このプログラムの目的
全銘柄を扱うにあたり,その銘柄を表す特徴量が欲しくなります.もちろん,銘柄コードをOne-hotデータやLabelデータとして扱っても良いのですが,この本では4つの連続的な特徴量として,銘柄を表すことにします.
そのために,全銘柄をクラスタリングし,4つのクラスタに分類します.そして,「各クラスタの中心から,どれだけ離れているか」を銘柄コードの代わりに新たに特徴量として定義します.
work_share
├02_get_stock_price
├Dockerfile
├docker-compose.yml
└src
├dataset_2018-2023
| ├clusterling_dataset_dist.dfpkl (自動生成)
| ├clusterling_dataset_mean.dfpkl (自動生成)
| └original_dataset.dfpkl
├original_data_2018-01-01_2023-01-01
| ├1301.csv
| ├1305.csv
| └...
├time_cluster_result(自動生成)
├get_stock_price.py
├make_original_data.py
├make_time_cluster_dataset.py (これを作成)
└stocks_code.xls使用ライブラリ
時系列クラスタリングはtslearnのTimeSeriesKMeansを利用すると簡単に実装できます.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import tqdm
import os
import pickle
from sklearn.preprocessing import StandardScaler
from tslearn.clustering import TimeSeriesKMeans除外銘柄の検出
まずは,全銘柄を正規化してプロットしてみます.そして,正規化したにも関わらず,値が飛んでしまう銘柄を検出します.
def df_split(df, train_rate):
train_num = int(len(df) * train_rate)
train_df = df.iloc[:train_num, :].reset_index(drop=True)
test_df = df.iloc[train_num:, :].reset_index(drop=True)
return train_df, test_df
def load_dataset(args):
path, train_rate = args['dataset_path'], args['train_rate']
df = pd.read_pickle(path)
df = df.reset_index(drop=True)
train_df, test_df = df_split(df, train_rate)
scaler = StandardScaler()
train_df = pd.DataFrame(data=scaler.fit_transform(train_df), columns=df.columns)
test_df = pd.DataFrame(data=scaler.transform(test_df), columns=df.columns)
train_df = train_df.fillna(0)
test_df = test_df.fillna(0)
plt.cla()
plt.clf()
for col in test_df.columns:
plt.plot(test_df[col])
target = test_df[col]
if np.any(target > 100) or np.any(target < -100):
print(col)
plt.xticks(rotation=30, ha='right')
plt.savefig(f'all_plot.jpg', bbox_inches='tight')
return train_df, test_df, scaler
args = {
'train_rate':0.7,
'dataset_path':f'./{dataset_dir}/original_dataset.dfpkl'
}
load_dataset(args)実行すると,全銘柄の移動線と,大きな外れ値を持つ銘柄コードが出力されます.
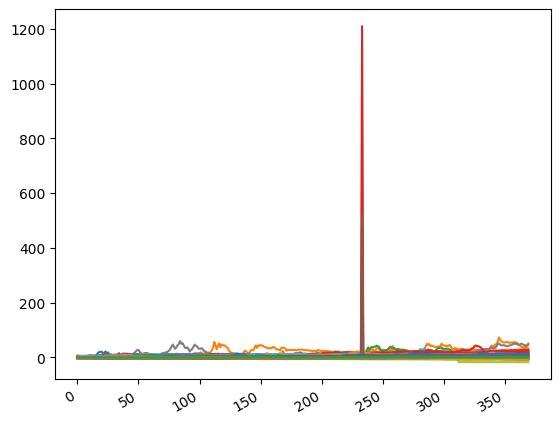
2747
3858
6775
9468この出力された銘柄コードを除いた銘柄のみを新たに出力してみます.
def df_split(df, train_rate):
train_num = int(len(df) * train_rate)
train_df = df.iloc[:train_num, :].reset_index(drop=True)
test_df = df.iloc[train_num:, :].reset_index(drop=True)
return train_df, test_df
def load_dataset(args):
path, train_rate = args['dataset_path'], args['train_rate']
df = pd.read_pickle(path)
df = df.reset_index(drop=True)
df = df.drop(args['drop_codes'], axis=1)
train_df, test_df = df_split(df, train_rate)
scaler = StandardScaler()
train_df = pd.DataFrame(data=scaler.fit_transform(train_df), columns=df.columns)
test_df = pd.DataFrame(data=scaler.transform(test_df), columns=df.columns)
train_df = train_df.fillna(0)
test_df = test_df.fillna(0)
plt.cla()
plt.clf()
for col in test_df.columns:
plt.plot(test_df[col])
target = test_df[col]
if np.any(target > 100) or np.any(target < -100):
print(col)
plt.xticks(rotation=30, ha='right')
plt.savefig(f'all_plot.jpg', bbox_inches='tight')
return train_df, test_df, scaler
args = {
'train_rate':0.7,
'dataset_path':f'./{dataset_dir}/original_dataset.dfpkl',
'drop_codes':['2747', '3858', '6775', '9468']
}
load_dataset(args)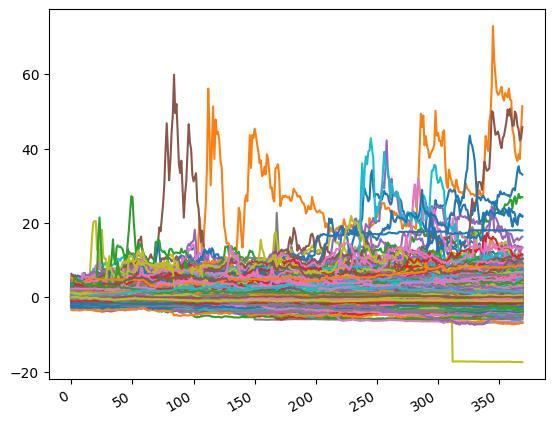
異常なピーク値は無くなりました.ただ,一見まだまだ異常値を示すデータがたくさんあるように見えます.例えば以下のようなものです.
- 正規分布に従うはずなのに,±10を超える値が連続する
- 値が急激に下落・上昇し,その後直線のような値が連続する
一方で,これらの一見異常な振る舞いは,実際の株価データであることも事実です.なので,この本では,上記に挙げた四つの銘柄コードのみを取り除くこととし,他の銘柄データには手を加えません.
時系列クラスタリング
複数の時系列データを教師なし学習によってクラスタリングします.
最も単純な方法は,時系列データを特徴量ベクトルとして解釈し,Kmeanによってクラスタリングするだけです.以下のコードはそれを表しています.
def learning(df, args):
X = df.T.values
params = {
'n_clusters':args['n_clusters'],
'metric':args['metric'],
'max_iter':100,
'random_state':args['random_state'],
'n_jobs':8
}
model = TimeSeriesKMeans(**params)
model.fit(X)
return modelもちろん,単順にKmeansを適用するだけならskleanのKMeansだけで済みます.tsleanのKMeansはmetricとして’euclidean’を指定する場合は一般的なKMeansと変わりありません.
TimeSeriesKMeansのmeatircには’dtw’や’softdtw’が指定できます.筆者の環境ではdtwやsoftdtwは実行時間がかかりすぎたため,実行不可能でした.3500系列×1600点あるので大抵のPCでは実行できないと思いますが,実行できるのでしたらそちらをお勧めします.
クラスタリングした結果
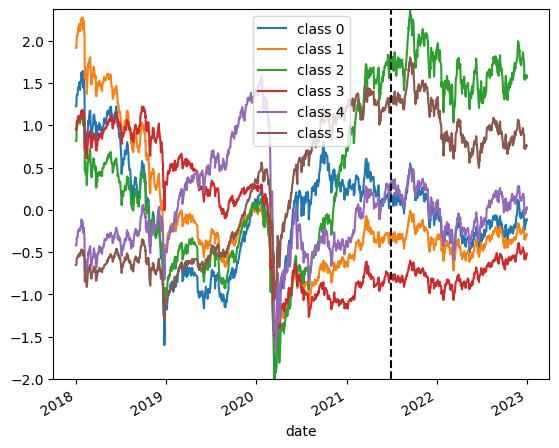
すべての系列データを4つに分類し,それぞれのクラスの平均異動線を見てみます.
def make_timeline_plot(scaler, model, args, save_path):
df = pd.read_pickle(args['dataset_path'])
df = df.reset_index()
date = pd.to_datetime(df['Date'])
df = df.drop('Date', axis=1)
df = df.drop(args['drop_codes'], axis=1)
df.loc[:, :] = scaler.transform(df)
train_num = int(len(df) * args['train_rate'])
_min = 100
_max = -100
labels = model.labels_
plt.cla()
plt.clf()
for c in range(args['n_clusters']):
class_mask = labels == c
class_mean = df.loc[:, class_mask].mean(axis=1)
plt.plot(date, class_mean, label=f'class {c}')
_min = min(_min, class_mean.min())
_max = max(_max, class_mean.max())
plt.vlines(date.iat[train_num], _min, _max, colors='black', linestyles='dashed')
plt.ylim([_min, _max])
plt.xlabel('date')
plt.legend()
plt.xticks(rotation=30, ha='right')
plt.savefig(save_path, bbox_inches='tight')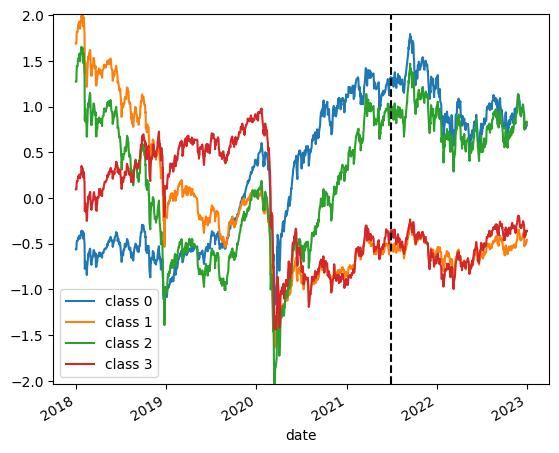
いい感じに分類されていそうですね.あとはこれらの分類情報を元に,各銘柄のユニークな特徴量を算出します.
クラス平均と線銘柄の特徴量
上記の4つのクラス平均線も学習に加えたほうが良いと思うので,保存します.
また,クラスタリングの結果から,各銘柄が各クラスの中心点からどれだけ離れているかを算出します.この4つの特徴量が銘柄を表す特徴となります.より詳細に銘柄を表現したい場合には,分類するクラス数を増やしてください.
def make_dataset(scaler, model, args):
df = pd.read_pickle(args['dataset_path'])
df = df.reset_index()
date = pd.to_datetime(df['Date'])
df = df.drop('Date', axis=1)
df = df.drop(args['drop_codes'], axis=1)
df.loc[:, :] = scaler.transform(df)
train_num = int(len(df) * args['train_rate'])
labels = model.labels_
mean_df = pd.DataFrame()
for c in range(args['n_clusters']):
class_mask = labels == c
class_mean = df.loc[:, class_mask].mean(axis=1)
mean_df[f'class {c}'] = class_mean
mean_df.to_pickle(args['save_dataset_path_mean'])
print(mean_df)
train_num = int(len(df) * args['train_rate'])
dist_df = {}
for col in tqdm.tqdm(df.columns):
col_dist = ((mean_df.loc[:train_num].T - df.loc[:train_num, col].T)**2).sum(axis=1)**0.5
dist_df[col] = col_dist
dist_df = pd.DataFrame(dist_df)
dist_df.to_pickle(args['save_dataset_path_dist'])
print(dist_df)各関数の実行
このページの関数の実行順およびパラメータです.
def run(args):
train_df, test_df, scaler = load_dataset(args)
model = learning(train_df, args)
graph_save_path = f'{args["result_dir"]}/timeline.jpg'
make_timeline_plot(scaler, model, args, graph_save_path)
ret = {
'model':model,
'scaler':scaler
}
ret_save_path = f'{args["result_dir"]}/ret'
with open(ret_save_path, 'wb') as f:
pickle.dump(ret, f)
make_dataset(scaler, model, args)
def experiment():
dataset_dir = 'dataset_2018_2023'
for metric in ['euclidean']:#, 'softdtw']:
result_dir = f'time_cluster_result/experiment_{metric}/'
os.makedirs(result_dir, exist_ok=True)
for n_clusters in [4]:
result_seed_dir = f'{result_dir}/class_{n_clusters}'
os.makedirs(result_seed_dir, exist_ok=True)
args = {
'train_rate':0.7,
'dataset_path':f'./{dataset_dir}/original_dataset.dfpkl',
'n_clusters':n_clusters,
'metric':metric,
'random_state':0,
'result_dir':result_seed_dir,
'save_dataset_path_mean':f'./{dataset_dir}/clusterling_dataset_mean.dfpkl',
'save_dataset_path_dist':f'./{dataset_dir}/clusterling_dataset_dist.dfpkl',
'drop_codes':['2747', '3858', '6775', '9468']
}
run(args)
if __name__ == '__main__':
experiment()ここでは学習データとテストデータ7:3の割合で分割することにしました.また,クラス数を増やしても,クラス平均線が大きく分かれなかったため,4つとしました.
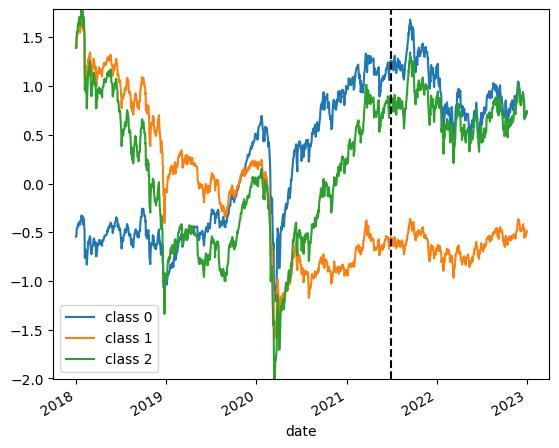
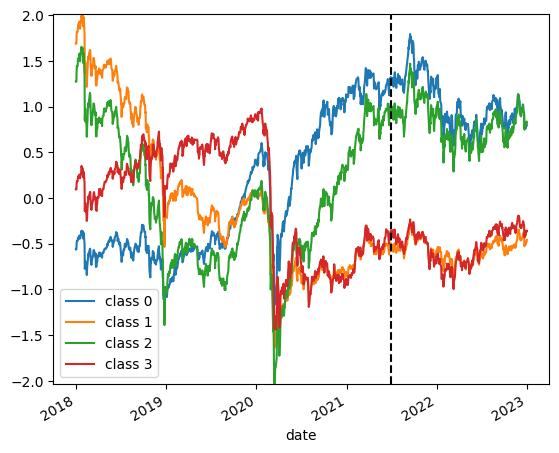
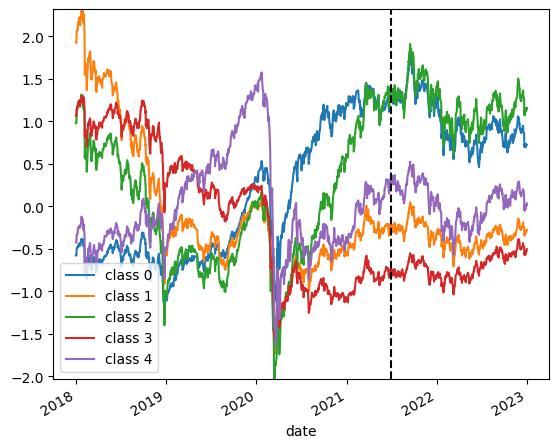
Appendix クラス数を変更した場合
クラス数を変更したときの分類結果の例を載せておきます.クラス数を変更したい場合は参考にしてください.
※KMeansは乱数を基に初期値を決定するので,実行環境・タイミングによって結果が変動します.
3クラス分類の場合
4クラス分類の場合
5クラス分類の場合
6クラス分類の場合