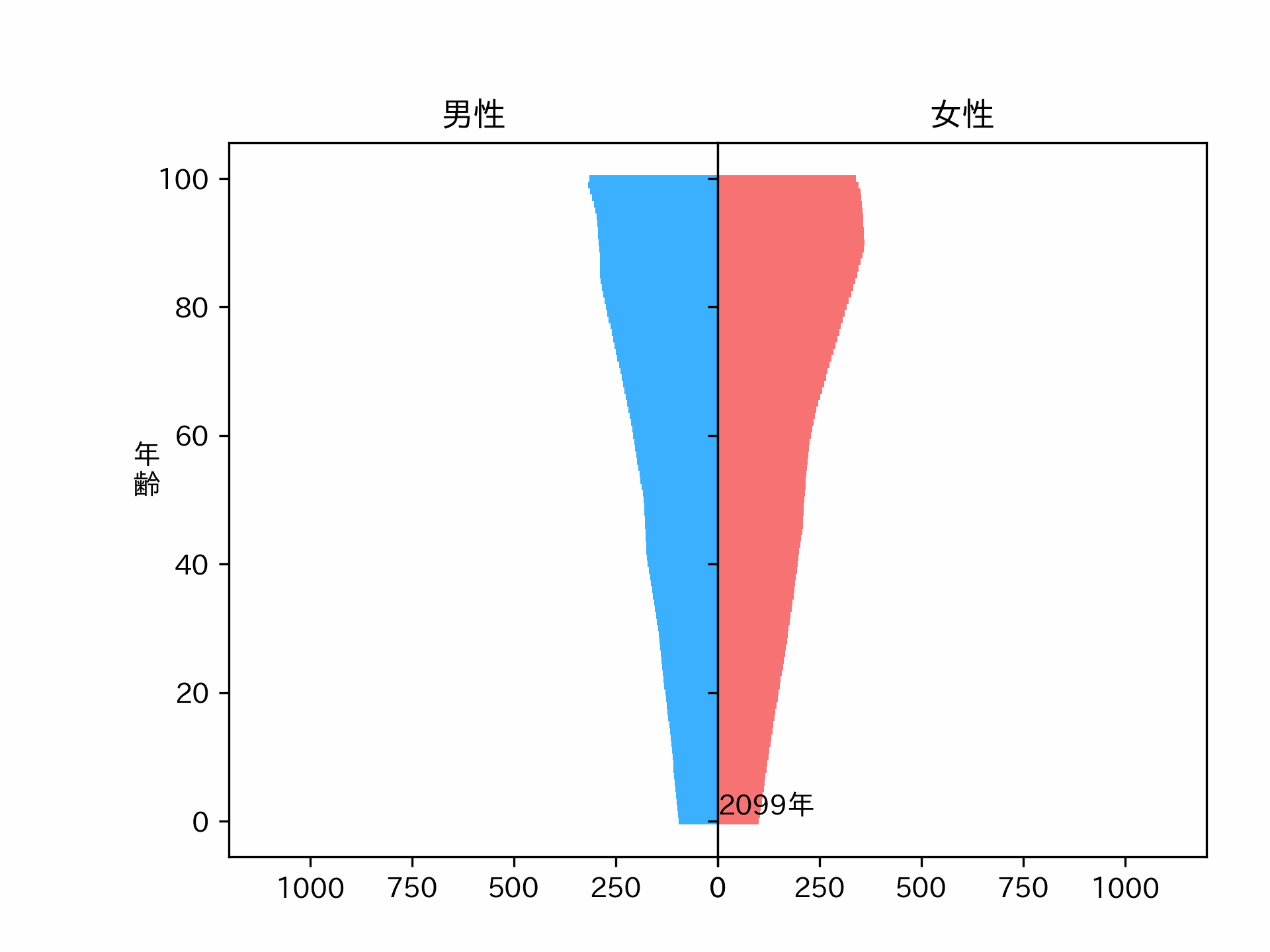
こういう感じの結果が欲しかったんです。
※人口動態の計算モデルは確立されているので、Neural Networkで予測した人口動態はおそらく正しくありません。
まとめ
今回は、統計局のe-StatのAPIを使って統計データを取得してみました。
pythonで取得し、pandasのDataFrameへ変換が容易なため、簡単に分析に使えました。
また、NeuralNetworkを使って将来の人口ピラミッドの予測をしてみました。
他のデータを取ってきて、分析に付け加えることも容易なため、今後のやってみたいと思います。

