
「Section 02-02: rankが1位か否かを当てるBinary Classification」の事前オッズを使う場合です。
特徴量として、前回(Chapter05: 事前オッズを使った予測)求めた事前オッズを追加するだけで、あとは同じです。
学習過程はipynbファイルで行いました。以下はその記録です。
前処理
まず、使いそうなライブラリをインポートします。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from IPython.display import display, Math学習データの読み込み
df = pd.read_pickle('/work/formatted_source_data/analysis_data02.pkl')次に学習データとテストデータ、バリデーションデータの切り分け、および入力データと教師データの切り分けをします。データの正規化もします。
確定オッズにノイズを付与して事前オッズを作り出します。また、オッズは対数を取って、値が飛ばないようにします。
df = df.sort_values(['race_date']).reset_index(drop=True)
not_use_columns = [
'race_date', 'race_id', 'race_grade', 'name', 'jocky_name', 'odds', 'popular', 'rank', 'time', 'prize', 'tansyo_hit', 'tansyo_payout', 'hukusyo_hit', 'hukusyo_payout'
]
not_use_df = df[not_use_columns]
target_df = df.drop(columns=not_use_columns)
lower_noise = np.random.normal(0.0, 0.5, len(df))
upper_noise = np.random.normal(0.8, 0.3, len(df))
p_func = lambda x : -np.exp((-x+1)*0.02) + 1
p = p_func(not_use_df['odds'])
noise = lower_noise*(1-p) + upper_noise*p
not_use_df['noised_odds'] = not_use_df['odds']/np.exp(noise)
target_df['noised_odds_log'] = np.log(not_use_df['noised_odds'])
train_df = target_df.loc[not_use_df['race_date'] < '2020-01-01', :].reset_index(drop=True)
test_df = target_df.loc[not_use_df['race_date'] >= '2020-01-01', :].reset_index(drop=True)
from sklearn.preprocessing import StandardScaler
ped_columns = [col for col in target_df.columns if 'ped' in col]
categoriy_columns = ['place_id', 'race_type', 'weather', 'race_condition', 'horse_count', 'waku', 'horse_number', 'sex', 'age'] + ped_columns
scaler = StandardScaler()
train_X = pd.DataFrame(data=scaler.fit_transform(train_df), columns=train_df.columns)
test_X = pd.DataFrame(data=scaler.transform(test_df), columns=test_df.columns)
for col in categoriy_columns:
train_X.loc[:, col] = train_df.loc[:, col].astype('int64')
test_X.loc[:, col] = test_df.loc[:, col].astype('int64')
train_y = not_use_df.loc[not_use_df['race_date'] < '2020-01-01', 'rank'].reset_index(drop=True)
test_y = not_use_df.loc[not_use_df['race_date'] >= '2020-01-01', 'rank'].reset_index(drop=True)
train_y = (train_y == 1).astype('int64')
test_y = (test_y == 1).astype('int64')学習
学習にはoptunaのlightgbmラッパーを使います。
import optuna.integration.lightgbm as lgb
#import lightgbm as lgb
params = {
'objective': 'binary',
'metric': 'binary_logloss',
'learning_rate': 0.01, # default = 0.1
}
num_round = 10000
from sklearn.model_selection import train_test_split
lgb_train_X, lgb_valid_X, lgb_train_y, lgb_valid_y = train_test_split(train_X, train_y, test_size=0.3)
lgb_train_X = lgb_train_X.reset_index(drop=True)
lgb_valid_X = lgb_valid_X.reset_index(drop=True)
lgb_train_y = lgb_train_y.reset_index(drop=True)
lgb_valid_y = lgb_valid_y.reset_index(drop=True)
lgb_train = lgb.Dataset(lgb_train_X, lgb_train_y)
lgb_eval = lgb.Dataset(lgb_valid_X, lgb_valid_y)
# training
model = lgb.train(params, lgb_train,
num_boost_round=num_round,
valid_sets=[lgb_train, lgb_eval],
valid_names=['train', 'valid'],
callbacks=[lgb.early_stopping(stopping_rounds=10, verbose=1)]
)
accuracy = lambda a, b : np.sum(a==b)/len(a)
lgb_train_pred = (model.predict(lgb_train_X) > 0.5).astype(int)
lgb_valid_pred = (model.predict(lgb_valid_X) > 0.5).astype(int)
test_pred = (model.predict(test_X) > 0.5).astype(int)
print(f'train base acc : {accuracy(np.zeros_like(lgb_train_y), lgb_train_y)}')
print(f'train acc : {accuracy(lgb_train_pred, lgb_train_y)}')
print(f'valid base acc : {accuracy(np.zeros_like(lgb_valid_y), lgb_valid_y)}')
print(f'valid acc : {accuracy(lgb_valid_pred, lgb_valid_y)}')
print(f'test base acc : {accuracy(np.zeros_like(test_y), test_y)}')
print(f'test acc : {accuracy(test_pred, test_y)}')計算過程が色々表示されますが、最終的にはaccuracyが表示されます。
baseと書かれているものは、予測をせずにすべて0ラベルを回答したときのものです。
train base acc : 0.929288220614874
train acc : 0.9297949153186477
valid base acc : 0.9288323756827693
valid acc : 0.9290747440353739
test base acc : 0.9275830455904654
test acc : 0.9276001816421479事前オッズを利用しない場合のテストデータのaccuracyも0.9276だったので、精度向上はしませんでした。
作ったモデルやスカラー変換器を保存しておきます。
import pickle
result = {
'not_use_columns':not_use_columns,
'category_columns':categoriy_columns,
'scaler':scaler,
'model':model
}
with open('/work/models/chapter5_section2_top1_pred_model_result', 'wb') as f:
pickle.dump(result, f)学習結果の解析
予測器が1の(当たるといった)とき本当に当たるか、を計算してみます。
def out_one_accuracy(model, data_X, data_y):
pred = model.predict(data_X) > 0.5
data_y = data_y[pred].to_numpy()
return np.sum(data_y==1)/len(data_y)
print(f'train out 1 acc : {out_one_accuracy(model, lgb_train_X, lgb_train_y)}')
print(f'valid out 1 acc : {out_one_accuracy(model, lgb_valid_X, lgb_valid_y)}')
print(f'test out 1 acc : {out_one_accuracy(model, test_X, test_y)}')結果は次の通りでした。テストデータで50%程度の正答率となります。事前オッズを利用しない場合のテストデータの精度は、0.53333だったので、精度向上はしませんでした。
train out 1 acc : 0.7538071065989848
valid out 1 acc : 0.6145251396648045
test out 1 acc : 0.50625利益の解析
次は利益を計算してみます。
train_tansyo_df = not_use_df.loc[not_use_df['race_date'] < '2020-01-01', ['tansyo_hit', 'tansyo_payout']].reset_index(drop=True)
test_tansyo_df = not_use_df.loc[not_use_df['race_date'] >= '2020-01-01', ['tansyo_hit', 'tansyo_payout']].reset_index(drop=True)
train_tansyo_df = train_tansyo_df.fillna(0)
test_tansyo_df = test_tansyo_df.fillna(0)
train_pred = model.predict(train_X)
test_pred = model.predict(test_X)
def calc_win_money(pred, tansyo_df, th=0.5):
bet = (pred > th).astype(int)
hit = tansyo_df['tansyo_hit'].to_numpy()
payout = tansyo_df['tansyo_payout'].to_numpy()
return_money = np.sum(bet * hit * payout)
bet_money = np.sum(bet)
win_money = return_money - bet_money
return win_money
print(f'train win money :{calc_win_money(train_pred, train_tansyo_df, 0.5)}')
print(f'test win money :{calc_win_money(test_pred, test_tansyo_df, 0.5)}')学習データだと利益が出て、テストだと利益が出ません。
train win money :39.200000000000045
test win money :-34.8賭けるときの、しきい値を0.5から変動させたときに、利益がどのように推移するかを見てみます。基本的にはしきい値が高いほうが確信度が高いため、正答率は高くなります。
train_win_list = []
test_win_list = []
th_list = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
for th in th_list:
train_win_list.append(calc_win_money(train_pred, train_tansyo_df, th))
test_win_list.append(calc_win_money(test_pred, test_tansyo_df, th))
plt.plot(th_list, train_win_list, label='train')
plt.plot(th_list, test_win_list, label='test')
plt.legend()
plt.xlabel('th')
plt.ylabel('win money')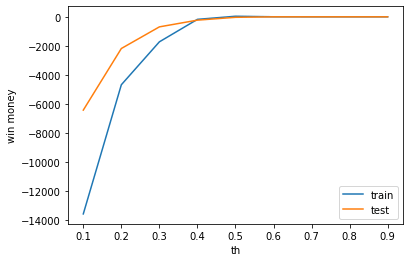
テストデータの利益がでることはありませんでした。
