
タイム(走破時間)を予想してみて、利益を算出してみます。
タイムは順位と違って、その馬の実力をより顕著に表す指標になります。
タイムをRegressionで予想し、レース内のタイムが一番早い馬にベットする戦略を考えてみます。
学習過程はipynbファイルで行いました。以下はその記録です。
前処理
基本的にSection02の前処理はほぼ同じです。教師データとなる列名によって、すこしコードをいじる程度の使いまわしです。
まず、使いそうなライブラリをインポートします。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from IPython.display import display, Math学習データの読み込み
df = pd.read_pickle('/work/formatted_source_data/analysis_data02.pkl')
dfChapter1でもやりましたが、タイムデータ(文字列)を秒数(float)へと変換します。
def time_str_to_sec_float(time_str):
sp_df = time_str.str.split(':', expand=True)
sp_df.columns = ['min', 'sec']
sp_df = sp_df.astype('float64')
return sp_df['min']*60 + sp_df['sec']
df['time_sec'] = time_str_to_sec_float(df['time'])次に学習データとテストデータの切り分け、および入力データと教師データの切り分けをします。データの正規化もします。not_use_columnsに新しく追加したtime_secを追記するのを忘れないようにしてください
df = df.sort_values(['race_date']).reset_index(drop=True)
not_use_columns = [
'race_date', 'race_id', 'race_grade', 'name', 'jocky_name', 'odds', 'popular', 'rank', 'time', 'prize', 'tansyo_hit', 'tansyo_payout', 'hukusyo_hit', 'hukusyo_payout', 'time_sec'
]
not_use_df = df[not_use_columns]
target_df = df.drop(columns=not_use_columns)
train_df = target_df.loc[not_use_df['race_date'] < '2020-01-01', :].reset_index(drop=True)
test_df = target_df.loc[not_use_df['race_date'] >= '2020-01-01', :].reset_index(drop=True)
from sklearn.preprocessing import StandardScaler
categoriy_columns = ['place_id', 'race_type', 'weather', 'race_condition', 'horse_count', 'waku', 'horse_number', 'sex', 'age']
scaler = StandardScaler()
train_X = pd.DataFrame(data=scaler.fit_transform(train_df), columns=train_df.columns)
test_X = pd.DataFrame(data=scaler.transform(test_df), columns=test_df.columns)
for col in categoriy_columns:
train_X.loc[:, col] = train_df.loc[:, col].astype('int64')
test_X.loc[:, col] = test_df.loc[:, col].astype('int64')
train_y = not_use_df.loc[not_use_df['race_date'] < '2020-01-01', 'time_sec'].reset_index(drop=True)
test_y = not_use_df.loc[not_use_df['race_date'] >= '2020-01-01', 'time_sec'].reset_index(drop=True)学習
学習はクラス分類ではないので、objectiveをregressionにします。
import optuna.integration.lightgbm as lgb
#import lightgbm as lgb
params = {
'objective': 'regression',
'metric': 'rmse',
'learning_rate': 0.01, # default = 0.1
}
num_round = 10000
from sklearn.model_selection import train_test_split
lgb_train_X, lgb_valid_X, lgb_train_y, lgb_valid_y = train_test_split(train_X, train_y, test_size=0.3)
lgb_train_X = lgb_train_X.reset_index(drop=True)
lgb_valid_X = lgb_valid_X.reset_index(drop=True)
lgb_train_y = lgb_train_y.reset_index(drop=True)
lgb_valid_y = lgb_valid_y.reset_index(drop=True)
lgb_train = lgb.Dataset(lgb_train_X, lgb_train_y)
lgb_eval = lgb.Dataset(lgb_valid_X, lgb_valid_y)
# training
model = lgb.train(params, lgb_train,
num_boost_round=num_round,
valid_sets=[lgb_train, lgb_eval],
valid_names=['train', 'valid'],
callbacks=[lgb.early_stopping(stopping_rounds=10, verbose=1)]
)
rmse = lambda a, b : np.mean(np.sqrt((a-b))**2)
lgb_train_pred = model.predict(lgb_train_X)
lgb_valid_pred = model.predict(lgb_valid_X)
test_pred = model.predict(test_X)数時間待つと結果が出ます。
計算過程が色々表示されますが、最終的にはRMSE(Root Mean Square Error)が表示されます。
baseと書かれているものは、予測をせずにすべて定数値(予測値の平均値)を回答したときのものです。
chapter1でも触れましたが、タイムは距離や賞金等の要因をかなり強く受ける値です。ですから、baseの値(予測しない)よりもかなりよく予測できているかもしれません。
しかし、「ある距離のある賞金のタイム」が予測できることと、「レース内での馬の速さ」が予測できることは別なので、注意が必要です。
train base rmse : 20.673776402372486
train rmse : 0.5230136265811757
valid base rmse : 20.74870923407973
valid rmse : 0.8458330049221564
test base rmse : 21.355604420795295
test rmse : 1.1754337891003015作ったモデルやスカラー変換器を保存しておきます。
import pickle
result = {
'not_use_columns':not_use_columns,
'category_columns':categoriy_columns,
'scaler':scaler,
'model':model
}
with open('/work/models/chapter2_section4_time_pred_model_result', 'wb') as f:
pickle.dump(result, f)学習結果の解析
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(131)
plt.scatter(lgb_train_pred, lgb_train_y)
plt.title('train')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(132)
plt.scatter(lgb_valid_pred, lgb_valid_y)
plt.title('valid')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(133)
plt.scatter(test_pred, test_y)
plt.title('test')
plt.xlabel('pred')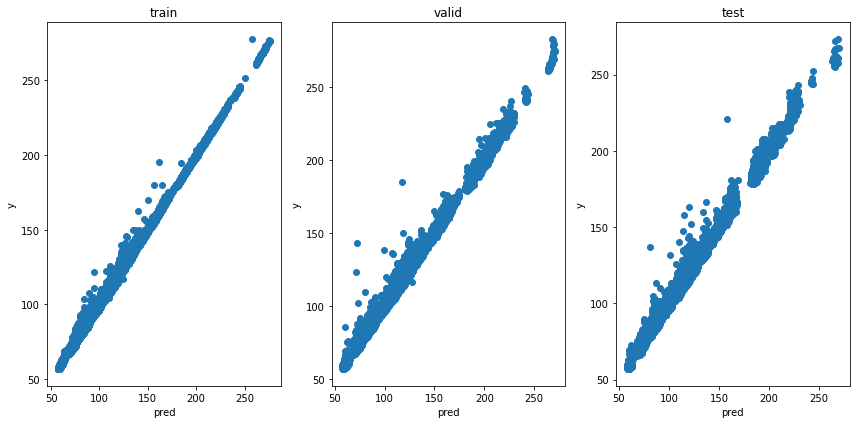
キレイな正の相関が見られます。あとは、馬ごとの速さも正しく予測できているとよいのですが。
利益の解析
一度、予測したデータを見てみます。
train_tansyo_df = not_use_df.loc[not_use_df['race_date'] < '2020-01-01', ['race_id', 'tansyo_hit', 'tansyo_payout']].reset_index(drop=True)
test_tansyo_df = not_use_df.loc[not_use_df['race_date'] >= '2020-01-01', ['race_id', 'tansyo_hit', 'tansyo_payout']].reset_index(drop=True)
train_tansyo_df = train_tansyo_df.fillna(0)
test_tansyo_df = test_tansyo_df.fillna(0)
train_tansyo_df['pred_time'] = model.predict(train_X)
test_tansyo_df['pred_time'] = model.predict(test_X)
train_tansyo_df同じレースIDでも、タイムが違うことがわかります。つまり、馬ごとに差分がでていますから、これが正しければ、利益が出るはずです。
race_id tansyo_hit tansyo_payout pred_time
0 32317 0 0.0 74.344304
1 32314 0 0.0 119.528209
2 32314 0 0.0 118.745110
3 32314 0 0.0 119.695404
4 32314 0 0.0 117.627601
... ... ... ... ...
563874 42820 0 0.0 72.580538
563875 42820 0 0.0 73.260990
563876 42820 0 0.0 72.407410
563877 42820 0 0.0 72.394004
563878 42820 0 0.0 72.441913
563879 rows × 4 columnsレースごとの利益を算出し、合算してみます。
レースごとに区分すると、計算速度が遅いので、joblibを使います。一度保存して、プロセス毎に読み込むほうが、メモリ消費もなく、コピーの手間もかからないので、結果的に早かったりします。
import joblib
def process(race_id):
temp_df = pd.read_pickle('/work/temp/temp_df.pkl')
mask = temp_df['race_id'] == race_id
race_df = temp_df.loc[mask, :].reset_index(drop=True)
win_money = -1
bet_idx = race_df['pred_time'].idxmin()
if race_df.at[bet_idx, 'tansyo_hit'] == 1:
win_money += race_df.at[bet_idx, 'tansyo_payout']
return win_money
train_tansyo_df.to_pickle('/work/temp/temp_df.pkl')
race_ids = train_tansyo_df['race_id'].unique()
print(f'task num : {len(race_ids)}')
win_list = joblib.Parallel(n_jobs=-1, verbose=1)([joblib.delayed(process)(race_id) for race_id in race_ids])
print(f'train win money :{sum(win_list)}')
test_tansyo_df.to_pickle('/work/temp/temp_df.pkl')
race_ids = test_tansyo_df['race_id'].unique()
print(f'task num : {len(race_ids)}')
win_list = joblib.Parallel(n_jobs=-1, verbose=1)([joblib.delayed(process)(race_id) for race_id in race_ids])
print(f'test win money :{sum(win_list)}')数分待つと結果が出ます。
学習データでは利益がでましたが、テストデータでは損失が大きくなってしまいました。
つまり、今までと変わらない結果です。
train win money :30451.999999999927
test win money :-2229.7999999999993