
このプログラムの目的
このプログラムはnsga2_neuroevo.pyを呼び出し,取引最適化を開始させることを目的とします.
また,手法・環境のパラメータやデータセットのパスなどをここで指定します.
work_share
├07_evolutionary_algorithms
├Dockerfile
├docker-compose.yml
└src
├result(自動生成)
├neuro_evolution_torch
| ├nsga2_neuroevo.py
| ├torch_model.py
| ├simulation_cython.pyx
| └setup.py
└experiment01.py (これを作成)実験プログラム
今回の実験では次のようなパラメータを設定しました.
import pandas as pd
import os
import json
import neuro_evolution_torch.nsga2_neuroevo as neuroevo
import warnings
warnings.simplefilter('ignore')
def run(args):
with open(f'{args["result_dir"]}/args.json', 'w') as f:
json.dump(args, f, indent=4, ensure_ascii=False)
learner = neuroevo.NSGA2_Learner(
max_generation=args['max_generation'],
seed=args['seed'],
pop_size=args['pop_size'],
init_money=args['init_money'],
device=args['device'],
num_select=args['num_select'],
train_start_date=args['train_start_date'],
train_end_date=args['train_end_date'],
re_production_type=args['re_production_type'])
learner.learning(args)
def experiment1():
dataset_list = [
('../dataset_pred/non_fitting_0.3', 'nf0.3'),
('../dataset_pred/non_fitting_0.5', 'nf0.5'),
('../dataset_pred/non_fitting_1.0', 'nf1.0'),
]
training_term_list = [
('2017-01-01', '2022-01-01')
]
for train_start_date, train_end_date in training_term_list:
for dataset_dir, tag1 in dataset_list:
result_dir = f'result/experiment01_1/{train_start_date}_{train_end_date}_{tag1}'
#result_dir = f'result/experiment09/test_{tag1}'
for run_seed in range(1):
result_seed_dir = f'{result_dir}/{run_seed}'
os.makedirs(result_seed_dir, exist_ok=True)
args = {
'result_dir':result_seed_dir,
'dataset_dir':dataset_dir,
'init_money':10_000_000,
'max_generation':200,
'pop_size':500,
'seed':run_seed,
'save_interval':100,
'device':'cuda',
'num_select':9,
'train_start_date':train_start_date,
'train_end_date':train_end_date,
're_production_type':'crossover'
}
run(args)
if __name__ == '__main__':
experiment1()実験結果
non_fitting_0.3の場合
200世代目のパレートフロントか以下のような感じでした.
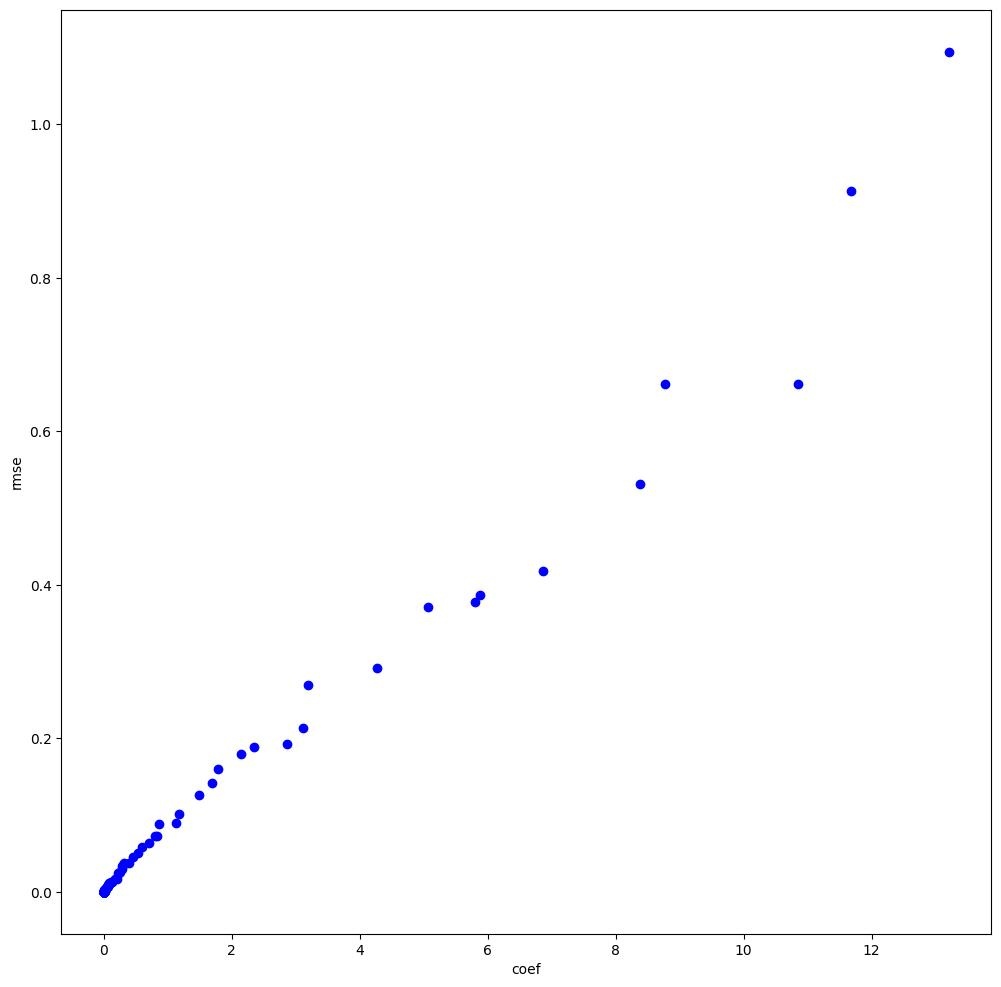
おもったよりカーブを描いていませんが,傾きが増加すると回帰誤差も増加する傾向なのは想定内です.
そして,このパレートフロントには207個のユニーク解が存在しました.
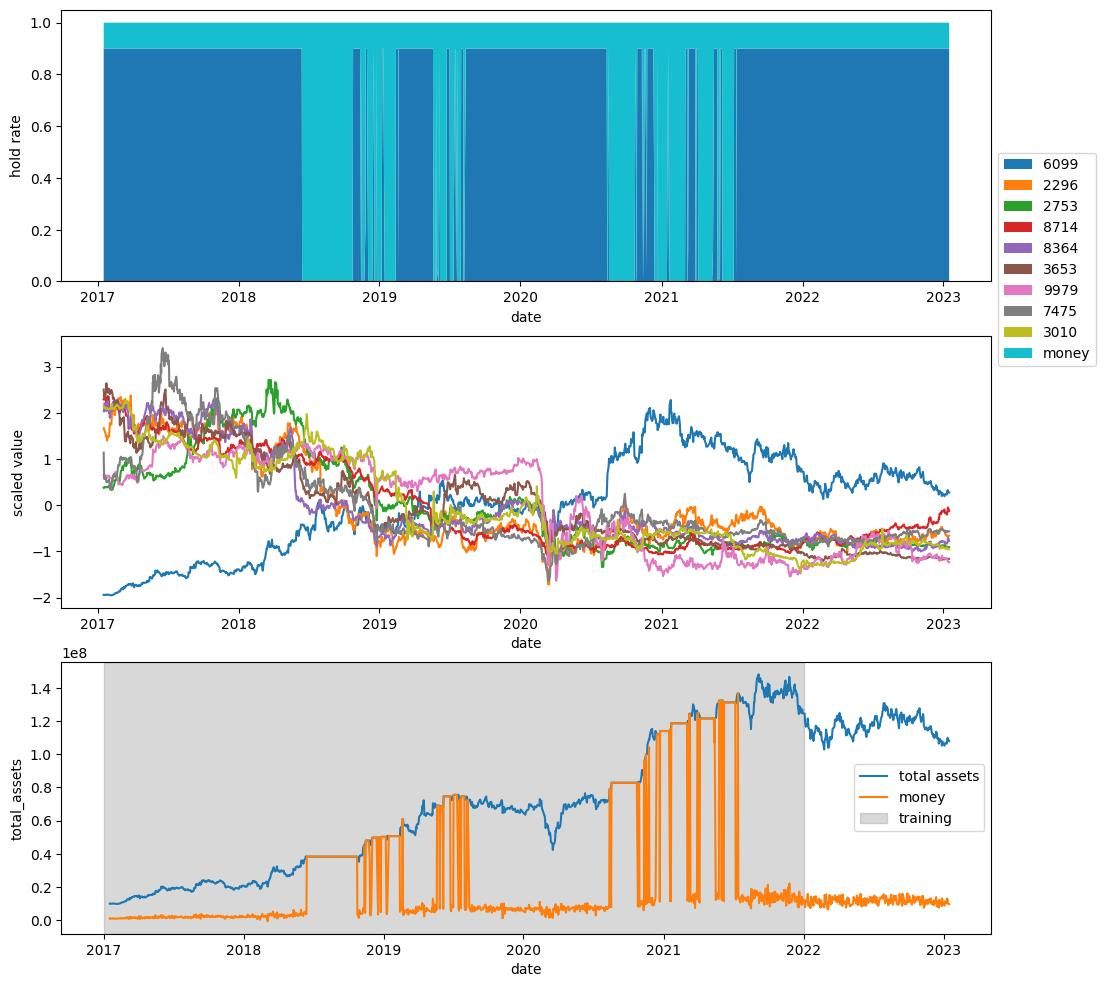
例えばこんな解や
こんな解のように
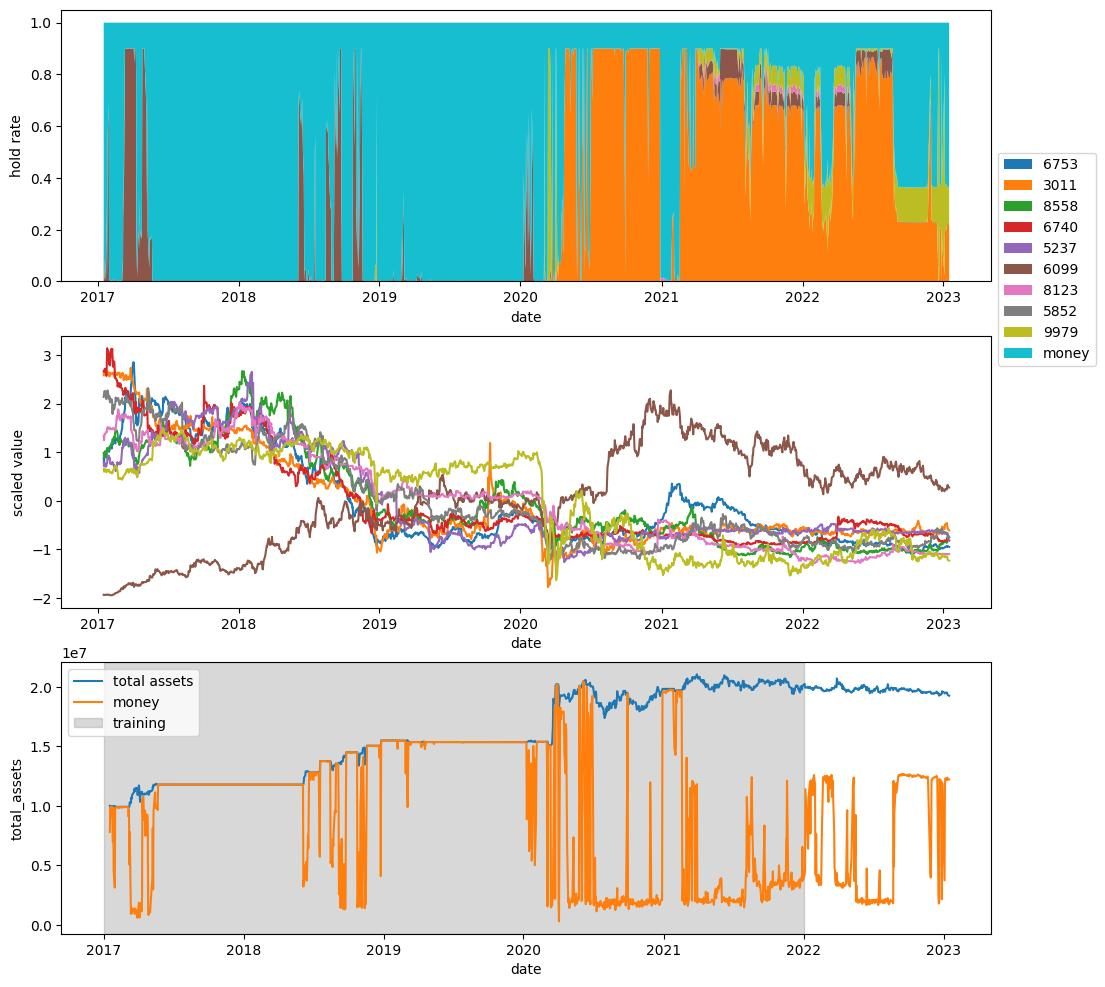
ほとんどの解は過学習しており,テスト期間で利益を上げることができていません.
一方で,こんな解や
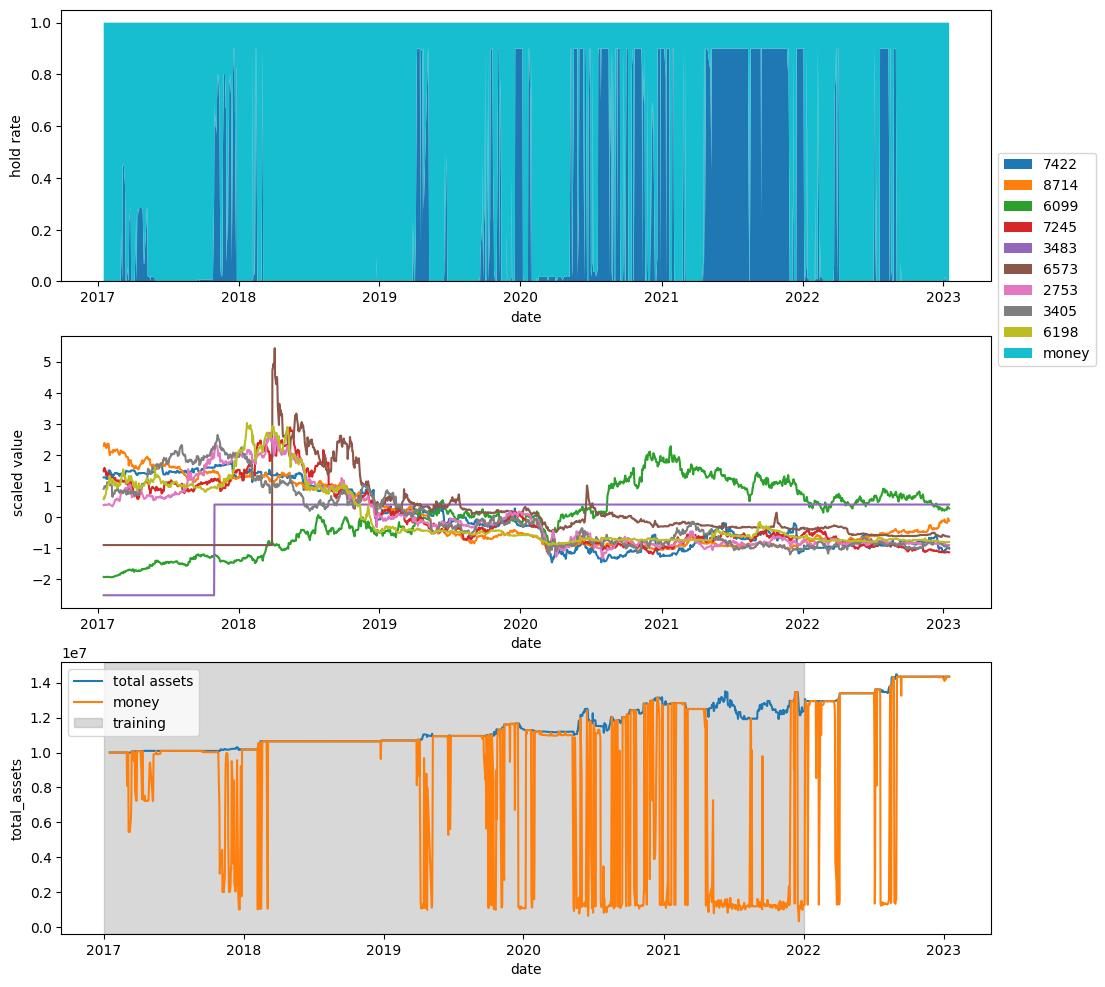
こんな解のように
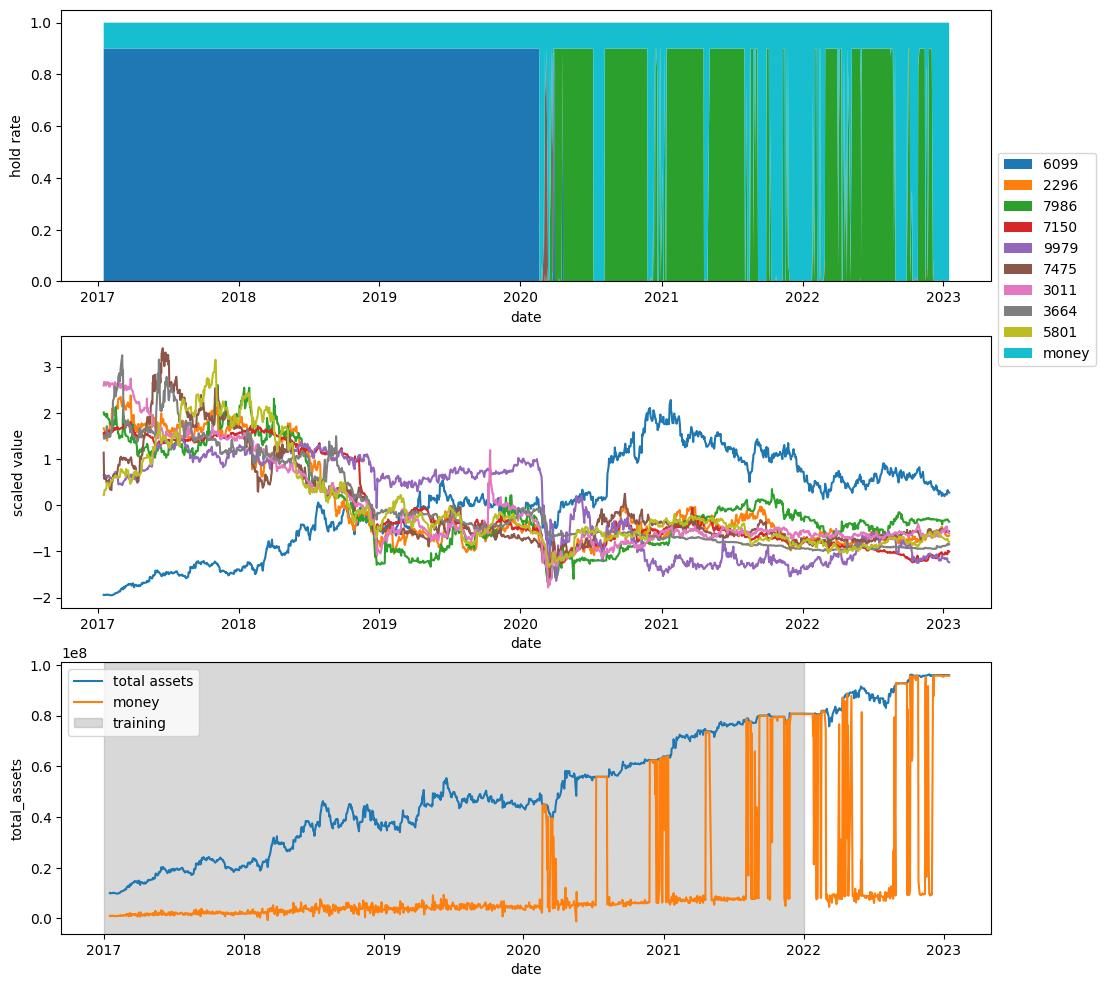
テスト期間でも利益があがる解があることもわかります.
特に図1-4を見ると,2020年半ばから銘柄7986を多く取引していることがわかりますが(図中上部),7986は単調に増加している銘柄ではない(図中中部)ので,期待していた取引戦略が得られていることがわかります.
バグについて
non_fitting_0.5やnon_fitting_1.0のデータセットでは一部の解にバグが生じていることがわかっている.
例えば以下の図では,総資産が10^14を超えているし,現金(money)が総資産を上回っている.
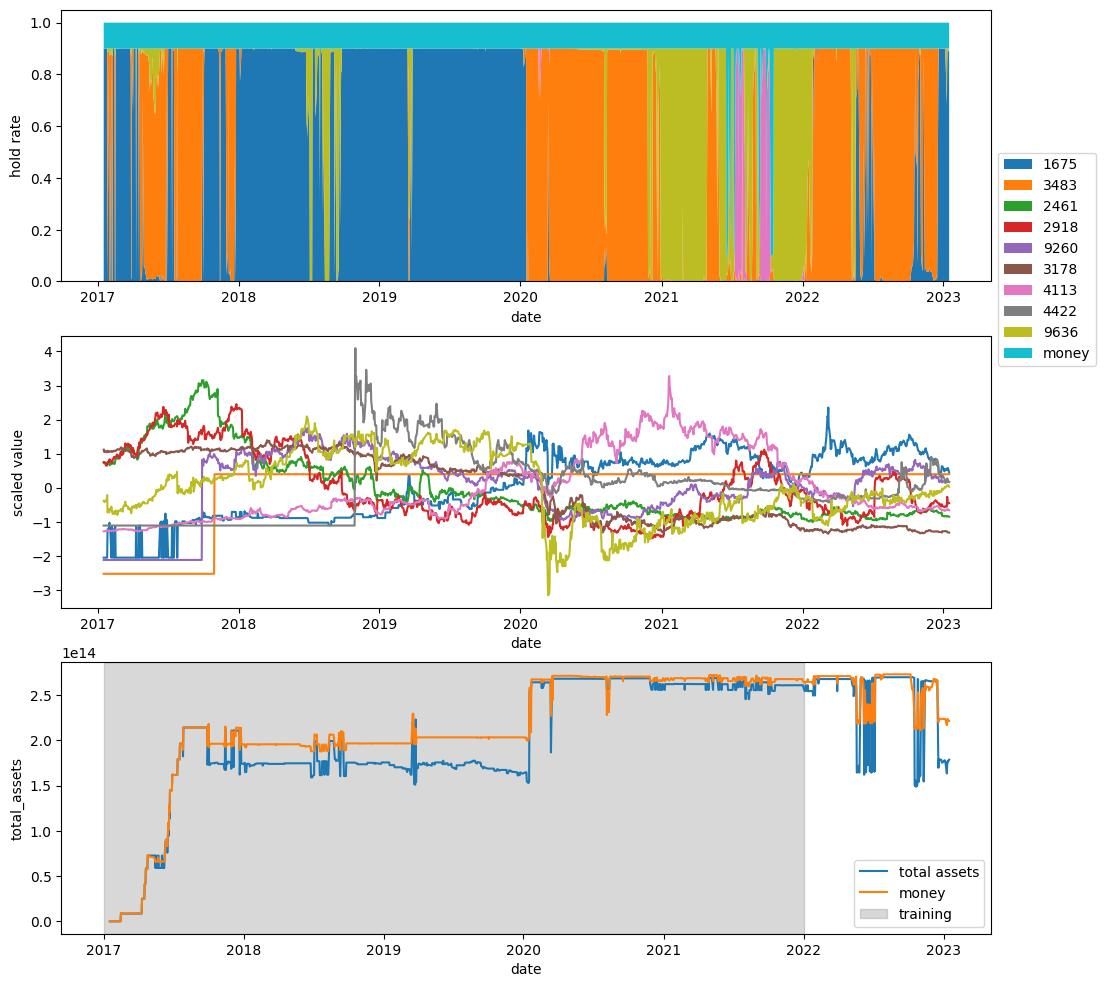
これは取引している銘柄を見ればわかるが,銘柄1675の2017~2018の株価推移が異常な値であったためである.この異常な銘柄を取引してしまうと,総資産が爆発的に増え,オーバーフローしてしまう.
このバグはnon_fitting_0.3では生じないが,これはnon_fitting_0.3に含まれる銘柄が他よりも少ないため,異常な値をとる銘柄が入っていないだけであると考えられる.
もちろんテスト期間でも利益を上げられる解は次のようなものや,
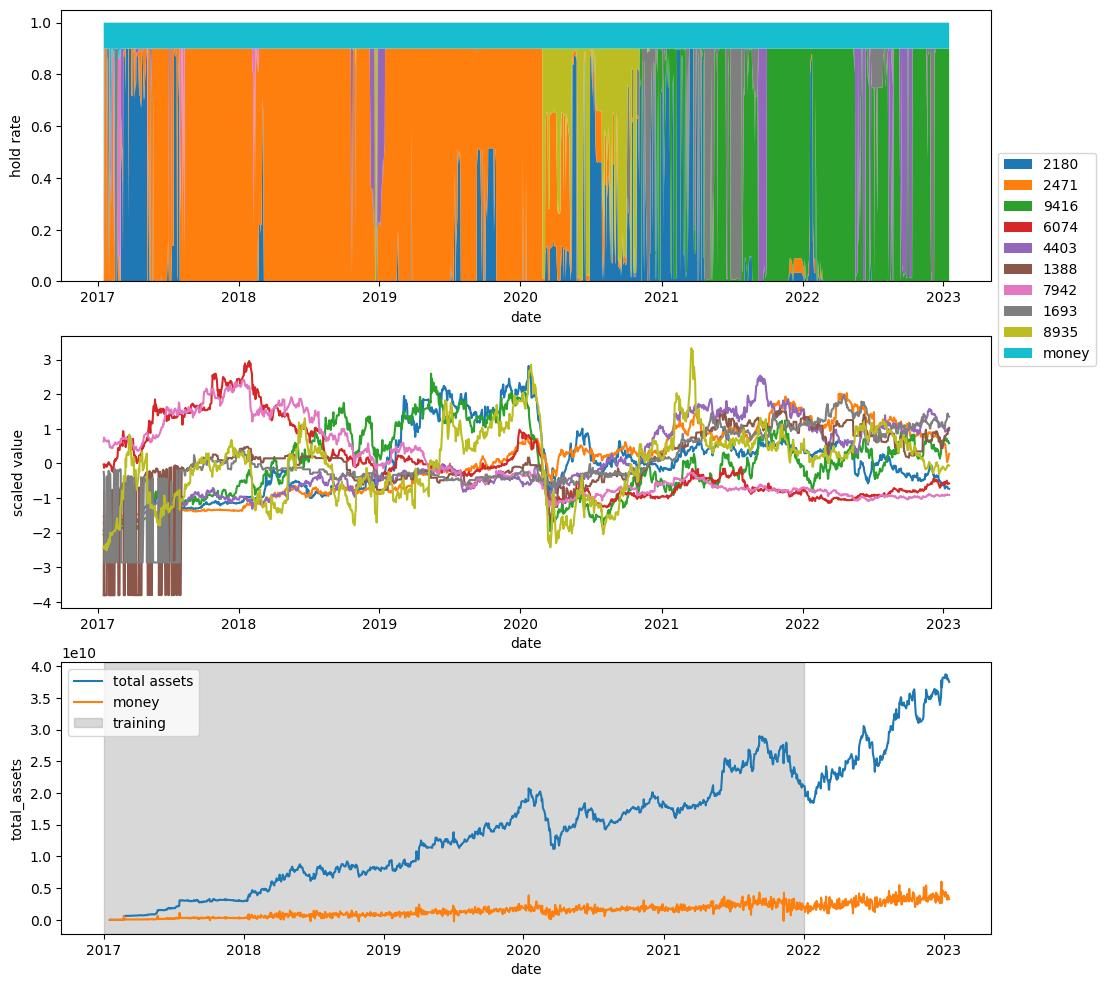
次のようなものがあった.
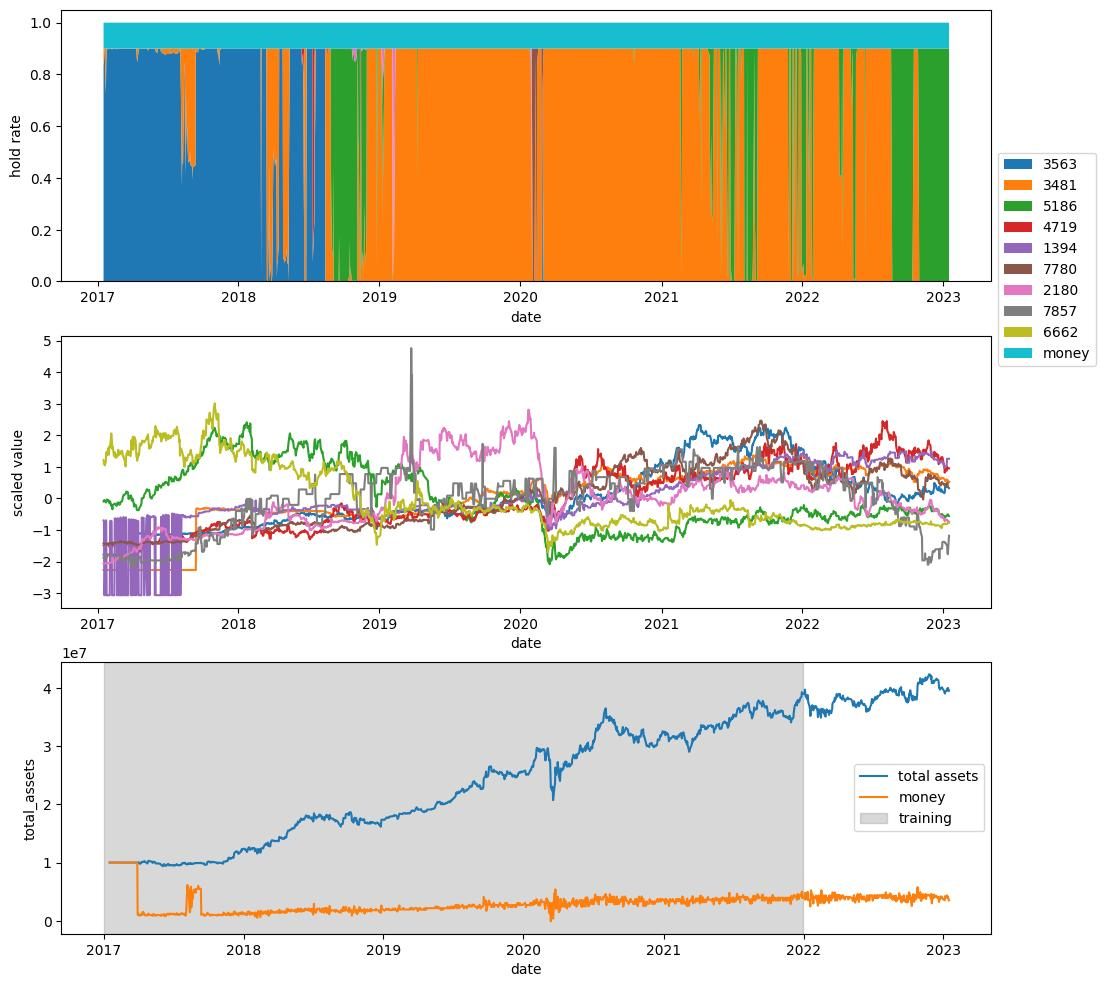
まとめ
実験によりテスト期間でも利益を上げられる解が存在することがわかりました.
しかし、偶然株価が上がった銘柄を保有していただけという可能性もあります.
注意:この解を実運用する際は注意してください.この解は確かに学習・テスト期間の両方で利益が上がることが確認できました.しかし,運用期間で100%利益が上がることを保証することはできません.
それは,株式投資全般に言えることですが,未来は不確定であり,市場は変化し続けるということです.そのため,学習・テスト期間のデータの分布と,運用期間のデータの分布が一致しなければこの解は利用できません.そしてそれを知ることは不可能です.

