
このプログラムの目的
このプログラムはdqn.pyを呼び出し,強化学習を開始させることを目的とします.
また,手法・環境のパラメータやデータセットのパスなどをここで指定します.
work_share
├02_get_stock_price
└03_dqn_learning
├Dockerfile
├docker-compose.yml
└src
├draw_graph
| └draw_tools.py
├enviroment
| └stock_env.py
├reinforcement_learning
| └dqn.py
├result(自動生成)
└experiment01.py (これを作成)実験プログラム
このプログラムは次のようなステップで動作します.
- 実験の結果を格納するディレクトリを生成します.
- パラメータを指定し,それをdqn.pyに渡します.
- このパラメータを実験条件として保存することで,後から再現実験がしやすくなります.
また,今回の実験では次のようなパラメータを設定しました.
'gamma':0.995: gammaは強化学習の割引率です.1.0に近いほど未来の報酬に着目します.0.0に近いほどその時点での即時報酬のみに着目します.'epsilon':0.1: 一定確率でランダムな行動をします.'replay_start_size':1000: リプレイメモリを利用するサイズ.この数だけ経験がたまったら学習を開始します.'update_interval':100: この値のstep毎にQネットワークを更新する.一般に多くの強化学習の問題では1ですが,計算時間の関係上高めの値に設定しました.1に近づくほど計算が遅くなります.'target_update_interval':1000: この値ごとのstep毎にターゲットネットワークを更新します.update_intervalの10倍の値を採用しました.'minibatch_size':512: 更新する際のリプレイメモリから取り出すバッチサイズ.update_intervalよりは大きい値にしたほうが良いです.'resample_interval':10: 銘柄を変更するエピソード間隔.
import pandas as pd
import os
import json
import reinforcement_learning.dqn as dqn
import warnings
warnings.simplefilter('ignore')
def run(args):
with open(f'{args["result_dir"]}/args.json', 'w') as f:
json.dump(args, f, indent=4, ensure_ascii=False)
print('load dataset')
df = pd.read_pickle(args['dataset_path'])
dqn.learning(df, args)
def experiment():
result_dir = f'result/experiment01'
for run_seed in range(1):
result_seed_dir = f'{result_dir}/{run_seed}'
os.makedirs(result_seed_dir, exist_ok=True)
args = {
'result_dir':result_seed_dir,
'dataset_path':'../dataset/learning_dataset.dfpkl',
'init_money':10_000_000,
'trade_cost_func':None,#default
'purchase_max':10,
'money_lower_limit_rate':0.95,
'reward_last_only':True,
'gamma':0.999,
'epsilon':0.1,
'replay_start_size':1000,
'update_interval':100,
'target_update_interval':1000,
'minibatch_size':512,
'n_episodes':10000,
'resample_interval':10,
}
run(args)
if __name__ == '__main__':
experiment()実験結果
報酬を最終的な総資産としたときの結果
nエピソード目の結果を以下に示します.7000エピソード目の結果は,破滅的忘却によってすべての銘柄の利益率が1.01を下回ったため,選択する銘柄無くなり,シミュレーションが行えませんでした.
※乱数の影響があるので,実行毎に結果が変わります.
| n | 学習データ | テストデータ |
|---|---|---|
| 1000 | 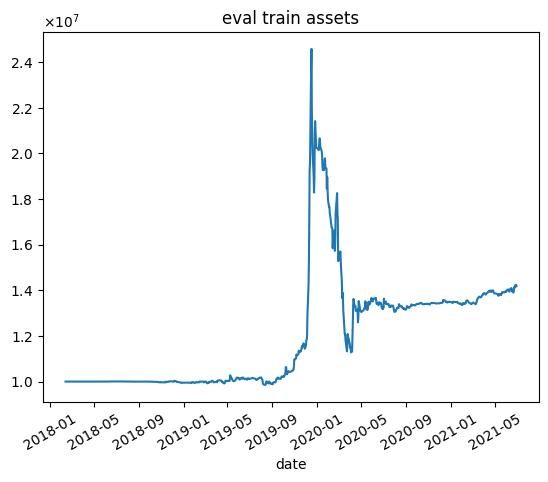 | 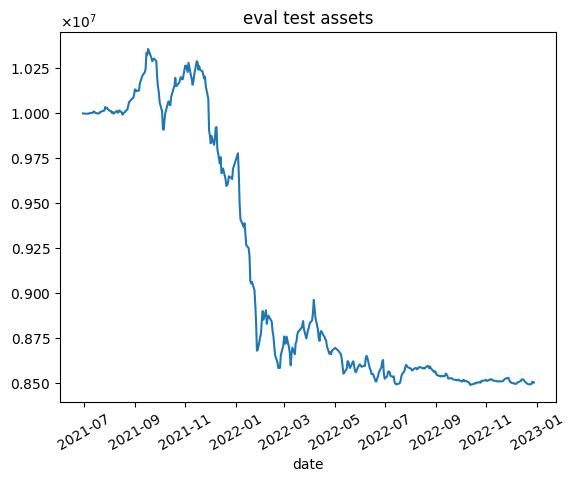 |
| 2000 | 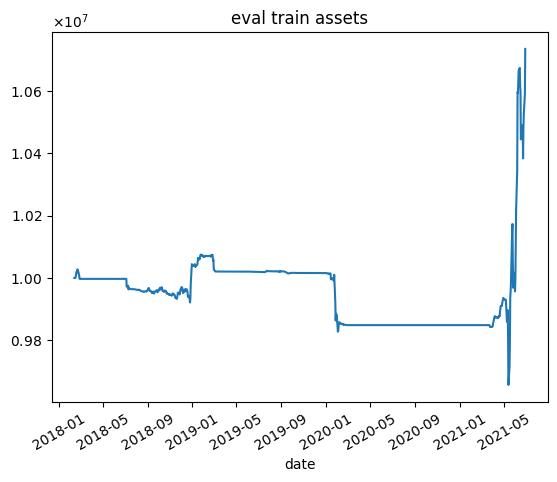 | 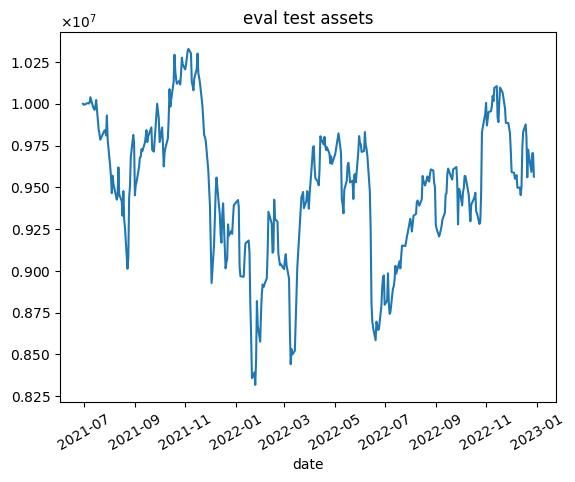 |
| 3000 | 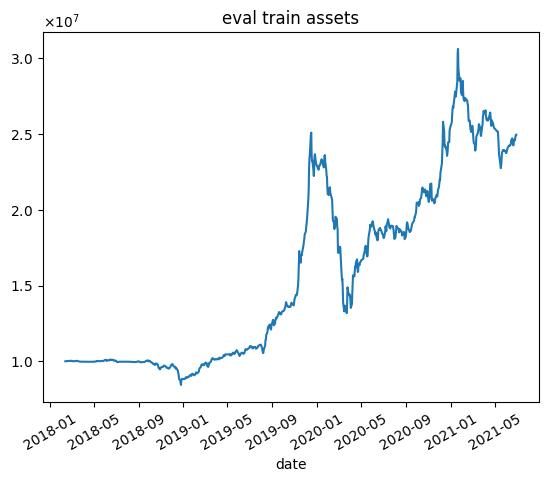 | 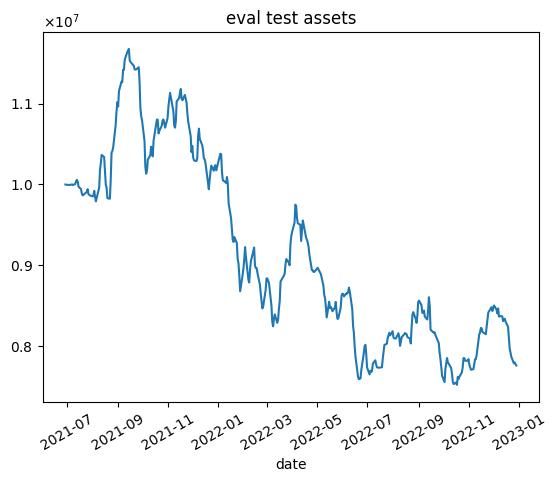 |
| 4000 | 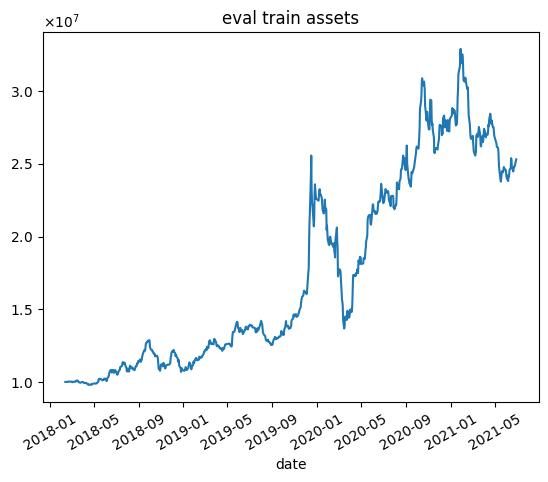 |  |
| 5000 | 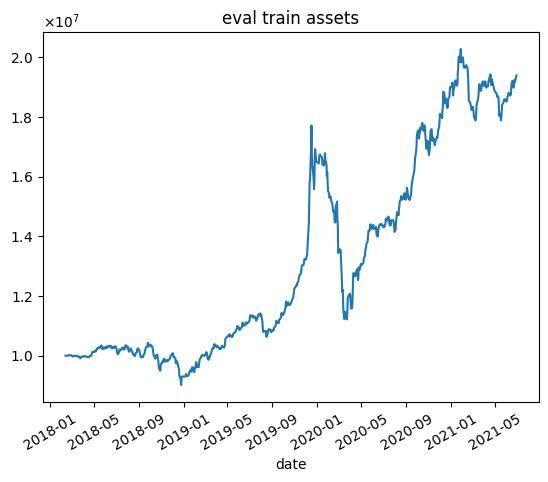 | 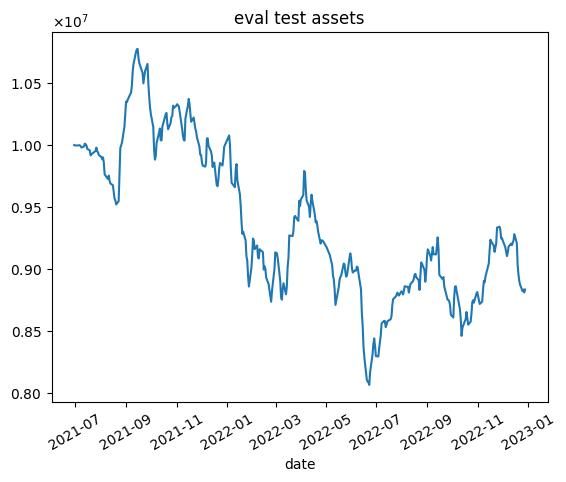 |
| 6000 | 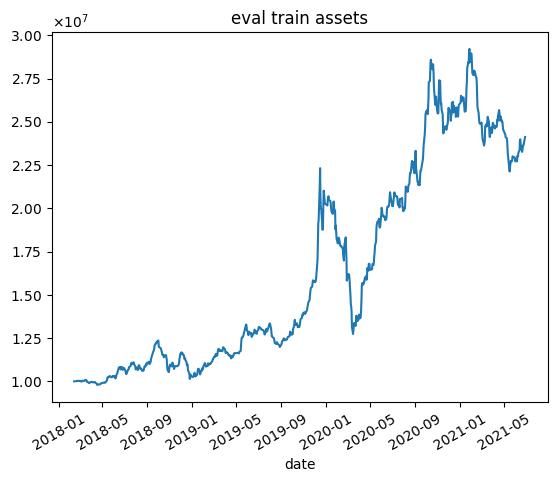 | 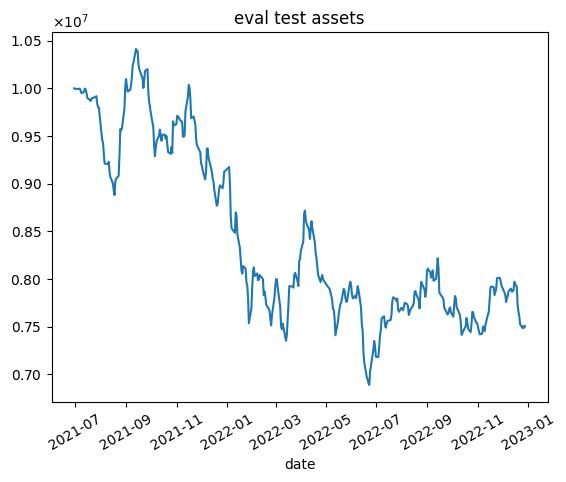 |
| 7000 | None | None |
| 8000 | 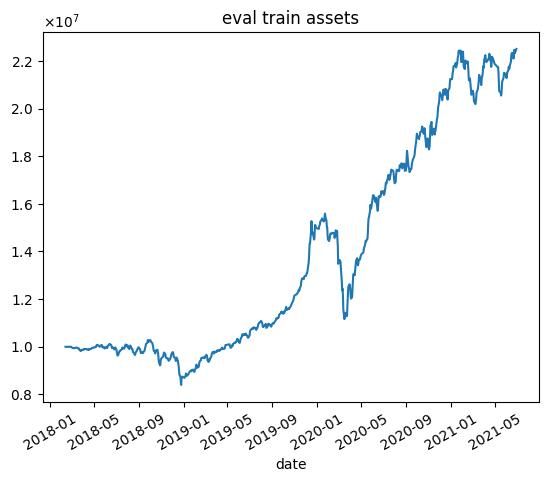 | 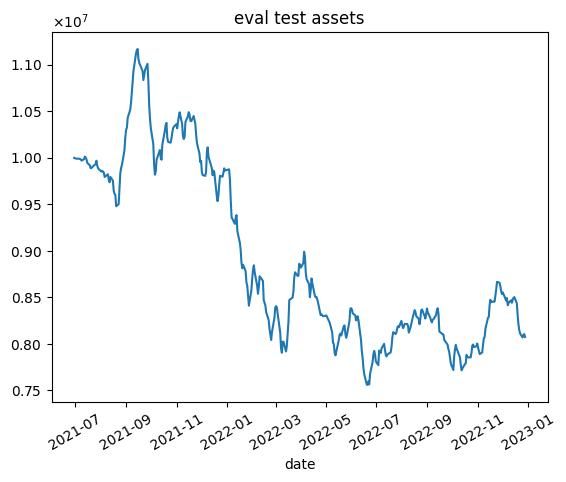 |
| 9000 | 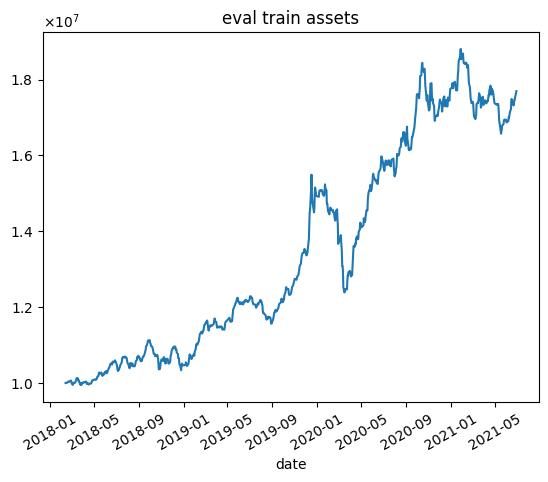 | 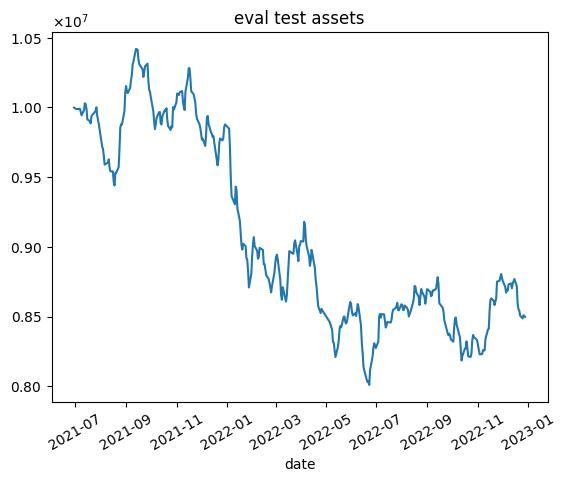 |
| 10000 | 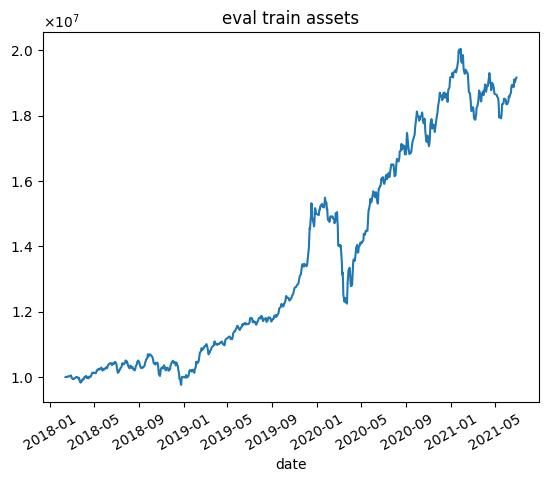 | 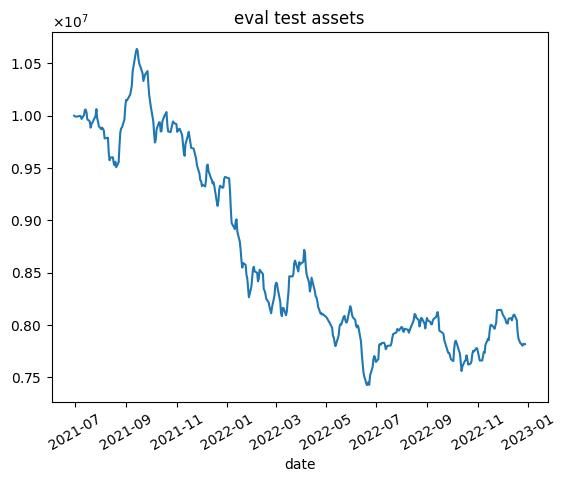 |
これらの結果から次のようなことがわかります.
- 学習データではうまくいっていますが,テストデータではうまくいかない.
- エピソード数を増やしても利益が高くなるわけではない(図中だと3000エピソード目がもっとも学習データで利益が高い)
- 2020年1月頃に下落が始まる.コロナの影響を受けていると思われます.
また,内容量が膨大になってしまうので,この本では書きませんが様々な改良を施しました.
- ハイパーパラメータの試行
- 報酬の試行
- ネットワークの試行
- 環境の試行
しかし,数百時間の試行を行いましたが,テストデータでの利益を上げることはできませんでした.そこで,次章から一から見直していきたいと思います.
