
今日はDocker環境下でText to Videoを動かせる環境構築する話をしたいと思います。
また、筆者のサーバーの環境ではGPUメモリは11GBなため、それでも動くように調整します。
環境構築
Dev-Containerで構築しました。以下、ディレクトリ構成です。
hugging_face_diffusers_test
├── .devcontainer
| ├── Dockerfile
| ├── devcontainer.json
| └── docker-compose.yml
└── animate_diff_lighting_test.pyDockerfile
imageはnvidia/cuda:12.1.0-runtime-ubuntu20.04をベースにしました。
これは、huggingfaceのdiffusersのDockerfileを参考にしたためです。

基本的にこれをベースに作りました。
FROM nvidia/cuda:12.1.0-runtime-ubuntu20.04
ARG USERNAME=vscode
ARG USER_UID=1000
ARG USER_GID=$USER_UID
ENV LANG ja_JP.UTF-8
ENV LANGUAGE ja_JP:ja
ENV LC_ALL ja_JP.UTF-8
ENV TZ JST-9
ENV TERM xterm
RUN apt-get update \
&& groupadd --gid $USER_GID $USERNAME \
&& useradd -s /bin/bash --uid $USER_UID --gid $USER_GID -m $USERNAME \
&& apt-get install -y sudo \
&& echo $USERNAME ALL=\(root\) NOPASSWD:ALL > /etc/sudoers.d/$USERNAME \
&& chmod 0440 /etc/sudoers.d/$USERNAME \
&& apt-get -y install locales \
&& localedef -f UTF-8 -i ja_JP ja_JP.UTF-8
RUN apt-get -y update \
&& apt-get install -y software-properties-common \
&& add-apt-repository ppa:deadsnakes/ppa
RUN apt install -y bash \
build-essential \
git \
git-lfs \
curl \
ca-certificates \
libsndfile1-dev \
libgl1 \
python3.10 \
python3-pip \
python3.10-venv && \
rm -rf /var/lib/apt/lists
# make sure to use venv
RUN python3.10 -m venv /opt/venv
ENV PATH="/opt/venv/bin:$PATH"
# pre-install the heavy dependencies (these can later be overridden by the deps from setup.py)
RUN python3.10 -m pip install --no-cache-dir --upgrade pip uv==0.1.11 && \
python3.10 -m uv pip install --no-cache-dir \
torch \
torchvision \
torchaudio \
invisible_watermark && \
python3.10 -m pip install --no-cache-dir \
accelerate \
datasets \
hf-doc-builder \
huggingface-hub \
Jinja2 \
librosa \
numpy \
scipy \
tensorboard \
transformers \
pytorch-lightning
RUN pip install --upgrade diffusers[torch]
RUN pip install xformers
ENV HF_HOME /work/.cache/huggingface
ENV TORCH_HOME /work/.cache/torchvisiondiffusersとxformersを入れます。xformersは計算を軽量・高速にする手法で、特に理由がないなら、入れといて損はないです。
また、モデルをhugginfaceからダウンロードするときのキャッシュディレクトリを、作業するディレクトリの中に設定することをオススメします(HF_HOMEとTORCH_HOME)。デフォルトだと、コンテナ内のルートにキャッシュディレクトリが作られるので、リビルドするとモデルが消えます。
devcontainer.json
名前とサービス名を決定してください。また、必要な拡張機能を入れてください。筆者は、pythonの拡張機能とjupyter notebookの拡張機能をいつも入れています。
{
"name": "hugging-face-diffusers-test",
"service": "hugging-face-diffusers-test",
"dockerComposeFile": "docker-compose.yml",
"remoteUser": "vscode",
"workspaceFolder": "/work",
"customizations": {
"vscode": {
"extensions": [
"ms-python.python",
"ms-toolsai.jupyter"
]
}
}
}docker-compose.yml
設定したサービス名を間違えないでください。
また、GPUを使うので、GPUが使えるようにdeployを書き足します。
version: '3'
services:
hugging-face-diffusers-test:
container_name: 'hugging-face-diffusers-test-container'
hostname: 'hugging-face-diffusers-test-container'
build: .
restart: always
working_dir: '/work'
tty: true
volumes:
- type: bind
source: ..
target: /work
ulimits:
memlock: -1
stack: -1
shm_size: '10gb'
deploy:
resources:
reservations:
devices:
- capabilities: [gpu]実行
今回はanimateDiff-lightingを試したいと思います。とても高速に生成できる、執筆時点で最も勢いのあるモデルです。

huggingfaceにあるDiffusers Usageを参考にテストプログラムを書きます。
import torch
from diffusers import AnimateDiffPipeline, MotionAdapter, EulerDiscreteScheduler
from diffusers.utils import export_to_gif
from huggingface_hub import hf_hub_download
from safetensors.torch import load_file
device = "cuda"
dtype = torch.float16
step = 4 # Options: [1,2,4,8]
repo = "ByteDance/AnimateDiff-Lightning"
ckpt = f"animatediff_lightning_{step}step_diffusers.safetensors"
base = "emilianJR/epiCRealism" # Choose to your favorite base model.
adapter = MotionAdapter().to(device, dtype)
adapter.load_state_dict(load_file(hf_hub_download(repo ,ckpt), device=device))
pipe = AnimateDiffPipeline.from_pretrained(base, motion_adapter=adapter, torch_dtype=dtype).to(device)
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config, timestep_spacing="trailing", beta_schedule="linear")
output = pipe(prompt="A girl smiling", guidance_scale=1.0, num_inference_steps=step)
export_to_gif(output.frames[0], "animation.gif")実行すると、おそらくハイスペックのGPU(Memory 20GB~)を持っていないと、「CUDA out of memory」のエラーが出てしまいます。
少ないGPUメモリで動かす方法について調べてみると、次のような記事がありました。

これを参考に、プログラムを書き直します。
import torch
from diffusers import AnimateDiffPipeline, MotionAdapter, EulerDiscreteScheduler
from diffusers.utils import export_to_gif
from huggingface_hub import hf_hub_download
from safetensors.torch import load_file
device = "cuda"
dtype = torch.float16
step = 4 # Options: [1,2,4,8]
repo = "ByteDance/AnimateDiff-Lightning"
ckpt = f"animatediff_lightning_{step}step_diffusers.safetensors"
base = "emilianJR/epiCRealism" # Choose to your favorite base model.
adapter = MotionAdapter().to(device, dtype)
adapter.load_state_dict(load_file(hf_hub_download(repo ,ckpt), device=device))
pipe = AnimateDiffPipeline.from_pretrained(base, motion_adapter=adapter, torch_dtype=dtype).to(device)
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config, timestep_spacing="trailing", beta_schedule="linear")
pipe.enable_xformers_memory_efficient_attention()
pipe.enable_attention_slicing()
pipe.enable_vae_slicing()
#pipe.enable_sequential_cpu_offload()
with torch.autocast('cuda'):
output = pipe(prompt="A girl smiling", guidance_scale=1.0, num_inference_steps=step)
export_to_gif(output.frames[0], "animation.gif")pipe.enable_sequential_cpu_offloadをつけると、更に少ないメモリで動かせます。しかし、今回は必要ありませんでした。
実行すると初回はモデルのダウンロードがあり、その後生成が始まります。
実行している最中に別のターミナルで、GPUメモリの使用量を調べてみました。
Mon Jun 3 11:11:23 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.161.08 Driver Version: 535.161.08 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce GTX 1080 Ti Off | 00000000:01:00.0 Off | N/A |
| 24% 54C P2 197W / 250W | 7316MiB / 11264MiB | 96% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
+---------------------------------------------------------------------------------------+7.3GBで動いています。これなら、ミドルレンジのGPUでも十分に動かせそうです。
実行すると、次のようなgifファイルが生成されます。

ちゃんと、アニメーションが生成されています。
検証
いくつかの検証をしてみたいと思います。
長いアニメーション
長いアニメーションは生成できるのでしょうか?gifのフレーム数はpipeに渡すnum_framesパラメータで決定できます。
pipe(prompt="A girl walking", guidance_scale=1.0, num_inference_steps=step, num_frames=100)実行するとエラーがでました。
File "/opt/venv/lib/python3.10/site-packages/diffusers/models/embeddings.py", line 308, in forward
x = x + self.pe[:, :seq_length]
RuntimeError: The size of tensor a (100) must match the size of tensor b (32) at non-singleton dimension 1どうやら32framesまでしか対応できないみたいです。num_frames=32にして試してみます。
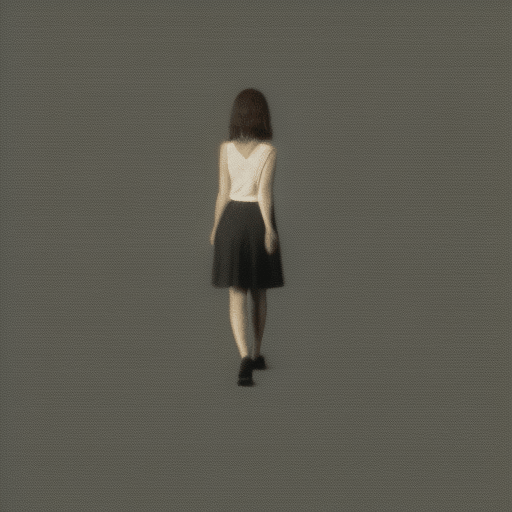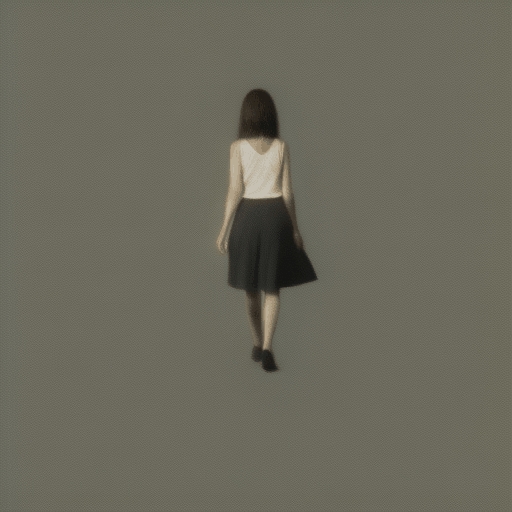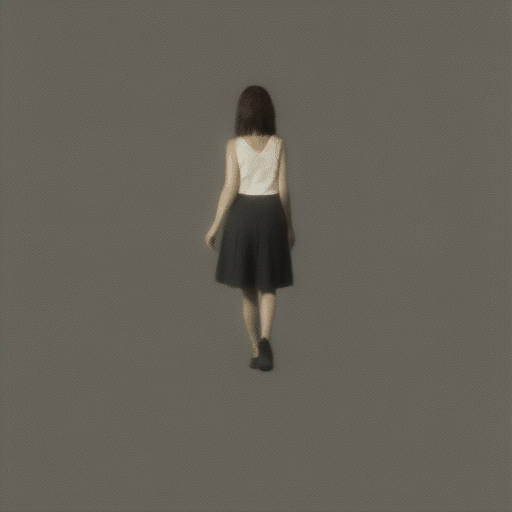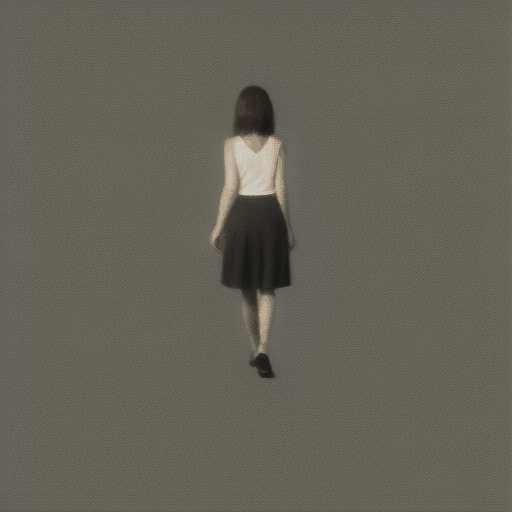
歩いている?すこし、ホラーチックな画像になってしまいました。おそらく最初の生成画像よりも4倍近く長いので、生成自体はできるみたいですが、画像の整合性は崩れるみたいです。
まとめ
今回は、huggingfaceのdiffusersを使って簡単にdocker環境でtext2videoをやってみました。
構築エラーもなく、すんなりとアニメーションが生成できて良かったです。
しかし、長い動画は作れなそうなので、今後検証してみたいと思います。

