
このプログラムの目的
このプログラムはdqn.pyを呼び出し,強化学習を開始させることを目的とします.
また,手法・環境のパラメータやデータセットのパスなどをここで指定します.
work_share
├06_sampling_dqn_learning
├Dockerfile
├docker-compose.yml
└src
├result(自動生成)
├draw_graph
| └draw_tools.py
├enviroment
| └stock_env.py
├reinforcement_learning
| └dqn.py
└experiment01.py (これを作成)実験プログラム
今回の実験では次のようなパラメータを設定しました.
import pandas as pd
import os
import json
import reinforcement_learning.dqn as dqn
import warnings
warnings.simplefilter('ignore')
def run(args):
with open(f'{args["result_dir"]}/args.json', 'w') as f:
json.dump(args, f, indent=4, ensure_ascii=False)
dqn.learning(args)
def experiment():
dataset_list = [
('../dataset_pred/non_fitting_1.0', 'nf1.0'),
('../dataset_pred/non_fitting_0.5', 'nf0.5'),
('../dataset_pred/non_fitting_0.3', 'nf0.3'),
]
for dataset_dir1, tag1 in dataset_list:
result_dir = f'result/experiment01_{tag1}'
for run_seed in range(1):
result_seed_dir = f'{result_dir}/{run_seed}'
os.makedirs(result_seed_dir, exist_ok=True)
args = {
'result_dir':result_seed_dir,
'dataset_dir1':dataset_dir1,
'dataset_dir2':'../dataset',
'init_money':1_000_000,
'trade_cost_func':'default',
'sampling_t':30,
'reward_last_only':True,
'n_code_select':10,
'sampling_alpha':0.001,
'gamma':0.995,
'epsilon':0.1,
'memory_capacity':1000,
'replay_start_size':100,
'update_interval':1,
'target_update_interval':30,
'minibatch_size':64,
'n_episodes':100000,
'ret_save_interval':1000
}
run(args)
if __name__ == '__main__':
experiment()実験結果
100000エピソード実行しましたが,前回の結果と同様にテスト期間で利益を上げることができませんでした.
また,non_fitting_1.0,non_fitting_0.5,non_fitting_0.3の三つのデータセットについて実行しましたが,あまり違いはありませんでした.
以下適当なエピソードでの総資産推移です.
※乱数の影響があるので,実行毎に結果が変わります.
| n | 学習データ |
|---|---|
| 10000 | 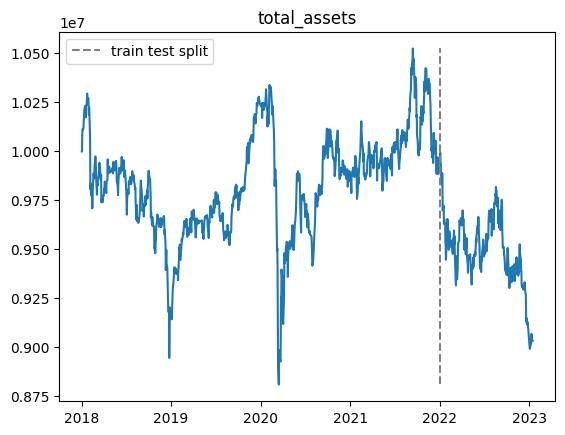 |
| 20000 | 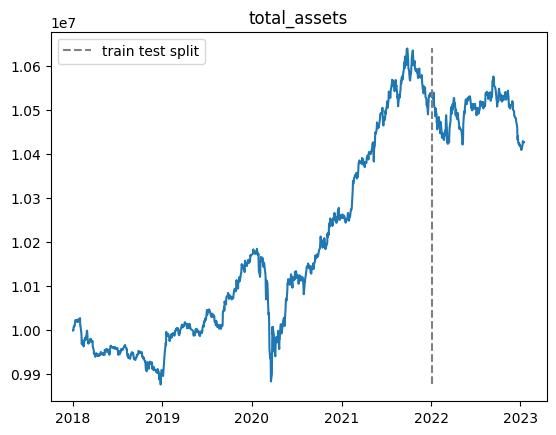 |
| 30000 | 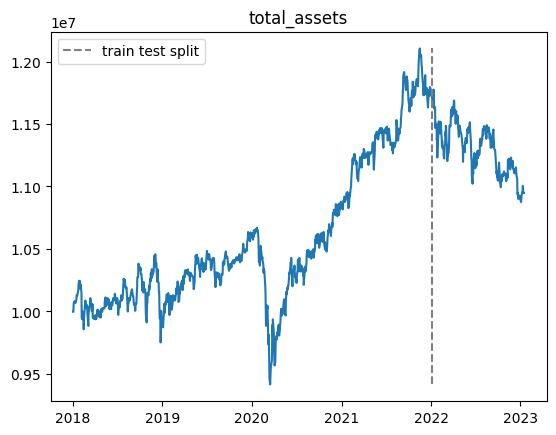 |
| 40000 | 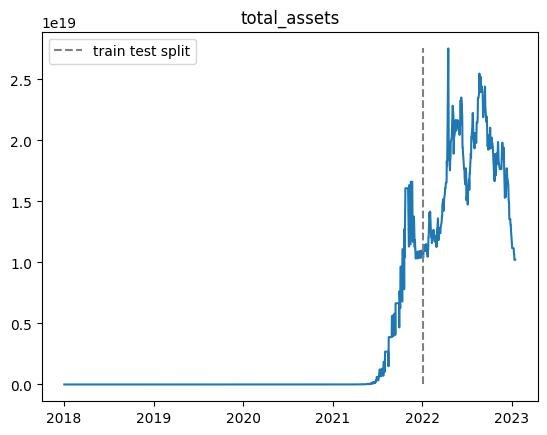 |
| 50000 | 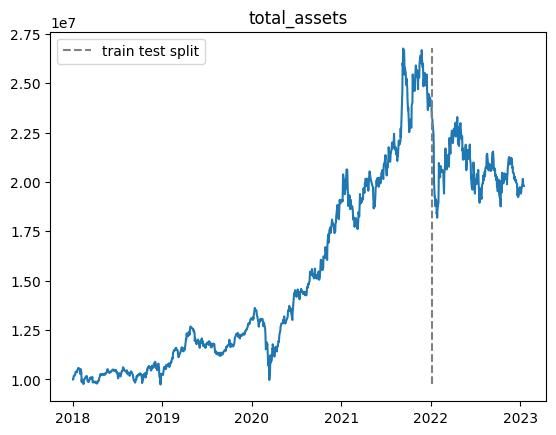 |
| 60000 | 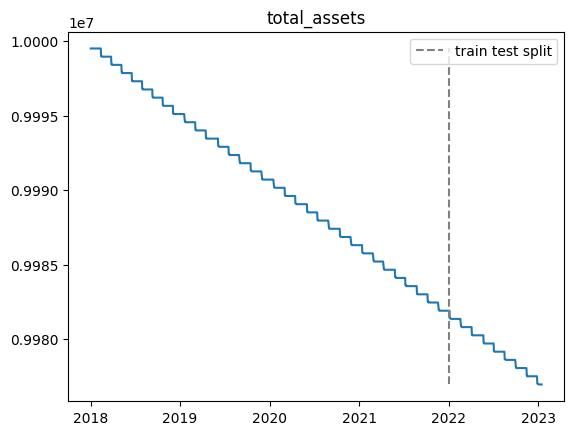 |
| 70000 | 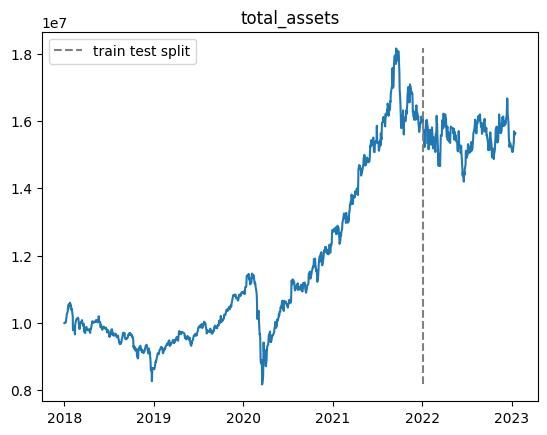 |
| 80000 | 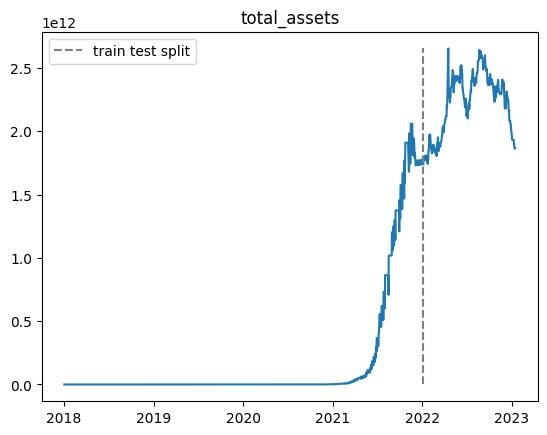 |
| 90000 | 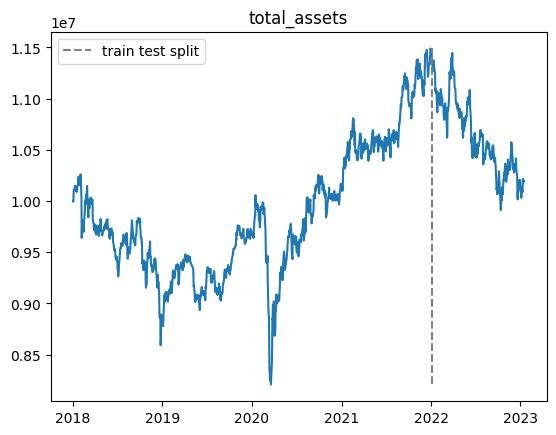 |
| 100000 | 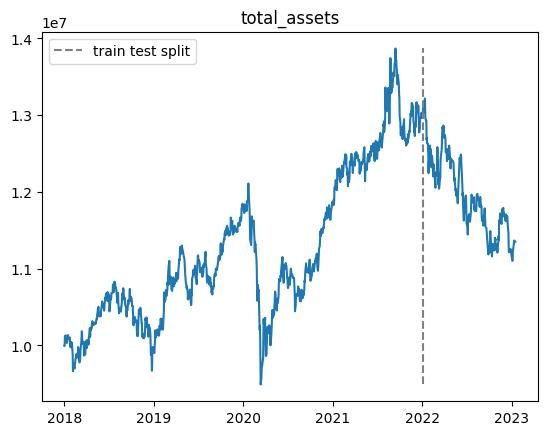 |
まとめ
- 学習期間中では利益が上がるが,テスト期間ではうまくいかない
- 結果がバグってしまう場合がある(40000エピソード目や60000エピソード目)
