
速度データの加工の必要性
前回、戦績データを作るために、レースので全データをテーブルデータへと変換しました。
ある日の任意の馬のレースに対しては、日付と馬で条件付をして、過去のレースデータを生成し、統計処理することで馬の戦績を割り出せます。
ここで一つ、重要な話なのですが、このテーブルデータには速度データが含まれています。「任意の馬があるレースを何秒で走ったか」という値です。
この速度データはその馬の相対的な強さを表す指標として使えそうです。しかし、そのままではレースごとの距離などの他の要因によって、単純に強さとして表すことができません。
そこで、速度データから、影響を与えた要因を取り除くことで、その馬の強さという指標を新たに作り出します。
プログラム
この話はipynb形式のファイルで行いました。解析系の順次実行はノートブックの形式で進めるのが良いと思います。作成するファイルの名前は何でもいいと思います。
まずは、利用しそうなライブラリをインポートします。利用するときにインポートしても良いと思います。
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from IPython.display import display, Mathデータを読み込みます。前回生成したテーブルデータです。VS CodeのDev Containerでipynbを実行すると作業ディレクトリがソースコードのディレクトリと一致しなかったので、絶対パスで読み込みました。
df = pd.read_pickle(f'/work/formatted_source_data/analysis_data01.pkl')保存されているタイムデータが文字列なので、秒数へと変換します
def time_str_to_sec_float(time_str):
sp_df = time_str.str.split(':', expand=True)
sp_df.columns = ['min', 'sec']
sp_df = sp_df.astype('float64')
return sp_df['min']*60 + sp_df['sec']
df['time_sec'] = time_str_to_sec_float(df['time'])
df[['time', 'time_sec']]実行結果で文字列から秒数へと変換できてるのがわかります
time time_sec
0 1:00.0 60.0
1 1:01.6 61.6
2 1:00.7 60.7
3 1:02.0 62.0
4 1:02.4 62.4
... ... ...
12 1:09.3 69.3
13 1:09.3 69.3
14 1:09.7 69.7
15 1:09.0 69.0
16 1:09.8 69.8
680592 rows × 2 columnsさて、このtime_sec(秒数)とrace_distance(レースの距離)の関係を見てみます。
plt.scatter(df['race_distance'], df['time_sec'])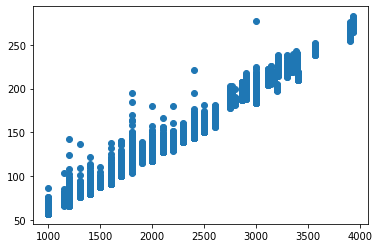
当たり前ですが、距離によって秒数が変化しているのがわかります。
試しに、回帰直線を引いてみましょう。
a, b = np.polyfit(df['race_distance'], df['time_sec'], 1)
x = np.linspace(df['race_distance'].min(), df['race_distance'].max(), 100)
y = a*x + b
display(Math(f'time = {a}*distance {b}'))
plt.scatter(df['race_distance'], df['time_sec'])
plt.plot(x, y, color='red')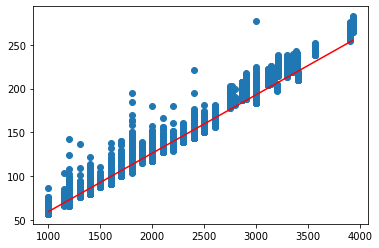
これの直線が、「距離が秒数に与える影響」と言ってもいいでしょう。
つまり、逆を言えば、この直線をタイムから引いたものは、「距離が秒数に与える影響」がなくなったと言えます。
new_time_sec = df['time_sec'] - (a*df['race_distance'] + b)
plt.scatter(df['race_distance'], new_time_sec)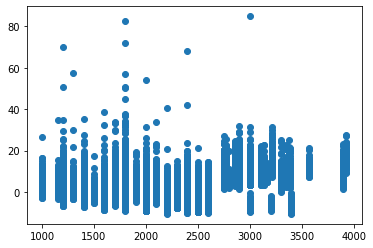
ではこの値をそのまま「馬の強さ」として使いことはできるでしょうか。
答えは否です。
なぜなら、距離以外にも秒数に影響を与える変数があるからです。他の変数を一つ一つ検証して、引いても良いのですが、面倒なので多変量モデル(lightGBM)を使って、一気に処理しちゃいます。
まずは、lightGBMへと入力するためにデータを整えます。
df = df.sort_values(['race_date']).reset_index(drop=True)
target_columns = ['place_id', 'race_distance',
'race_type', 'weather', 'race_condition',
'horse_count', 'waku', 'horse_number', 'sex', 'age',
'jocky_weight', 'weight', 'weight_sub',
'time_sec']
train_df = df.loc[df['race_date'] < '2020-01-01', target_columns].reset_index(drop=True)
test_df = df.loc[df['race_date'] >= '2020-01-01', target_columns].reset_index(drop=True)
from sklearn.preprocessing import StandardScaler
scaler_columns = ['race_distance',
'jocky_weight', 'weight', 'weight_sub',
'time_sec']
scaler = StandardScaler()
train_scalered_df = pd.DataFrame(data=scaler.fit_transform(train_df), columns=train_df.columns)
test_scalered_df = pd.DataFrame(data=scaler.transform(test_df), columns=test_df.columns)
train_df.loc[:, scaler_columns] = train_scalered_df.loc[:, scaler_columns]
test_df.loc[:, scaler_columns] = test_scalered_df.loc[:, scaler_columns]
train_y = train_df['time_sec']
train_X = train_df.drop(columns=['time_sec'])
test_y = test_df['time_sec']
test_X = test_df.drop(columns=['time_sec'])そしたら、lightgbmで学習して、モデルを作成します。このモデルが先程の距離と秒数の直線のようなものです。
ちなみに、秒数に対して影響を与える変数は基本的には独立であり、複雑に相互作用しないと仮定しています。ですからligthGBMのnum_leavesを小さめに設定しました。
import lightgbm as lgb
params = {
'objective': 'regression',
'metric': 'rmse',
'num_leaves': 8,
'learning_rate': 0.1, # default = 0.1
}
num_round = 10000
from sklearn.model_selection import train_test_split
train_X, valid_X, train_y, valid_y = train_test_split(train_X, train_y, test_size=0.75)
train_X = train_X.reset_index(drop=True)
valid_X = valid_X.reset_index(drop=True)
train_y = train_y.reset_index(drop=True)
valid_y = valid_y.reset_index(drop=True)
lgb_train = lgb.Dataset(train_X, train_y)
lgb_eval = lgb.Dataset(valid_X, valid_y)
# training
model = lgb.train(params, lgb_train,
num_boost_round=num_round,
valid_sets=[lgb_train, lgb_eval],
valid_names=['train', 'valid'],
callbacks=[lgb.early_stopping(stopping_rounds=10, verbose=1)]
)
rmse = lambda a, b : np.mean(np.sqrt((a-b)**2))
train_pred = model.predict(train_X)
valid_pred = model.predict(valid_X)
test_pred = model.predict(test_X)
print(f'train rmse : {rmse(train_pred, train_y)}')
print(f'valid rmse : {rmse(valid_pred, valid_y)}')
print(f'test rmse : {rmse(test_pred, test_y)}')実行すると、学習が始まり、最後には結果のRMSEが表示されます。test rmseがvalid rmseと離れており、過学習傾向が無いとは言えませんが、これ以上は小さくできなかったので、このモデルを採用します。
/opt/conda/lib/python3.8/site-packages/tqdm/auto.py:22: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
[LightGBM] [Info] Auto-choosing row-wise multi-threading, the overhead of testing was 0.003934 seconds.
You can set `force_row_wise=true` to remove the overhead.
And if memory is not enough, you can set `force_col_wise=true`.
[LightGBM] [Info] Total Bins 337
[LightGBM] [Info] Number of data points in the train set: 140969, number of used features: 13
[LightGBM] [Info] Start training from score -0.004559
Training until validation scores don't improve for 10 rounds
Early stopping, best iteration is:
[669] train's rmse: 0.071896 valid's rmse: 0.0721394
train rmse : 0.05223274104222317
valid rmse : 0.052743122046095575
test rmse : 0.0595115454350812モデルの出力と実際の秒数の関係を見てみます。
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(131)
plt.scatter(train_pred, train_y)
plt.title('train')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(132)
plt.scatter(valid_pred, valid_y)
plt.title('valid')
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(133)
plt.scatter(test_pred, test_y)
plt.title('test')
plt.xlabel('pred')
plt.ylabel('y')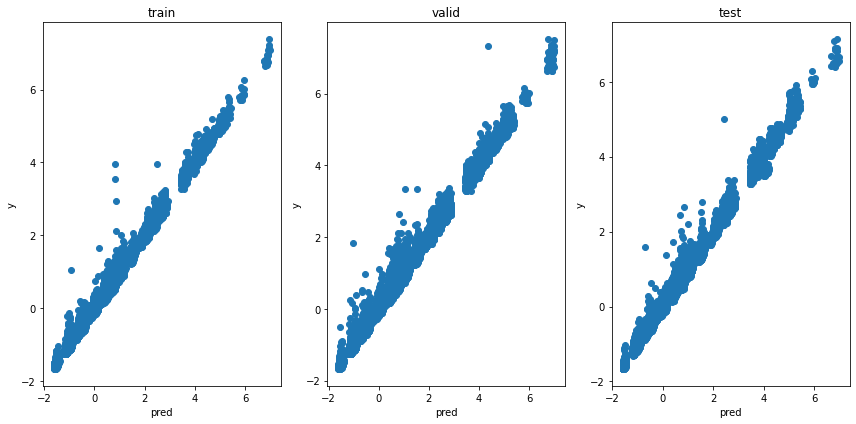
いい感じでは無いでしょうか。十分に相関が出ていて、「レースの変数が秒数に与える影響」を表していると言えます。あとは、これの差分がその馬の「強さ」となります(実際には気分や調子、成長などの因子が入っていますが、それを取り除くことはかなり難しいです)
馬の強さを計算して、ヒストグラムにしてみます。
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(131)
train_strength = train_y - train_pred
plt.hist(train_strength, bins=100, density=True)
plt.title('train')
plt.xlabel('strength')
plt.subplot(132)
valid_strength = valid_y - valid_pred
plt.hist(valid_strength, bins=100, density=True)
plt.title('valid')
plt.xlabel('strength')
plt.subplot(133)
test_strength = test_y - test_pred
plt.hist(test_strength, bins=100, density=True)
plt.title('test')
plt.xlabel('strength')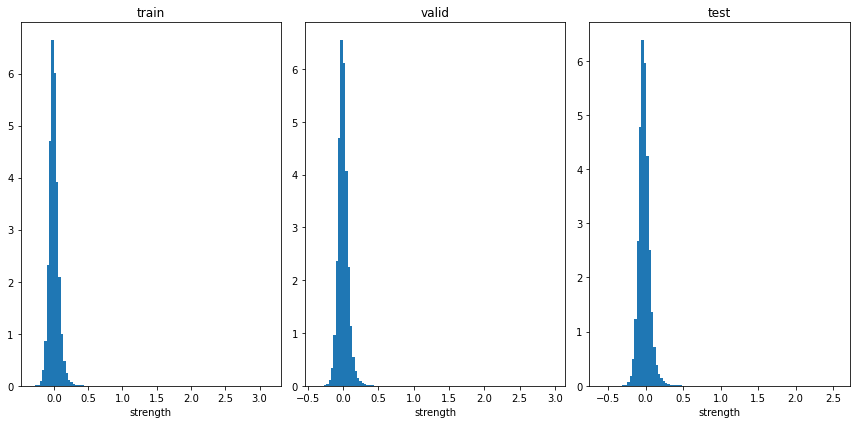
多くの馬が0付近であり、±0.5の区間にほとんどいるようです。左によっているのは、飛び抜けて強い馬がいくつか存在してしまうからですね。区間を拡大してみます
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(131)
train_strength = train_y - train_pred
plt.hist(train_strength, bins=100, density=True)
plt.title('train')
plt.xlim((-0.5, 0.5))
plt.xlabel('strength')
plt.subplot(132)
valid_strength = valid_y - valid_pred
plt.hist(valid_strength, bins=100, density=True)
plt.title('valid')
plt.xlim((-0.5, 0.5))
plt.xlabel('strength')
plt.subplot(133)
test_strength = test_y - test_pred
plt.hist(test_strength, bins=100, density=True)
plt.title('test')
plt.xlim((-0.5, 0.5))
plt.xlabel('strength')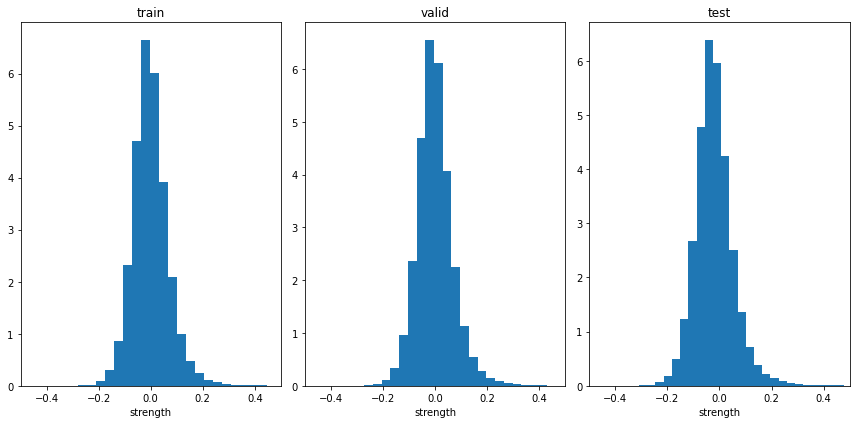
いい感じに分布していると思います。
さらに、「レースの変数が秒数に与える影響」を確認します
importance = pd.DataFrame(model.feature_importance(), index=train_X.columns, columns=['importance'])
importance = importance.sort_values(['importance'])
plt.barh(importance.index, importance['importance'], align="center")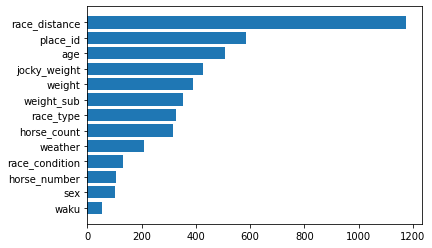
やはり、距離が一番影響を与える要因であり、次がplace_idです。競馬場ごとに特性があるらしいです。年齢も妥当な要因であり、真馬よりも3~4歳の全盛期の馬のほうがタイムが早そうです。
わりと良い感じにモデルを作れたと思うので、このモデルの影響を引いた値は、良い感じに「馬の強さ」として働くと思います。
このモデルを動かせるように一応保存しておきます(以後使いませんでした)。
import pickle
result = {
'use_columns':train_df.columns,
'scaler_columns':scaler_columns,
'scaler':scaler,
'model':model
}
with open('/work/models/time_sec_to_strength_model_result', 'wb') as f:
pickle.dump(result, f)また、データ全体に対してモデルを適用すすると次の結果になります。
target_columns = ['place_id', 'race_distance',
'race_type', 'weather', 'race_condition',
'horse_count', 'waku', 'horse_number', 'sex', 'age',
'jocky_weight', 'weight', 'weight_sub',
'time_sec']
Xy = df.loc[:, target_columns]
scalered_Xy = pd.DataFrame(data=scaler.transform(Xy), columns=Xy.columns)
Xy.loc[:, scaler_columns] = scalered_Xy.loc[:, scaler_columns]
y = Xy['time_sec']
X = Xy.drop(columns=['time_sec'])
pred = model.predict(X)
plt.figure(tight_layout=True, figsize=(12, 6))
plt.subplot(121)
plt.scatter(pred, y)
plt.xlabel('pred')
plt.ylabel('y')
plt.subplot(122)
strength = y - pred
plt.hist(strength, bins=100, density=True)
plt.xlim((-0.5, 0.5))
plt.xlabel('strength')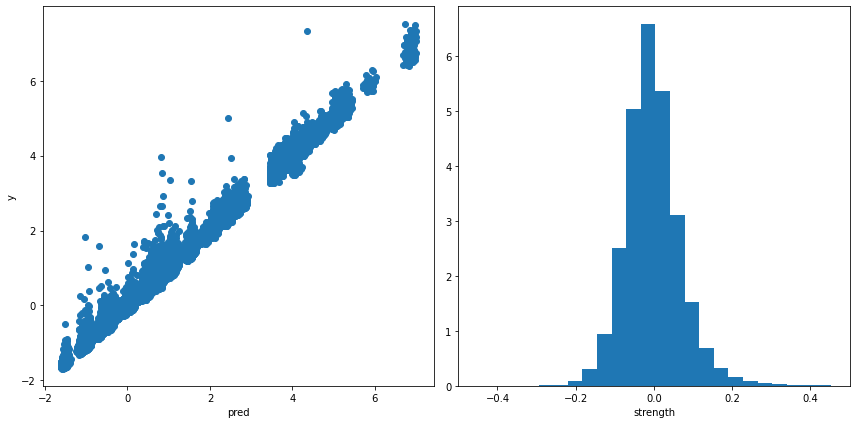
この全体に対して計算した「馬の強さ」データを元のテーブルデータへと追加して保存します。
df['strength'] = strength
df.to_pickle('/work/formatted_source_data/analysis_data01_with_strength.pkl')
dfあとは、この更新されたテーブルデータを元に戦績等のデータを加工していきます。
その他
モデルの変数として、race_total_prize(レースの賞金総額)を入れていませんが、これは意図して行っています。
この変数を入れると、当然モデルの回帰結果はよくなります。
しかし、「レースの賞金総額が高いレースには強い馬が出る」ため、この変数は馬の強さを表す指標でもあるわけです。そのため、この変数の影響を取り除くと、馬の強さから馬の強さを取り除くことになってしまいます。
そうすると、出てきた値は何を表しているのかよくわからなくなってしまうため、意図して入れませんでした。

