
GPでベットをするかしないかを予測する関数を作ります。
前回は選択方法を改善しましたが、うまく利益上げることができませんでした。
今回は多目的進化計算を使って見たいと思います。
今までのGPでは、評価値に一つの値しか取ることができませんでした。
多目的(Multi-objective)では、他のものも評価値として並列に扱えるため、より過学習しにくいと考えられます。
例えば、今回の実験では総利益の他に勝った賭け数や、負けた賭け数を評価値として返します。
多目的最適化についてもこの本では詳しく解説しませんので、自分で調べることを推奨します。
学習過程はipynbファイルで行いました。以下はその記録です。
前処理
前処理は今までと変わりません。
まず、使いそうなライブラリをインポートします。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from IPython.display import display, Math学習データの読み込み
df = pd.read_pickle('/work/formatted_source_data/analysis_data02.pkl')次に学習データとテストデータ、バリデーションデータの切り分け、および入力データと教師データの切り分けをします。データの正規化もします。
教師データは単勝が当たったかどうか(tansyo_hit)と単勝が当たった時の支払い金額(tansyo_payout)を使います。
df = df.sort_values(['race_date']).reset_index(drop=True)
not_use_columns = [
'race_date', 'race_id', 'race_grade', 'name', 'jocky_name', 'odds', 'popular', 'rank', 'time', 'prize', 'tansyo_hit', 'tansyo_payout', 'hukusyo_hit', 'hukusyo_payout',
]
not_use_df = df[not_use_columns]
target_df = df.drop(columns=not_use_columns)
train_df = target_df.loc[not_use_df['race_date'] < '2018-01-01', :].reset_index(drop=True)
valid_df = target_df.loc[('2018-01-01' <= not_use_df['race_date']) & (not_use_df['race_date'] < '2022-01-01'), :].reset_index(drop=True)
test_df = target_df.loc['2022-01-01' <= not_use_df['race_date'], :].reset_index(drop=True)
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
train_X = pd.DataFrame(data=scaler.fit_transform(train_df), columns=train_df.columns)
valid_X = pd.DataFrame(data=scaler.transform(valid_df), columns=train_df.columns)
test_X = pd.DataFrame(data=scaler.transform(test_df), columns=train_df.columns)
train_X = train_X.fillna(0)
valid_X = valid_X.fillna(0)
test_X = test_X.fillna(0)
Y_columns = ['tansyo_hit', 'tansyo_payout']
train_Y = not_use_df.loc[not_use_df['race_date'] < '2018-01-01', Y_columns].reset_index(drop=True)
valid_Y = not_use_df.loc[('2018-01-01' <= not_use_df['race_date']) & (not_use_df['race_date'] < '2022-01-01'), Y_columns].reset_index(drop=True)
test_Y = not_use_df.loc['2022-01-01' <= not_use_df['race_date'], Y_columns].reset_index(drop=True)
train_Y = train_Y.rename(columns={'tansyo_hit':'hit', 'tansyo_payout':'payout'})
valid_Y = valid_Y.rename(columns={'tansyo_hit':'hit', 'tansyo_payout':'payout'})
test_Y = test_Y.rename(columns={'tansyo_hit':'hit', 'tansyo_payout':'payout'})学習
まず、使うライブラリをインポートします。
import operator
from deap import base
from deap import creator
from deap import tools
from deap import gp
import random
from functools import partial割り算の演算関数を再定義します。
def protectedDiv(left, right):
with np.errstate(divide='ignore',invalid='ignore'):
x = np.divide(left, right)
if isinstance(x, np.ndarray):
x[np.isinf(x)] = 1
x[np.isnan(x)] = 1
elif np.isinf(x) or np.isnan(x):
x = 1
return x次にGPでつかう関数群を定義します。
pset = gp.PrimitiveSet("MAIN", len(train_X.columns))
pset.addPrimitive(np.add, 2, name="add")
pset.addPrimitive(np.subtract, 2, name="sub")
pset.addPrimitive(np.multiply, 2, name="mul")
pset.addPrimitive(protectedDiv, 2, name='div')
pset.addPrimitive(np.negative, 1, name="neg")
pset.addPrimitive(np.cos, 1, name="cos")
pset.addPrimitive(np.sin, 1, name="sin")
pset.addEphemeralConstant("rand101", partial(random.randint, -1, 1))
pset.renameArguments(**{f'ARG{i}':f'x_{col}' for i, col in enumerate(train_X.columns)})評価クラスを多目的用に設定します。FittnessMultiとしました。
weightsは複数の評価値の重みです。3つ目の評価値として負けた賭け数を与えるため、それは最小化が目的なので-1.0を設定。それ以外の2つは最大化がもくてきなので1.0を設定。
creator.create("FitnessMulti", base.Fitness, weights=(1.0, 1.0, -1.0))
creator.create("Individual", gp.PrimitiveTree, fitness=creator.FitnessMax)
toolbox = base.Toolbox()
toolbox.register("expr", gp.genHalfAndHalf, pset=pset, min_=1, max_=2)
toolbox.register("individual", tools.initIterate, creator.Individual, toolbox.expr)
toolbox.register("population", tools.initRepeat, list, toolbox.individual)
toolbox.register("compile", gp.compile, pset=pset)評価関数を定義します。個体(解候補)が与えられたときに、その評価値を返せばよいです。
toolbox.compileによって解候補から合成関数を作り出します。その後、train_inputsを与えて、出力値を得ます。
出力値が0以上のときに賭け、そうでないときは賭けないようにして、利益を算出します。
その総利益を評価値として返します。
また、勝った数や負けた数を数えてそれらも評価値として返します。
train_inputs = {f'x_{col}':train_X.loc[:, col].values for col in train_X.columns}
def eval_individual(individual):
func = toolbox.compile(expr=individual)
ret = func(**train_inputs)
bet = np.zeros_like(ret)
bet[ret > 0] = 1
win_num = np.sum(win_money > 0)
lose_num = np.sum(win_money < 0)
return win_score, win_num, lose_num定義した評価関数や、deapに内蔵されている選択、交叉、突然変異の関数をtoolboxに登録します。また、個体の深さ(合成関数の処理規模だと思ってください)に制限を設けます。
選択方法をtools.selNSGA2に設定します。多目的最適化の手法はたくさんありますが、今回は評価値も3つなのでクラシックなNSGA2にしたいと思います。
toolbox.register("evaluate", eval_individual)
toolbox.register("select", tools.selNSGA2)
toolbox.register("mate", gp.cxOnePoint)
toolbox.register("expr_mut", gp.genFull, min_=0, max_=2)
toolbox.register('mutate', gp.mutUniform, expr=toolbox.expr_mut, pset=pset)
toolbox.decorate("mate", gp.staticLimit(key=operator.attrgetter("height"), max_value=12))
toolbox.decorate("mutate", gp.staticLimit(key=operator.attrgetter("height"), max_value=12))準備が揃ったので、学習を始めます。
個体数500、世代数200で学習します。
crossover_rate = 0.8
mutate_rate = 0.2
max_generation = 200
population_size = 500
random.seed(318)
population = toolbox.population(n=population_size)
halloffame = tools.HallOfFame(1)
stats_fit0 = tools.Statistics(lambda ind: ind.fitness.values[0])
stats_fit1 = tools.Statistics(lambda ind: ind.fitness.values[1])
stats_fit2 = tools.Statistics(lambda ind: ind.fitness.values[2])
mstats = tools.MultiStatistics(win_score=stats_fit0, win_num=stats_fit1, lose_num=stats_fit2)
mstats.register("avg", np.mean)
mstats.register("std", np.std)
mstats.register("min", np.min)
mstats.register("max", np.max)
logbook = tools.Logbook()
logbook.header = ['gen', 'nevals'] + mstats.fields
# Evaluate the individuals with an invalid fitness
invalid_ind = [ind for ind in population if not ind.fitness.valid]
fitnesses = toolbox.map(toolbox.evaluate, invalid_ind)
for ind, fit in zip(invalid_ind, fitnesses):
ind.fitness.values = fit
pop = toolbox.select(population, len(population))
if halloffame is not None:
halloffame.update(population)
record = mstats.compile(population)
logbook.record(gen=0, nevals=len(invalid_ind), **record)
print(logbook.stream)
elite = None
# Begin the generational process
for gen in range(1, max_generation + 1):
# Select the next generation individuals
offspring = tools.selTournamentDCD(population, len(population))
offspring = [toolbox.clone(ind) for ind in offspring]
# Apply crossover and mutation on the offspring
for i in range(1, len(offspring), 2):
if random.random() < crossover_rate:
offspring[i - 1], offspring[i] = toolbox.mate(offspring[i - 1], offspring[i])
del offspring[i - 1].fitness.values, offspring[i].fitness.values
for i in range(len(offspring)):
if random.random() < mutate_rate:
offspring[i], = toolbox.mutate(offspring[i])
del offspring[i].fitness.values
# Evaluate the individuals with an invalid fitness
invalid_ind = [ind for ind in offspring if not ind.fitness.valid]
fitnesses = toolbox.map(toolbox.evaluate, invalid_ind)
for ind, fit in zip(invalid_ind, fitnesses):
ind.fitness.values = fit
# Update the hall of fame with the generated individuals
if halloffame is not None:
halloffame.update(offspring)
population = toolbox.select(population + offspring, population_size)
# Append the current generation statistics to the logbook
record = mstats.compile(population)
logbook.record(gen=gen, nevals=len(invalid_ind), **record)
print(logbook.stream)実行するとログが流れます。終わるまで待ちます。
lose_num win_num win_score
---------------------------------------------- ----------------------------------------------- -------------------------------------------------------
gen nevals avg gen max min nevals std avg gen max min nevals std avg gen max min nevals std
...
198 428 218343 198 472111 0 428 145112 24080.7 198 35862 0 428 10651.3 -52135.2 198 2629.9 -138531 428 37984.3
199 419 217249 199 472111 0 419 146645 23935.1 199 35862 0 419 10747.9 -52043.2 199 2629.9 -138531 419 38429.6
200 419 218052 200 472111 0 419 146987 23980.7 200 35862 0 419 10752.8 -52206.5 200 2629.9 -138531 419 38486.3パレート解を見てみます。
多目的最適化では複数の評価基準があるため、一番良い解候補というのをアルゴリズムは選べません。複数の回候補を見て、人が選ぶ必要があります。
fits = np.array([ind.fitness.values for ind in population])
#win_score, bet_num, lose_score
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(131)
plt.scatter(fits[:, 0], fits[:, 1])
plt.title('win_score - win_num')
plt.xlabel('win_score')
plt.ylabel('win_num')
plt.subplot(132)
plt.scatter(fits[:, 1], fits[:, 2])
plt.title('win_num - lose_num')
plt.xlabel('win_num')
plt.ylabel('lose_num')
plt.subplot(133)
plt.scatter(fits[:, 0], fits[:, 2])
plt.title('win_score - lose_num')
plt.xlabel('win_score')
plt.ylabel('lose_num')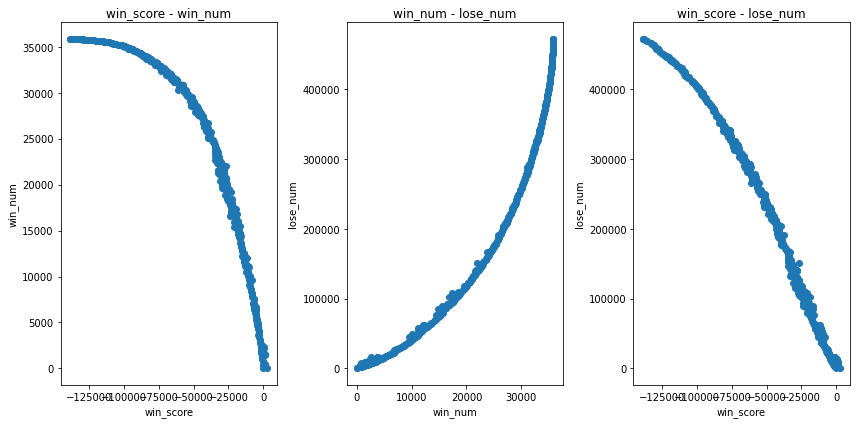
カーブが描けているので、アルゴリズムは正常に動作しているようです。
ただ、win_scoreがほとんどの場合で0以下になってしまっているため、ほとんど不要な解候補となっています。
学習データで利益がでたものだけ、ピックアップしてバリデーションとテストデータの利益を見てみます。
def calc_win_money(individual, X, Y):
inputs = {f'x_{col}':X.loc[:, col].values for col in X.columns}
func = toolbox.compile(expr=individual)
ret = func(**inputs)
bet = np.zeros_like(ret)
bet[ret > 0] = 1
win_money = bet*(Y['hit']*Y['payout'] - 1.0)
return np.sum(win_money)
for i, ind in enumerate(population):
if ind.fitness.values[0] > 0:
print(f'--------{i}--------')
print(ind.fitness.values)
print(f'train win money: {calc_win_money(ind, train_X, train_Y)}')
print(f'valid win money: {calc_win_money(ind, valid_X, valid_Y)}')
print(f'test win money: {calc_win_money(ind, test_X, test_Y)}')インデックス1の解候補は学習、バリデーション、テストデータの3つとも利益がでています。しかし、他の解候補はテストデータ利益がでていません。
--------1--------
(2629.9000000000005, 49.0, 588.0)
train win money: 2629.9000000000005
valid win money: 20551.800000000003
test win money: 29.100000000000023
--------42--------
(1083.1000000000004, 526.0, 5137.0)
train win money: 1083.1000000000004
valid win money: 19569.100000000002
test win money: -805.2000000000002
--------141--------
(1445.999999999999, 1481.0, 9710.0)
train win money: 1445.999999999999
valid win money: -1170.2000000000003
test win money: -953.6000000000001
--------184--------
(1226.5999999999997, 1535.0, 9224.0)
train win money: 1226.5999999999997
valid win money: -828.6
test win money: -971.8
--------247--------
(398.40000000000003, 2349.0, 12860.0)
train win money: 398.40000000000003
valid win money: -1471.4
test win money: -1213.6999999999998
--------404--------
(832.4000000000007, 2172.0, 12617.0)
train win money: 832.4000000000007
valid win money: -1504.7
test win money: -1113.3インデックス1の解候補の利益の推移を見てみます。
def calc_win_money_line(individual, X, Y):
inputs = {f'x_{col}':X.loc[:, col].values for col in X.columns}
func = toolbox.compile(expr=individual)
ret = func(**inputs)
bet = np.zeros_like(ret)
bet[ret > 0] = 1
win_money_line = bet*(Y['hit']*Y['payout'] - 1.0)
return np.cumsum(win_money_line)
target_ind = population[1]
fits = np.array([ind.fitness.values for ind in population])
#win_score, bet_num, lose_score
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(131)
win_money_line = calc_win_money_line(target_ind, train_X, train_Y)
plt.plot(win_money_line)
plt.title('train')
plt.xlabel('x(date)')
plt.ylabel('win_score')
plt.subplot(132)
win_money_line = calc_win_money_line(target_ind, valid_X, valid_Y)
plt.plot(win_money_line)
plt.title('valid')
plt.xlabel('x(date)')
plt.ylabel('win_score')
plt.subplot(133)
win_money_line = calc_win_money_line(target_ind, test_X, test_Y)
plt.plot(win_money_line)
plt.title('test')
plt.xlabel('x(date)')
plt.ylabel('win_score')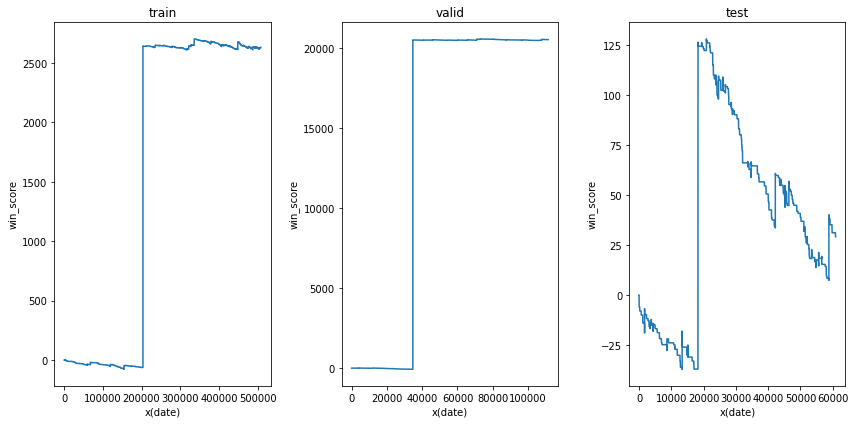
あまりいい感じではないですね。一つの単勝をたまたま当てた結果、利益がでているように見えましたが、他の地点では徐々に降下傾向にあるため、これを本番で使うのかなりリスキーです。
