
はじめに
※この記事では合計特殊出生率を出生率と呼びます
私は政治家でもなければ社会学者でもなく、政策や時事には関心が向かない一般ニートです。
そんな私の耳に、出生率の話題が入ってきたのはつい最近のことです。
初めは、「東京の出生率が過去最低だった」という話でした。その後、「出生率は転入・転出を考慮していない」という話が入ってきました。
転入と転出を考慮した出生率
なんでこんな話が持ち上がるかというと、東京の出生率が47都道府県で最低値だったからです。東京は人口ブラックホールなんて言葉が、ネット上では飛び交っています。
しかし、これに反論する形で、「出生率は転入・転出を考慮していない」という話が上がってくるのです。
確かに、合計特殊出生率の計算式は、生まれた子供と産んだ人数を元に算出されます。ですから、「子供を産まない人」=「働く女性」が東京へ進出してくるため、東京の出生率が下がり、地方の出生率があがるという論法は一見すると成り立ちます。
つまり、東京は「継続的に地方から働く女性が流入してくるため、出生率が低くなるのは当然だ」という話です。
ですが、この話のソース(元となるデータ)は調べてもでてきません。上記の論法は成り立つように思えますが、データとしてこれを確認したくなるのが、データサイエンティストです。
そこで、今回の記事では女性の転入と転出を考慮して、各都道府県の出生率を再計算してみます。
データ収集元は統計局
データは統計局から引っ張ってきました。

pythonからはAPI経由でデータを持ってこれます。これは前回の記事で話しました。

これを元に、データを収集し、出生率を再計算してみます。
プログラムはipynb形式のjupyter notebookで行いました。再現したい方は前回の記事の実行環境を整えるか、Google Colaboratoryを利用してください。
データの収集
まずは、基になるデータを引っ張ってきます。
初めに、データを引っ張ってくるのに使うライブラリと、e-statのappidを設定します。appidは統計局にユーザー登録すれば、誰でも発行できます
import requests
import pandas as pd
import io
api_appid = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxx'次に、データを引っ張ってくる関数を用意します。今回はCSV形式でデータを引っ張ってきて、pandasのDataFrameへと変換します。
また、e-statのAPIは10万件以上引っ張ってこれないので、10万件を超えた場合には続きをダウンロードするようにします。
base_url = 'https://api.e-stat.go.jp/rest/3.0/app/getSimpleStatsData?'
def get_data(params: dict) -> dict:
url = base_url + '&'.join([f'{key}={value}' for key, value in params.items()])
print(url)
return requests.get(url)
def get_df(statsDataId):
params = {
'appId':api_appid,
'lang':'J',
'statsDataId':statsDataId,
}
response = get_data(params)
s = response.text.find('"VALUE"') + len('"Value"\n')
f = io.StringIO(response.content.decode('utf-8')[s:])
df = pd.read_csv(f)
next_key_s = response.text.find('"NEXT_KEY"')
next_pos = 100001
while next_key_s != -1:
params['startPosition'] = next_pos
response = get_data(params)
s = response.text.find('"VALUE"') + len('"Value"\n')
f = io.StringIO(response.content.decode('utf-8')[s:])
df = pd.concat([df, pd.read_csv(f)], axis=0)
next_key_s = response.text.find('"NEXT_KEY"')
next_pos += 100000
return df.reset_index(drop=True)統計局の表データを調べて、表の固有IDを見つけ、それを指定することで表データをダウンロードできます。
今回は、次の表データを元にしました。
- 人口動態調査 人口動態統計 確定数 出生 都道府県別にみた年次別合計特殊出生率
- 人口動態調査 人口動態統計 確定数 出生 出生数,都道府県(特別区-指定都市再掲)・性・母の年齢(5歳階級)別
- 人口推計 各年10月1日現在人口 平成27年国勢調査基準 統計表 都道府県,年齢(5歳階級),男女別人口-総人口,日本人人口
- 人口推計 各年10月1日現在人口 令和2年国勢調査基準 統計表 都道府県,年齢(5歳階級),男女別人口-総人口,日本人人口
- 住民基本台帳人口移動報告 年報(実数) 2020年~ 年齢(5歳階級),男女別他都道府県からの転入者数,他都道府県への転出者数,転入超過数-全国,都道府県,3大都市圏(東京圏,名古屋圏,大阪圏),21大都市(移動者,日本人移動者,外国人移動者)(2020年~)
- 住民基本台帳人口移動報告 年報(基本集計)2019年以前 年齢(5歳階級),男女別転入者数,転出者数及び転入超過数(2014年~)
統計局さん…表を統一してほしいです。というか表データをAPIで取ってくるために、表データを探しに行く手間、なんとかなりませんか。
転入転出の表データは、2020~と2014~で形式が若干違うので、素直にconcatできません。ですので、分けて保持します(あとで形式を合わせてconcatします)。
born_rate_origin_df = get_df('0003411598')
born_num_origin_df = get_df('0003411631')
population_origin_df = pd.concat([get_df('0003459027'), get_df('0003448237')], axis=0)
move_num_origin_df_A = get_df('0003420482')
move_num_origin_df_B = get_df('0003103425')これらの表データを整形して、扱うデータだけを抽出します。
データの修正と抽出
ここでは主に、年を数値へ変換することや、必要なカラムだけを残すこと、カラム名を修正することを行います。
出生率
まずは、出生率。これは出生率の計算の検算のために取ってきました。
born_rate_origin_df['year'] = born_rate_origin_df['時間軸(年次)'].str[:-1].astype(int)
mask = born_rate_origin_df['都道府県'] != '全国'
mask = mask & (born_rate_origin_df['year'] >= 2015)
use_columns = ['都道府県', 'value', 'year']
born_rate_df = born_rate_origin_df.loc[mask, use_columns].reset_index(drop=True)
born_rate_df = born_rate_df.rename(columns={'value':'出生率'})
born_rate_df47都道府県の8年間のデータなので、376個あります。
出生数
出生数の表データを確認すると、かなり不要なデータが含まれています。
なので、条件でマスクして、必要なデータだけを残します。ここでは以下の条件でデータをマスクしました
- 地区が47都道府県である
- 生まれた子どもの性別が総数(男女)のデータをとる
- 母の年齢が総数となるデータはとらない
- 母の年齢が不詳となるデータはとらない
- 母の年齢が14歳以下となるデータはとらない
- 母の年齢が50歳以上となるデータはとらない
また、出産数が0の場合にのセルが、数値ではないので、これも0へと変換しました。
area_names = '|'.join(born_rate_df['都道府県'])
born_num_origin_df['year'] = born_num_origin_df['時間軸(年次)'].str[:-1].astype(int)
mask = born_num_origin_df['都道府県(特別区-指定都市再掲)'].str.contains(area_names)
mask = mask & (born_num_origin_df['性別'] == '総数')
mask = mask & (born_num_origin_df['母の年齢(5歳階級)'] != '総数')
mask = mask & (born_num_origin_df['母の年齢(5歳階級)'] != '不詳')
mask = mask & (born_num_origin_df['母の年齢(5歳階級)'] != '14歳以下')
mask = mask & (born_num_origin_df['母の年齢(5歳階級)'] != '50歳以上')
use_columns = ['母の年齢(5歳階級)', '都道府県(特別区-指定都市再掲)', 'value', 'year']
born_num_df = born_num_origin_df.loc[mask, use_columns].reset_index(drop=True)
born_num_df['value'] = born_num_df['value'].str.extract(r'(\d+)').astype(float)
born_num_df['value'] = born_num_df['value'].fillna(0)
born_num_df = born_num_df.rename(columns={'母の年齢(5歳階級)':'年齢5歳階級', '都道府県(特別区-指定都市再掲)':'都道府県', 'value':'出生数'})
print(born_num_df['年齢5歳階級'].unique())
print(born_num_df['都道府県'].unique())
print(born_num_df['year'].unique())
born_num_df47都道府県の8年間、7区分の年齢のデータなので、2632個あります。
女性人口
人口データから女性の年齢階級データだけを抽出します。
ここでは以下の条件でデータをマスクしました
- 地区が47都道府県である
- 性別は女性である
- 人口は総人口ではない
- 対象年は2015年~2022年
- 年齢が15歳~49歳である
population_origin_df['year'] = population_origin_df['時間軸(年月日現在)'].str[:4].astype(int)
mask = population_origin_df['全国・都道府県'] != '全国'
mask = mask & (population_origin_df['男女別'] == '女')
mask = mask & (population_origin_df['人口'] != '総人口')
mask = mask & (population_origin_df['year'] >= 2015)
mask = mask & (population_origin_df['year'] <= 2022)
mask = mask & (population_origin_df['年齢5歳階級'].str.contains('15~19歳|20~24歳|25~29歳|30~34歳|35~39歳|40~44歳|45~49歳'))
use_columns = ['年齢5歳階級', '全国・都道府県', 'value', 'year']
population_df = population_origin_df.loc[mask, use_columns].reset_index(drop=True)
population_df = population_df.rename(columns={'全国・都道府県':'都道府県', 'value':'女性人口'})
print(population_df['年齢5歳階級'].unique())
print(population_df['都道府県'].unique())
print(population_df['year'].unique())
population_df47都道府県の8年間、7区分の年齢のデータなので、2632個あります。出生数のデータとデータ数が同じことを確認しておきます。
転入・転出
転入と転出のデータを整形します。
この表データは2つに分かれています(2020年の以前と以後)。そして、2つの表データの形式が若干違うので、まずはそれを合わせます。
列名と年齢階級、表章項目の表記を見ると、2つの表の違いがわかります。(何が違うかは虱潰しにたしかめるしかありません)
列名で違うのは、都道府県、年齢、時間軸の3つの列名の名称でした。また、年齢のとる値をみると、なぜか0~4歳と5~9歳が全角になっているので、これも修正します。さらに、表章項目において、「’(他市町村)’」という表記が差分になっているので、これを消します。
表記を修正したら、2つの表データをconcatして一つに結合します。
また、国籍の取る値が、外国人移動者のデータを取るか取らないかの違いがありますが、ここでは日本人移動者しか見ないので、問題ないです。
print(move_num_origin_df_A.columns)
print(move_num_origin_df_B.columns)
move_num_origin_df_A = move_num_origin_df_A.rename(columns={'地域':'全国・都道府県', '年齢':'年齢(5歳階級)', '時間軸(年次)':'時間軸(年次)'})
move_num_origin_df = pd.concat([move_num_origin_df_A, move_num_origin_df_B], axis=0).reset_index(drop=True)
move_num_origin_df['表章項目'] = move_num_origin_df['表章項目'].str.replace('(他市町村)', '')
move_num_origin_df['年齢(5歳階級)'] = move_num_origin_df['年齢(5歳階級)'].str.replace('0~4歳', '0~4歳')
move_num_origin_df['年齢(5歳階級)'] = move_num_origin_df['年齢(5歳階級)'].str.replace('5~9歳', '5~9歳')
print(move_num_origin_df_A['国籍'].unique())
print(move_num_origin_df_B['国籍'].unique())
move_num_origin_df以下、実行結果です。
Index(['tab_code', '表章項目', 'cat01_code', '年齢', 'cat02_code', '性別',
'cat03_code', '国籍', 'area_code', '地域', 'time_code', '時間軸(年次)', 'unit',
'value', 'annotation'],
dtype='object')
Index(['tab_code', '表章項目', 'cat01_code', '性別', 'cat02_code', '年齢(5歳階級)',
'cat03_code', '国籍', 'area_code', '全国・都道府県', 'time_code', '時間軸(年次)',
'unit', 'value', 'annotation'],
dtype='object')
['移動者' '日本人移動者' '外国人移動者']
['移動者' '日本人移動者']一つのデータになった転入・転出の表データをから、必要な情報のみを抽出します。
ここでは以下の条件でデータをマスクしました
- 地区が47都道府県である
- 性別は女性である
- 国籍は日本人移動者である
- 対象年は2015年~2022年
- 年齢が15歳~49歳である
- 表章項目が他都道府県からの転入者数もしくは他都道府県への転出者数
まず、この条件でマスクをかけてます。
その後、転入者数の値と、転出者数の値で2つの表データを作ります。そして、2つの表データをマージして、一つの表データに直します。
area_names = '|'.join(born_rate_df['都道府県'])
move_num_origin_df['year'] = move_num_origin_df['時間軸(年次)'].str[:4].astype(int)
mask = move_num_origin_df['全国・都道府県'].str.contains(area_names)
mask = mask & (move_num_origin_df['性別'] == '女')
mask = mask & (move_num_origin_df['国籍'] == '日本人移動者')
mask = mask & (move_num_origin_df['全国・都道府県'] != '東京都特別区部')
mask = mask & (move_num_origin_df['year'] >= 2015)
mask = mask & (move_num_origin_df['year'] <= 2022)
mask = mask & (move_num_origin_df['年齢(5歳階級)'].str.contains('15~19歳|20~24歳|25~29歳|30~34歳|35~39歳|40~44歳|45~49歳'))
mask = mask & ((move_num_origin_df['表章項目'] == '他都道府県からの転入者数') | (move_num_origin_df['表章項目'] == '他都道府県への転出者数'))
use_columns = ['年齢(5歳階級)', '全国・都道府県', 'value', 'year']
in_mask = mask & (move_num_origin_df['表章項目']=='他都道府県からの転入者数')
move_in_num_df = move_num_origin_df.loc[in_mask, use_columns]
move_in_num_df = move_in_num_df.rename(columns={'全国・都道府県':'都道府県', '年齢(5歳階級)':'年齢5歳階級', 'value':'女性転入者数'})
out_mask = mask & (move_num_origin_df['表章項目']=='他都道府県への転出者数')
move_out_num_df = move_num_origin_df.loc[out_mask, use_columns]
move_out_num_df = move_out_num_df.rename(columns={'全国・都道府県':'都道府県', '年齢(5歳階級)':'年齢5歳階級', 'value':'女性転出者数'})
move_num_df = pd.merge(move_in_num_df, move_out_num_df, on=['都道府県', 'year', '年齢5歳階級'])
print(move_num_df['年齢5歳階級'].unique())
print(move_num_df['都道府県'].unique())
print(move_num_df['year'].unique())
move_num_df47都道府県の8年間、7区分の年齢のデータなので、2632個あります。出生数のデータとデータ数が同じことを確認しておきます。
合計特殊出生率の計算
4つの表データが用意できたので、それらをマージします。
まずは、3つの表データ(出生数、人口、転入・転出)をあわせていきます。ここで、女性人口は単位が1000人だったので1000倍しておきます。
df = pd.merge(born_num_df, population_df, how='left', on=['年齢5歳階級', '都道府県', 'year'])
df = pd.merge(df, move_num_df, how='left', on=['年齢5歳階級', '都道府県', 'year'])
df['女性人口'] = df['女性人口'] *1000
df正しくマージできれば、次の表が得られます。これも47都道府県の8年間、7区分の年齢のデータなので、2632個あります。
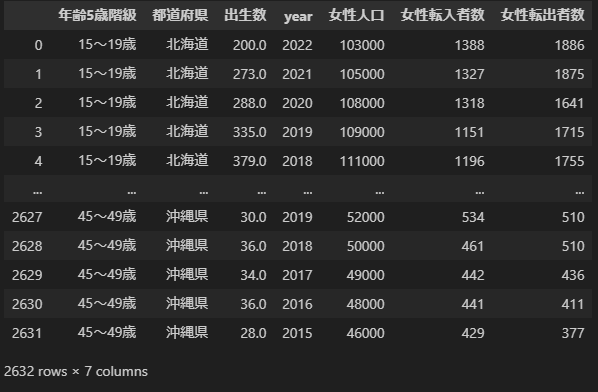
では、この表データから合計特殊出生率を計算してみて、計算方法があっているか確かめます。
groupbyメソッドで都道府県とyearによってグループ分けし、女性人口で出生率を割ります。
それらの総和を5倍したものが合計特殊出生率です。
計算した後に、最初にダウンロードした出生率の表をマージして、算出結果と比較します。
items = []
for (area, year), group_df in df.groupby(['都道府県', 'year']):
born_rate = (group_df['出生数'] / group_df['女性人口']).sum() * 5
items.append({'都道府県':area, 'year':year, '計算した出生率':born_rate})
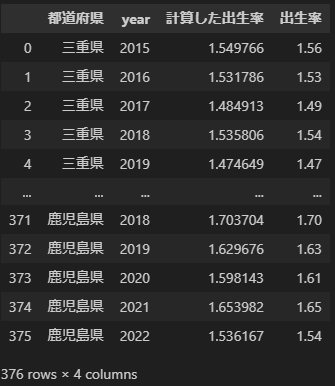
recalc_born_rate_df = pd.DataFrame(items)
recalc_born_rate_df = pd.merge(recalc_born_rate_df, born_rate_df, on=['都道府県', 'year'])
recalc_born_rate_df若干の誤差がありますが、概ね計算結果が公表値とあっています。おそらく、人口の端数が誤差の要因だと思われます。
グラフで計算した出生率と公表値を見てみても、ほとんど誤差は無いので、うまく計算できたのではないでしょうか。
import seaborn as sns
import japanize_matplotlib
sns.scatterplot(recalc_born_rate_df, x='出生率', y='計算した出生率', hue='year')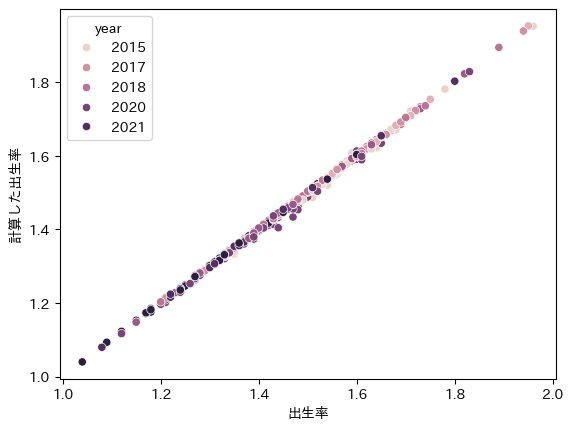
転入・転出を考慮した合計特殊出生率の計算
ではここから、本題の転入と転出を考慮した合計特殊出生率を計算してみようと思います。
とは言え、すでにデータを整形してあるのでやることは単純です。
女性人口を、転入者と転出者で足し引きして再調整するだけですね。
items = []
for (area, year), group_df in df.groupby(['都道府県', 'year']):
born_rate = (group_df['出生数'] / group_df['女性人口']).sum() * 5
adjust_population = group_df['女性人口'] - group_df['女性転入者数'] + group_df['女性転出者数']
adjust_born_rate = (group_df['出生数'] / adjust_population).sum() * 5
items.append({'都道府県':area, 'year':year, '計算した出生率':born_rate, '転入出を調整した出生率':adjust_born_rate})
recalc_born_rate_df = pd.DataFrame(items)
recalc_born_rate_df = pd.merge(recalc_born_rate_df, born_rate_df, on=['都道府県', 'year'])
recalc_born_rate_df['出生率'] = recalc_born_rate_df['出生率'].astype(float)
recalc_born_rate_df実行すると次の表が得られます。調整した出生率が新しく追加されていますね。
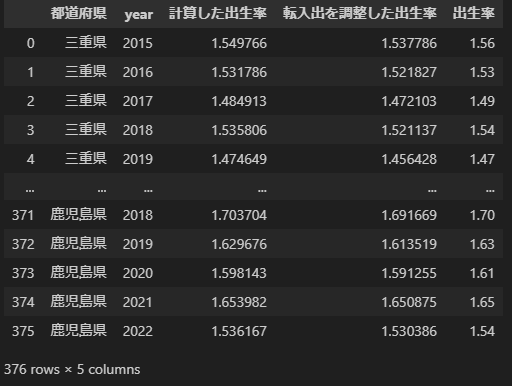
ただ、出生率と調整した出生率を比較しても、大きな変化は無いように思えます。マイナス0.01~0.03ポイント程度でしょうか。
ちなみに東京都の結果は次のような感じです。
recalc_born_rate_df.query('都道府県 == "東京都"')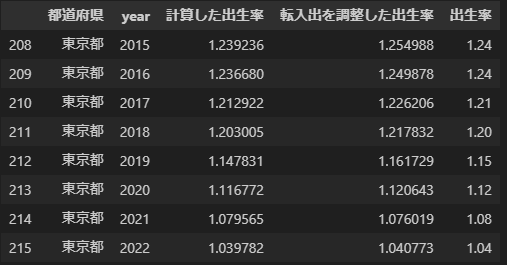
元の出生率からは0.01~0.03程度上昇していることがわかります。つまり、確かに「東京は継続的に地方から働く女性が流入してくるため、出生率が低くなるのは当然だ」という論法はデータ的には正しかったようです。
しかし、思ってたほど出世率は向上しませんでした。それこそ、地方と都市部の出生率が逆転するような事態にはなりませんでした。
調整前と調整後の出生率を散布図にしてみます。
import seaborn as sns
import japanize_matplotlib
sns.scatterplot(recalc_born_rate_df, x='転入出を調整した出生率', y='計算した出生率', hue='year')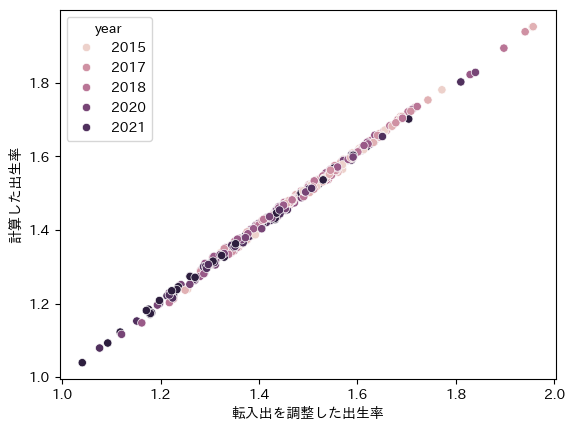
やはり思っていたほど、転入出を調整しても出生率は向上・低下しないようです。
考察
「東京は継続的に地方から働く女性が流入してくるため、出生率が低くなるのは当然だ」という論法をデータ的に検証してみました。
しかし、検証結果をまとめると、「東京の出生率は確かに転入・転出を加味すると向上するが、最大でも0.03程度」ということでした。一見正しそうに思える論法ですが、なぜ、大きな影響を与えなかったのでしょうか。
私が考えた要因は次のとおりです。
- 都道府県単位だとあまり変化がないかも
- 今回は、都道府県単位でしかe-statのapiからは取れなかったので、都道府県単位で分析しましたが、実際には市区町村単位で分析したほうが良さそうです
- 都市部といわれる場所への人口流入・流出を考慮するのであれば、もっと狭い地域で分析したほうがいいかも
- 東京は流入してきた人も結婚する
- 働き先(もしくは魅力)が無いから東京へ流入してくるだけで、出生率には大きな影響を与えない
- そもそも晩婚化が進んでいる
- 東京都の流入と流出の年代別のデータをみると、30歳までは転入のほうが多いが、30歳以降は転出が多くなる。つまり、晩婚化が進んでいる都市部では、結婚したら東京から出ていくケースも割と多い(実際、家賃とかの関係で千葉・埼玉・神奈川への移住はありえる)
- 最新のデータだと違う
- 公開データが2022年までしか無かったので、2023年以降では違った結論になるかもしれません。
- データが間違っている
- 利用したデータが間違っているのかも。間違ってる指摘があったら教えて下さい
まとめ
今回は、「東京は継続的に地方から働く女性が流入してくるため、出生率が低くなるのは当然だ」という論法をデータを使って検証してみました。
結論としては、転入・転出を加味すると「東京の出生率はほんの少しだけ向上する」ということがわかりました。しかし、年々低下していく東京の出生率は、転入と転出による影響ではないということも、わかりました。
今後も、気になったことをデータベースで検証できればいいと思っています。

