
これまでオッズ情報を使わなかった理由
さて、これまでの予測ではオッズ情報を特徴量として利用しませんでした。
この理由は、オッズがレースが始まるまで確定しないためです。
実際にレースのページを見ていると、出馬までにはオッズはかなり変化します。
そして、オッズによって戻って来るお金は変わります。
だからこそ、賭ける人間はレースが始まる直前までオッズを観測し、直前まで賭ける対象を選ぶのです。
これは数学的にも同様で、利益とは(オッズ×当たる確率)の期待値で表されることを「[閑話]強化学習は競馬予想に使えない」でも話しました。
つまり、オッズが直前まで変動するということは利益が変動するため、数学的も直前まで待つことが正しいとされます。
つまり、オッズはレースが始まるまでには絶対に確定しない値であり、事前に使うことが困難です。
また、レースへのネット投票には数秒~数十秒のタイムラグが存在することから、ギリギリまで待つことは、ネット競馬予測&投票システムを構築する上では事実上不可能だと思われます。
オッズ情報の有用性
しかし、オッズが情報として有意義なのは少し実験をすればわかります。オッズ情報を使うことで、ほぼすべての予測で精度は向上します。
これは、オッズの情報が学習器(投票した人間たち)のアンサンブルであると考えれば納得がいくと思います。
なんとかして、このオッズ情報を利用したと思うのは当たり前です。
さらに言えば、(オッズ×当たる確率)の期待値で表されるのですから、オッズが既知であれば当たる確率を求めるだけで、儲かるということになります。
事前オッズをノイズの付加で実現する
そこで、オッズにノイズを付加し、不確定な事前オッズとして使うことを考えます。
直前までオッズを見ることが利益の最大化にとっては有用ですが、実際にはレースが始まる数分前や数時間前に投票する人もいます。
その時点のオッズは、実際のオッズとは異なりますが、これは実際のオッズにノイズを付与するだけで実現できる可能性があります。
そこで、いくつかのレースを数分前から見てみて、オッズの変化を見てみます。つまり、ノイズの大きさと傾向を調べてみるのです。
事前オッズと確定オッズを集める
スクレイピングとスケジュールライブラリを利用して、試合の数時間前、10分前、終了後の3つの時点でのオッズを収集します。
使用したプログラムは次のとおりです。
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
import json
import schedule
import datetime
import time
import os
def get_odds(url, race_date, next_check):
print(f'access {url} : next_check = {next_check}')
with webdriver.Remote(
command_executor="http://chrome:4444/wd/hub",
options=webdriver.ChromeOptions()
) as browser:
browser.implicitly_wait(10)
ret = {}
browser.get(url)
odds_data_list = browser.find_elements(By.CSS_SELECTOR, 'td.Txt_R.Popular')
horse_name_list = browser.find_elements(By.CLASS_NAME, 'HorseName')
ret['horse_data'] = []
for n in range(len(odds_data_list)):
ret['horse_data'].append({
'number':n+1,
'name':horse_name_list[n+1].text,
'odds':odds_data_list[n].text
})
race_data_01 = browser.find_element(By.CLASS_NAME, 'RaceData01').text
race_start_time = race_data_01.split('/')[0].strip()
race_start_time = race_start_time[:-2]
race_id = url.split('=')[1][:-3]
ret['race_data'] = {
'start_time':race_start_time,
'race_id':race_id,
'url':url
}
if next_check:
start_time = datetime.datetime.fromisoformat(f'{race_date}T{race_start_time}')
check_time = start_time - datetime.timedelta(minutes=10)
print(f'{race_id} : start {start_time}, check {check_time}')
schedule.every().day.at(f'{check_time.hour:02}:{check_time.minute:02}').do(
save_data, url=url, save_tag='before10min', save_name=race_id, race_date=race_date, next_check=False
)
check_time = start_time + datetime.timedelta(hours=1)
print(f'{race_id} : start {start_time}, check {check_time}')
schedule.every().day.at(f'{check_time.hour:02}:{check_time.minute:02}').do(
save_data, url=url, save_tag='finished', save_name=race_id, race_date=race_date, next_check=False
)
return ret
def save_data(url, save_tag, save_name, race_date, next_check=True):
ret = get_odds(url, race_date, next_check)
file_name = f'odds_raw_data/{save_name}_{save_tag}.json'
with open(file_name, 'w') as f:
json.dump(ret, f, indent=4, ensure_ascii=False)
return schedule.CancelJob
def get_races(url):
with webdriver.Remote(
command_executor="http://chrome:4444/wd/hub",
options=webdriver.ChromeOptions()
) as browser:
browser.implicitly_wait(10)
ret = []
browser.get(url)
race_list = browser.find_elements(By.CLASS_NAME, 'RaceList_DataItem')
for race_item in race_list:
url = race_item.find_element(By.TAG_NAME, 'a').get_attribute('href')
ret.append(url)
return ret
if __name__ == '__main__':
os.makedirs('odds_raw_data', exist_ok=True)
race_date = '2024-03-17'
urls = get_races('https://race.netkeiba.com/top/race_list.html?kaisai_date=20240317¤t_group=1020240316#racelist_top_a')
for url in urls:
race_id = url.split('=')[1][:-3]
shutuba_url = f'https://race.netkeiba.com/race/shutuba.html?race_id={race_id}&rf=race_submenu'
save_data(shutuba_url, 'before1day', race_id, race_date)
print('wait schedule')
while True:
schedule.run_pending()
time.sleep(1)金曜日と土曜日の夜に、race_dateとurlsの引数を変更して実行します。
すると当日(土曜日と日曜日)のレースの直前や終了時のオッズを収集してくれます。
2日間で200頭のオッズデータが収集できました。
事前オッズと確定オッズを分析する
ipynbファイルで分析をします。以下はその記録です。
まず、適当なライブラリをインポートします。
import json
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltglobを使って、収集したデータを読み込み、一つにまとめます。
import glob
read_dir = '/work/odds_raw_data'
data_dict = {}
for file_path in glob.glob(f'{read_dir}/*.json'):
file_name = file_path.split('/')[-1][:-1*len('.json')]
race_id, file_tag = file_name.split('_')
if race_id not in data_dict:
data_dict[race_id] = {}
with open(file_path, 'r') as f:
odds_data = json.load(f)
df = pd.DataFrame(data=odds_data['horse_data'], columns=['number', 'odds'])
data_dict[race_id][file_tag] = df集めたデータを一つのデータフレームに整形します。
ret_list = []
for race_id, tag_dfs in data_dict.items():
ret_df = pd.DataFrame()
for tag, df in tag_dfs.items():
ret_df[f'{tag}_odds'] = df['odds']
ret_df['number'] = df['number']
ret_df['race_id'] = race_id
ret_list.append(ret_df)
df = pd.concat(ret_list, axis=0).reset_index(drop=True)
df['before1day_odds'] = df['before1day_odds'].astype(float)
df['before10min_odds'] = df['before10min_odds'].astype(float)
df['finished_odds'] = df['finished_odds'].astype(float)
print(df)整形できていれば、次のようなデータフレームが得られます。
before1day_odds finished_odds before10min_odds number race_id
0 12.9 57.8 27.0 1 202407010307
1 8.6 10.8 10.1 2 202407010307
2 12.7 44.3 23.2 3 202407010307
3 5.2 2.5 4.1 4 202407010307
4 20.8 41.6 22.1 5 202407010307
.. ... ... ... ... ...
962 67.8 69.6 60.9 11 202409010710
963 5.6 7.6 7.9 12 202409010710
964 18.7 19.5 25.1 13 202409010710
965 9.9 6.4 10.8 14 202409010710
966 100.1 308.6 149.2 15 202409010710
[967 rows x 5 columns]すこし、プロットして事前オッズと確定オッズの分布を見てみます。
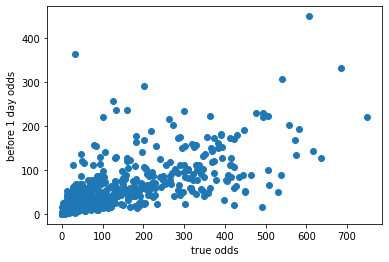
plt.scatter(df['finished_odds'], df['before1day_odds'])
plt.xlabel('true odds')
plt.ylabel('before 1 day odds')前日の夜の事前オッズと確定オッズの分布は次のとおりでした。
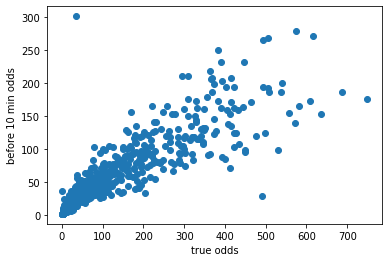
plt.scatter(df['finished_odds'], df['before10min_odds'])
plt.xlabel('true odds')
plt.ylabel('before 10 min odds')10分前の事前オッズと確定オッズの分布は次のとおりでした。
期待していた通りのデータが集められていそうです。
これらの差についての確率密度分布を見てみます。
diff = np.log(df['finished_odds']) - np.log(df['before1day_odds'])
print(f'mean = {np.mean(diff)}, var = {np.var(diff)}')
plt.hist(diff, bins=20)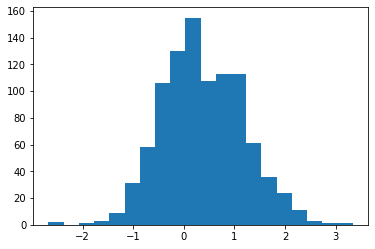
mean = 0.381205067210959, var = 0.6425916850479931
diff = np.log(df['finished_odds']) - np.log(df['before10min_odds'])
print(f'mean = {np.mean(diff)}, var = {np.var(diff)}')
plt.hist(diff, bins=20)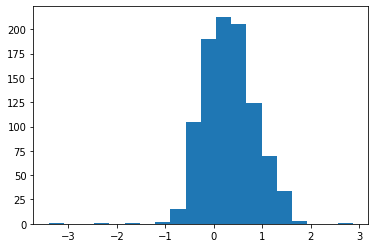
mean = 0.31484275640134174, var = 0.286534397891739
すこし歪ですが、正規分布として考えても良さそうな形です。
事前オッズを生成する①
事前オッズと確定オッズの差分を次の式で表します。
$$
diff = \log{(odds_\text{true})} – \log{(odds_\text{prev})} = N(\mu, \sigma^2)
$$
これを式変形すれば、
$$
odds_\text{prev} = \frac{odds_\text{true}}{\exp{(N(\mu, \sigma^2))}}
$$
ですから、確定オッズに上の式に従ってノイズを付与すれば事前オッズが得られます。
試してみます。
1日前の事前オッズ(再現値)と確定オッズの分布
diff = np.random.normal(0.381205067210959, 0.6425916850479931, len(df))
noised_odds = df['finished_odds']/np.exp(diff)
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(121)
plt.scatter(df['finished_odds'], noised_odds)
plt.title('noised odds')
plt.xlabel('true odds')
plt.ylabel('noised odds')
plt.ylim([-20, df['before1day_odds'].max()])
plt.subplot(122)
plt.legend()
plt.scatter(df['finished_odds'], df['before1day_odds'])
plt.title('before1day_odds')
plt.xlabel('true odds')
plt.ylabel('before 1 day odds')
plt.ylim([-20, df['before1day_odds'].max()])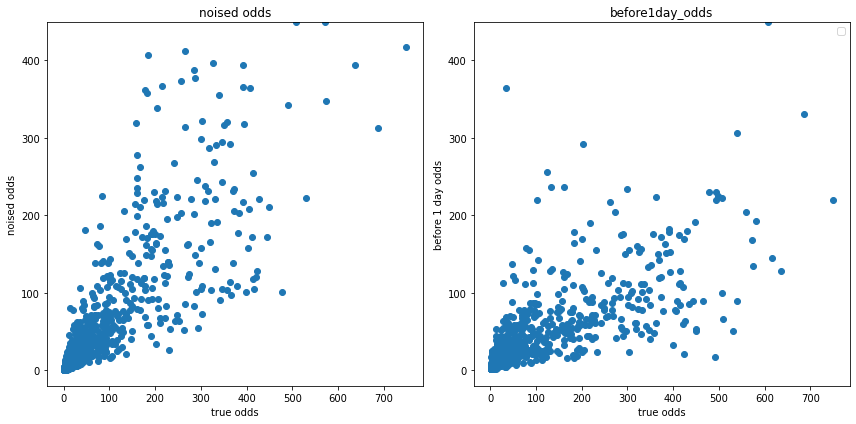
10分前の事前オッズ(再現値)と確定オッズの分布
diff = np.random.normal(0.31484275640134174, 0.286534397891739, len(df))
noised_odds = df['finished_odds']/np.exp(diff)
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(121)
plt.scatter(df['finished_odds'], noised_odds)
plt.title('noised odds')
plt.xlabel('true odds')
plt.ylabel('noised odds')
plt.ylim([-20, df['before10min_odds'].max()])
plt.subplot(122)
plt.legend()
plt.scatter(df['finished_odds'], df['before10min_odds'])
plt.title('before1day_odds')
plt.xlabel('true odds')
plt.ylabel('before 10 min odds')
plt.ylim([-20, df['before10min_odds'].max()])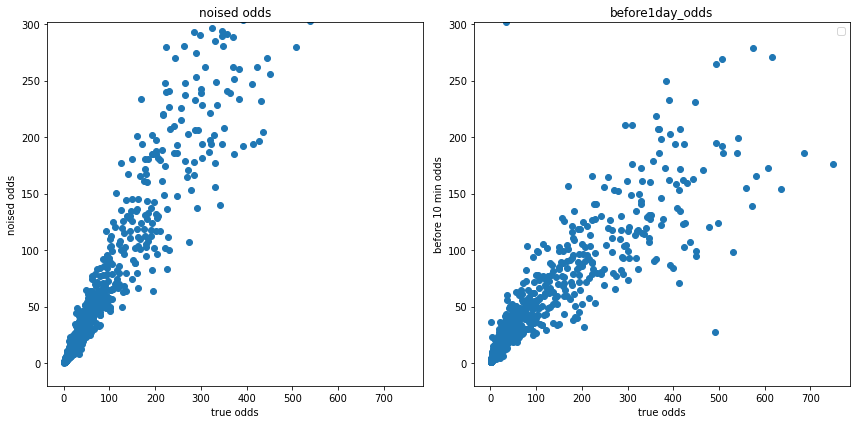
傾向的にはあっていそうな気もしますが、実際の分布(右側の図)はもう少し、曲がっているような気がします。
つまり、正規分布のノイズを付与するだけでは、事前オッズを再現できないということでしょうか?
事前オッズを生成する②
もう少し分析を行います。
差分(ノイズ)について、オッズとの相関を見てみます。
diff = np.log(df['finished_odds']) - np.log(df['before1day_odds'])
plt.scatter(df['finished_odds'], diff)
plt.xlabel('true odds')
plt.ylabel('diff')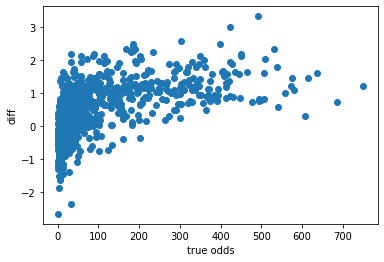
diff = np.log(df['finished_odds']) - np.log(df['before10min_odds'])
plt.scatter(df['finished_odds'], diff)
plt.xlabel('true odds')
plt.ylabel('diff')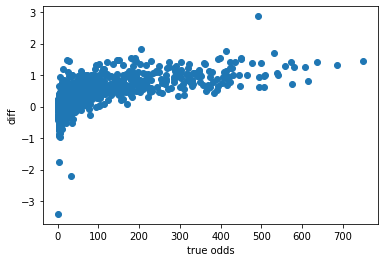
before1day_oddsのほうが顕著ですが、2つの正規分布から成り立っているような感じがあります。
1つ目の正規分布はオッズが小さいときに作用し、平均0、分散値(-2~+2)の幅でぶれているように見えます。
2つ目の正規分布はオッズが大きいときに作用し、平均1、分散値(-1~+1)の幅でぶれているように見えます。
これについて仮説を立てます。
オッズが小さい馬券は、オッズの偏りを考慮して購入するため、シーソーゲームのようになり、オッズが正規分布でブレる。
オッズが大きい馬券は、直前で購入する人が相対的に少ないため(直前で購入する人は、割の良い当たりそうな馬券を買う)、オッズが増える方向にブレる。
なかなか、ありそうな仮説です。
つまり、2つの正規分布(ノイズ)の作用があると考えて、事前オッズを生成すれば良いと思います。
$$
N(\mu_1, \sigma_1^2)
\
N(\mu_2, \sigma_2^2)
$$
これら2つのノイズの重み付けをする関数を用意します。
これは、オッズ1.0で前者の正規分布が強くなり、オッズが大きくなるほど後者の正規分布が強くなるように適当に決めました。
$$
p = \exp{0.02(-x+1)} + 1
$$
このxは確定オッズです。
あとは、重み付き平均を取れば、新しいノイズの出来上がりです。
$$
N_{new} = N(\mu_1, \sigma_1^2) * (1-p) + N(\mu_2, \sigma_2^2) * p
$$
正規分布の平均や分散、重み関数の係数を自分で決めなければいけないのが難点ですが、適当に調整しながら決めてあげます。
lower_noise = np.random.normal(0.0, 0.7, len(df))
upper_noise = np.random.normal(1.0, 0.7, len(df))
p_func = lambda x : -np.exp((-x+1)*0.02) + 1
p = p_func(df['finished_odds'])
noise = lower_noise*(1-p) + upper_noise*p
diff = np.log(df['finished_odds']) - np.log(df['before1day_odds'])
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(121)
plt.scatter(df['finished_odds'], diff, label='original')
plt.title('diff')
plt.xlabel('true odds')
plt.ylabel('diff')
plt.ylim([-3, 3.5])
plt.subplot(122)
plt.legend()
plt.scatter(df['finished_odds'], noise, label='maked')
plt.title('noise')
plt.xlabel('true odds')
plt.ylabel('noise')
plt.ylim([-3, 3.5])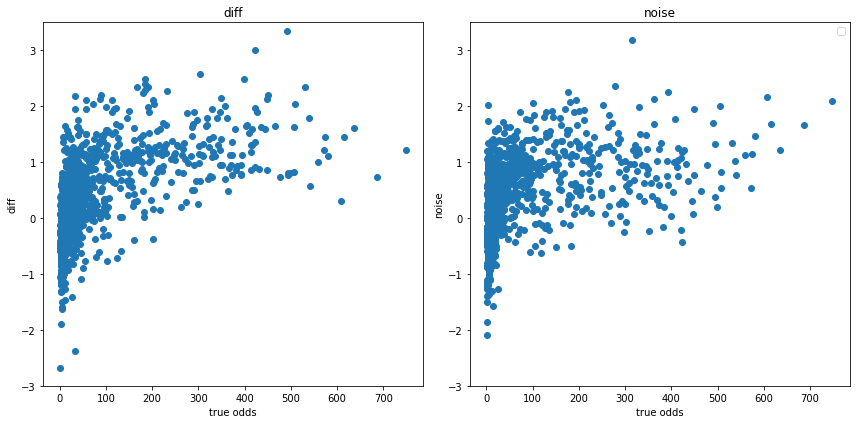
いい感じに、確定オッズとの相関が再現できてると思います。
このノイズを確定オッズに付与して、事前オッズと確定オッズの分布を見てみます。
lower_noise = np.random.normal(0.0, 0.7, len(df))
upper_noise = np.random.normal(1.0, 0.7, len(df))
p_func = lambda x : -np.exp((-x+1)*0.02) + 1
p = p_func(df['finished_odds'])
noise = lower_noise*(1-p) + upper_noise*p
noised_odds = df['finished_odds']/np.exp(noise)
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(121)
plt.scatter(df['finished_odds'], noised_odds)
plt.title('noised odds')
plt.xlabel('true odds')
plt.ylabel('noised odds')
plt.ylim([-20, df['before10min_odds'].max()])
plt.subplot(122)
plt.legend()
plt.scatter(df['finished_odds'], df['before1day_odds'])
plt.title('before1day_odds')
plt.xlabel('true odds')
plt.ylabel('before 1 day odds')
plt.ylim([-20, df['before10min_odds'].max()])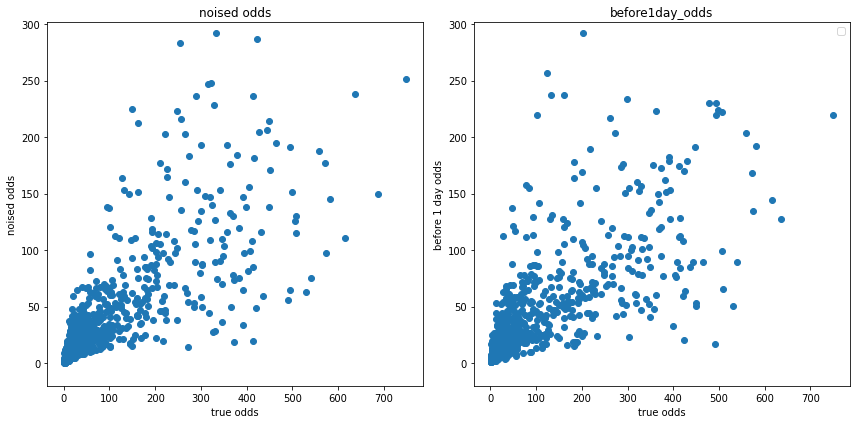
正規分布のノイズを一つだけ付与するよりも、明らかに再現度が向上しています。
10分前の事前オッズについても同様に再現してみます。
lower_noise = np.random.normal(0.0, 0.5, len(df))
upper_noise = np.random.normal(0.8, 0.3, len(df))
p_func = lambda x : -np.exp((-x+1)*0.02) + 1
p = p_func(df['finished_odds'])
noise = lower_noise*(1-p) + upper_noise*p
diff = np.log(df['finished_odds']) - np.log(df['before10min_odds'])
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(121)
plt.scatter(df['finished_odds'], diff, label='original')
plt.title('diff')
plt.xlabel('true odds')
plt.ylabel('diff')
plt.ylim([-3, 3.5])
plt.subplot(122)
plt.legend()
plt.scatter(df['finished_odds'], noise, label='maked')
plt.title('noise')
plt.xlabel('true odds')
plt.ylabel('noise')
plt.ylim([-3, 3.5])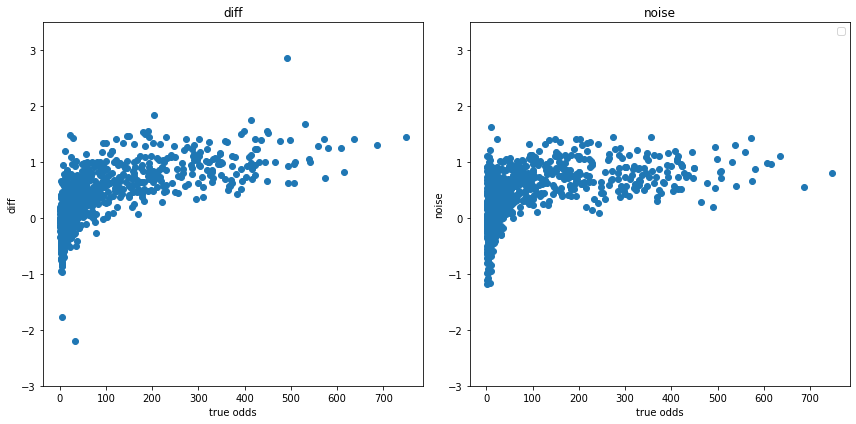
lower_noise = np.random.normal(0.0, 0.5, len(df))
upper_noise = np.random.normal(0.8, 0.3, len(df))
p_func = lambda x : -np.exp((-x+1)*0.02) + 1
p = p_func(df['finished_odds'])
noise = lower_noise*(1-p) + upper_noise*p
noised_odds = df['finished_odds']/np.exp(noise)
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(121)
plt.scatter(df['finished_odds'], noised_odds)
plt.title('noised odds')
plt.xlabel('true odds')
plt.ylabel('noised odds')
plt.ylim([-20, df['before10min_odds'].max()])
plt.subplot(122)
plt.legend()
plt.scatter(df['finished_odds'], df['before10min_odds'])
plt.title('before1day_odds')
plt.xlabel('true odds')
plt.ylabel('before 10 min odds')
plt.ylim([-20, df['before10min_odds'].max()])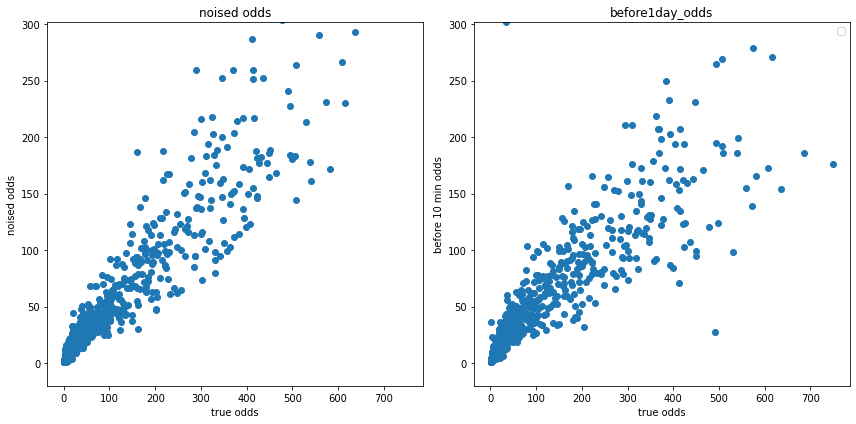
これもいい感じに再現できてそうです。
実際の学習には、この10分前の事前オッズの再現値を入力することになります。
