
本章の目的
No.06では強化学習による株取引最適化を行いました.
強化学習のQ関数であるQネットワークは複数の行動についての行動価値を出力します.そのあと,最も行動価値の高い行動を選択するという操作を行います.
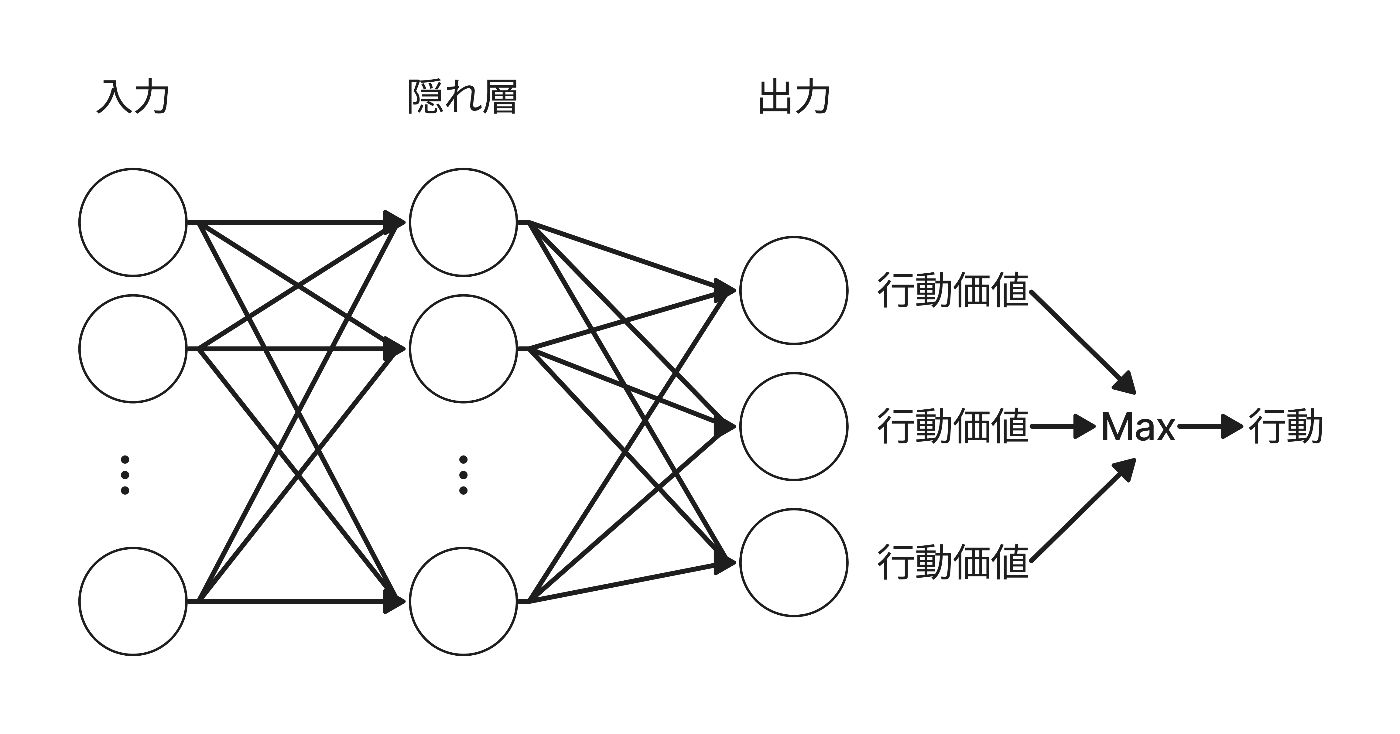
そのため,No.06では「単独の銘柄を総資産の何%保有するか」という形で行動を表現しました.例えば
- 0%保有
- 25%保有
- 50%保有
- 75%保有
- 100%保有
という5つの行動です.
ここで,本当はN個の銘柄が存在するのであれば,N+1個の出力で各銘柄の保有割合を表現したいのです.例えば
- 銘柄Aを20%
- 銘柄Bを0%
- 銘柄Cを10%
- 銘柄Dを40%
- 現金を30%
という出力です.しかし,この例の出力は強化学習(Q学習)では表現することが難しいのです.なぜならこの例の出力が一つの行動であり,割合を変化させた行動が無数に存在するためです.
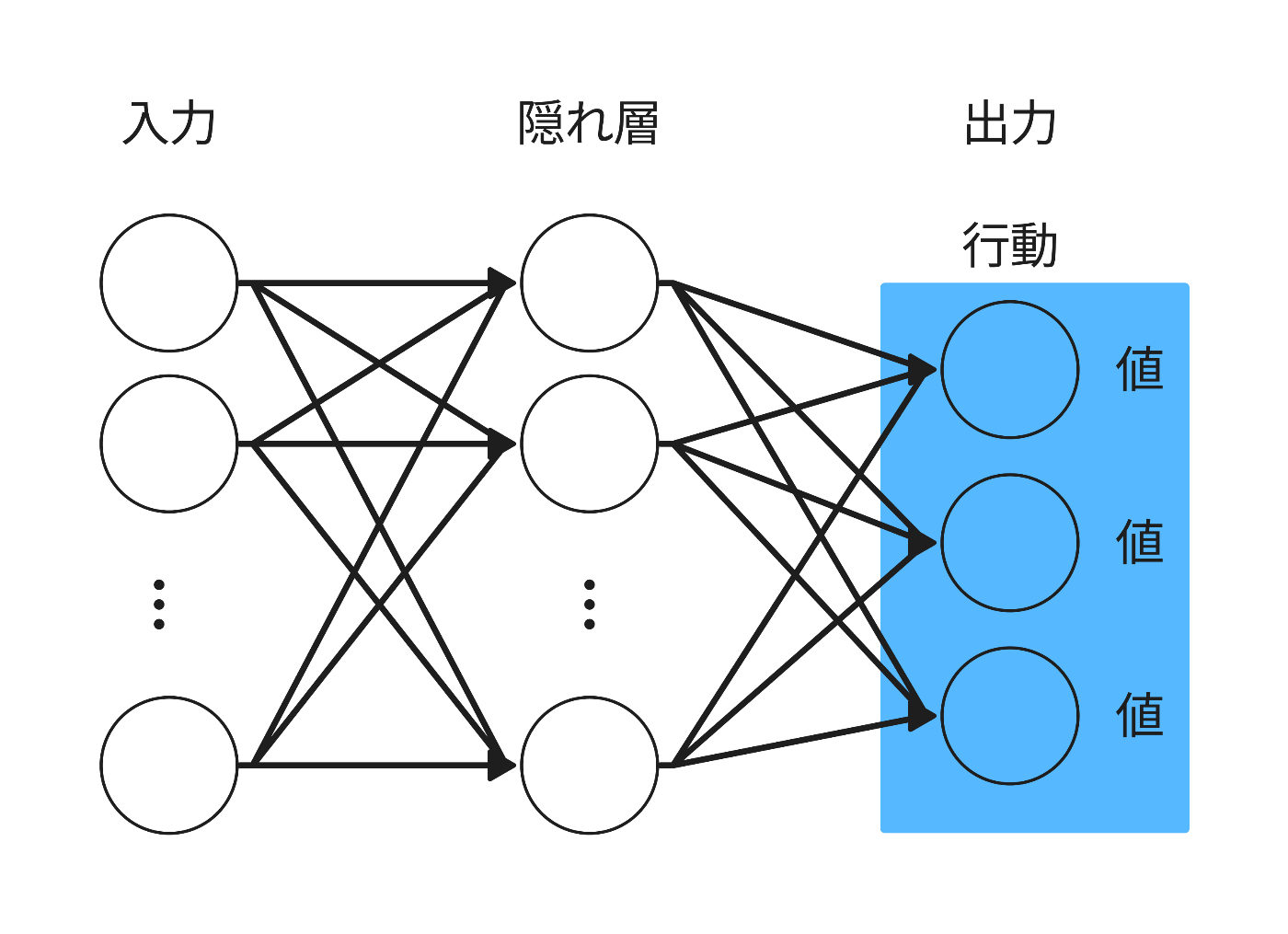
そこで本章では,進化計算を利用した株式取引の最適化を行ってみたいと思います.
進化計算を利用したネットワークの最適化であれば,Q学習のように複数の行動価値を出力するという制約が必要なくなるため,直接複数の保有割合を出力するネットワークが作れます.
ディレクトリ・ファイル構造
work_share
├07_evolutionary_algorithms
├Dockerfile
├docker-compose.yml
└src
├result(自動生成)
├neuro_evolution_torch
| ├nsga2_neuroevo.py
| ├torch_model.py
| ├simulation_cython.pyx
| └setup.py
└experiment01.py本章では以下の4つのプログラムを作成し,experiment01.pyを実行します.
- nsga2_neuroevo.py
- torch_model.py
- simulation_cython.pyx
- setup.py
- experiment01.py
Dockerfile
FROM nvcr.io/nvidia/pytorch:22.04-py3
USER root
RUN apt-get update
RUN apt-get -y install locales && \
localedef -f UTF-8 -i ja_JP ja_JP.UTF-8
ENV LANG ja_JP.UTF-8
ENV LANGUAGE ja_JP:ja
ENV LC_ALL ja_JP.UTF-8
ENV TZ JST-9
ENV TERM xterm
ENV TZ=Asia/Tokyo
RUN ln -snf /usr/share/zoneinfo/$TZ /etc/localtime && echo $TZ > /etc/timezone
ENV PYTHONPATH "/root/src:$PYTHONPATH"
RUN apt-get update
RUN pip install --upgrade pip
RUN pip install --upgrade setuptools
RUN python -m pip install requests
RUN python -m pip install numpy
RUN python -m pip install pandas
RUN python -m pip install matplotlib
RUN python -m pip install scikit-learn
RUN python -m pip install optuna
RUN python -m pip install seaborn
RUN apt-get install -y gconf-service libasound2 libatk1.0-0 libatk-bridge2.0-0 libc6 libcairo2 libcups2 libdbus-1-3 libexpat1 libfontconfig1 libgcc1 libgconf-2-4 libgdk-pixbuf2.0-0 libglib2.0-0 libgtk-3-0 libnspr4 libpango-1.0-0 libpangocairo-1.0-0 libstdc++6 libx11-6 libx11-xcb1 libxcb1 libxcomposite1 libxcursor1 libxdamage1 libxext6 libxfixes3 libxi6 libxrandr2 libxrender1 libxss1 libxtst6 ca-certificates fonts-liberation libappindicator1 libnss3 lsb-release xdg-utils wget
RUN python -m pip install japanize-matplotlib
RUN python -m pip install lightgbm
RUN python -m pip install notebook
RUN python -m pip install tqdm
RUN python -m pip install pandas_datareader
RUN python -m pip install yfinance
RUN python -m pip install xlrd
RUN python -m pip install deap
RUN python -m pip install memory_profiler
ARG USERNAME=user
ARG GROUPNAME=user
ARG UID=1000
ARG GID=1000
ARG PASSWORD=user
RUN groupadd -g $GID $GROUPNAME && \
useradd -m -s /bin/bash -u $UID -g $GID -G sudo $USERNAME && \
echo $USERNAME:$PASSWORD | chpasswd
USER $USERNAMEdocker-compose.yml
ほとんど前回書いたymlと変わりませんが, -../01_get_stock_price/src/dataset_2018_2023:/work/dataset
が追記されています.これにより前回生成したデータセットのディレクトリをマウントすることができます.
version: '3'
services:
stock_predict_ea_python:
restart: always
build: .
container_name: 'python_stock_predict_ea'
working_dir: '/work/src'
tty: true
volumes:
- ./src:/work/src
- ../05_lightGBM_predict/src/dataset:/work/dataset_pred
- ../04_get_stock_price_ver2/src/dataset:/work/dataset
#ports:
# - 8888:8888
ulimits:
memlock: -1
stack: -1
shm_size: '10gb'
deploy:
resources:
reservations:
devices:
- capabilities: [gpu]コンテナの実行と仮想環境に入る
Dockerfileと同じディレクトリ上で実行します.
仮想環境のビルド
docker compose up -d --build仮想環境に入る
docker compose exec stock_predict_ea_python bash仮想環境の終了
docker compose down